sklearn(五)--------交叉验证
一般的训练数据的方法是这样写的:
from sklearn.dadatasets import load_iris
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris=load_iris()
X=iris.data
y=iris.target
X_train,X_test,y_train,y_test=tarin_test_split(X,y,random_state=4)
knn=KNeighborsClassifier(n_neighbors=5)#这里解释一下里面的如果没有东西,就是保持
#模型默认的值,这里我么是把KNN邻近值设为5,具体看机器学习去
knn.fit(X_tarin,y_train)
y_pred=knn.predict(X_test)
print(knn.score(X_test,y_test))
交叉验证:(cross validation)
1:对数据而言:
如果数据太少只训练一次会感觉这个结果是不是靠谱
这时我们如果可以重复利用已有的数据岂不是一件很好的事情(你想的怪美)
我们用的方法就是把原有数据重复划分成训练数据和测试数据,具体如下:

这里我们把数据分为上图这样;分为五部分,先用第一个,在用第二,。。。到第五,然后求平均值。具体代码如下:
from sklearn.dadatasets import load_iris
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris=load_iris()
X=iris.data
y=iris.target
from sklearn.cross_validation import cross_val_score#这个就是重复利用数据的模块
knn=KNeighborsClassifier(n_neighbors=5)
scores=cross_val_score(knn,X,y,cv=5,scoring='accuracy')#把数据自动分成五组,然后得到每组的准确度
print(scores)
结果是:0.96666 1.0 .9333 0.966667 1.0这就是上面五组的准确度
print(scores.mean())这是五组的平均值
结果是:0.973333
2:对模型参数而言:
比如knn里他的近邻个数不一样,对最终的结果肯定有影响,怎么选择好的k值,这就是一个比较重要的额问题:
from sklearn.cross_validation import cross_val_score#这个就是重复利用数据的模块
import matplotlib.pyplot as plt
k_range=range(1,31)#产生一到三十一个数
k_scores=[]#创建一个空的列表
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)
scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')#这里分成十个
k_scores.append(scores.mean())#把每一次的准确率都追加到空列表里
plt.plot(k_range,k_scores)
plt.xlabel('knn li de k')
plt.ylabel('zhunquelv')
plt.show()
结果是: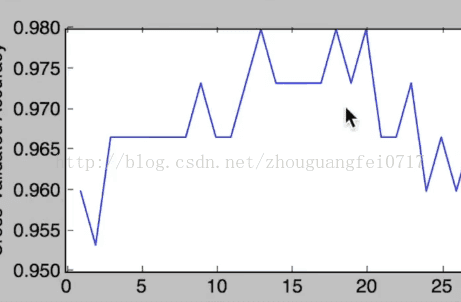
从这张图里可以看到选择K值在10——15的时候准确率比较高,后面的K值越大,准确率越低,这可能是由于overfitting的原因产生的:
3:上面的是对于分类的,对于回归的有一点不一样
scores=cross_val_score(knn,X,y,cv=10,scoring='accuracy')#这是对于分类的
把这个简单变一下就可以了:
loss=-cross_val_score(knn,X,y,cv=10,scoring='mean_squared_error')#这是对于回归的
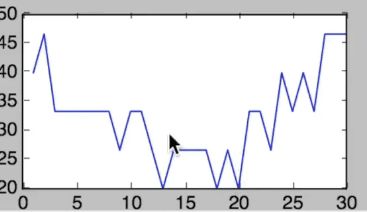
这里这个用的是loss,所以越低模型越好,也是10——15比较好。
未完待续》》》》》》》》》