垃圾邮件识别-朴素贝叶斯算法
1、数据集
垃圾邮件识别使用的数据集为Enron-Spam数据集,该数据集是目前在电子邮件相关研究中使用最多的公开数据集,其邮件数据是安然公司(Enron Corporation, 原是世界上最大的综合性天然气和电力公司之一,在北美地区是头号天然气和电力批发销售商)150位高级管理人员的往来邮件。这些邮件在安然公司接受美国联邦能源监管委员会调查时被其公布到网上。
机器学习领域使用Enron-Spam数据集来研究文档分类、词性标注、垃圾邮件识别等,由于Enron-Spam数据集都是真实环境下的真实邮件,非常具有实际意义。
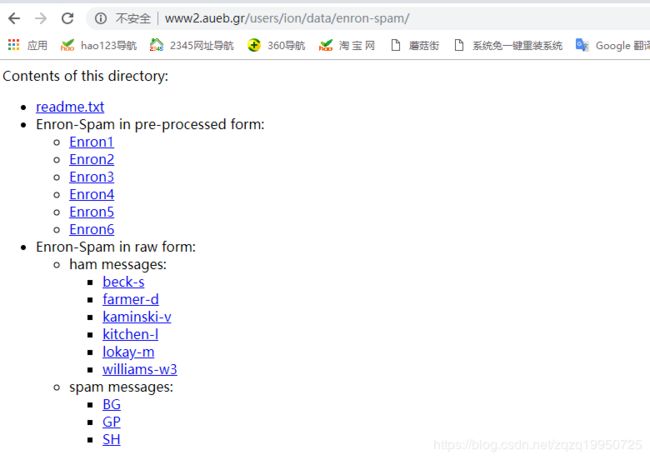
Enron-Spam数据集合如图所示使用不同文件夹区分正常邮件和垃圾邮件。

Enron-Spam数据集对应的网址为:http://www2.aueb.gr/users/ion/data/enron-spam/
2、特征提取
文本特征提取有两个非常重要的模型:
词集模型:单词构成的集合,集合中每个元素都只有一个,也即词集中的每个单词都只有一个
词袋模型:如果一个单词在文档中出现不止一次,并统计其出现的次数(频数)
使用朴素贝叶斯算法,特征提取采用词袋模型。
导入相关的函数库:
>>> from sklearn.feature_extraction.text import CountVectorizer实例化分词对象:
>>> vectorizer = CountVectorizer(min_df=1)
>>> vectorizer
CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None) 将文本进行词袋处理:
>>> corpus=[
... 'This is the first document.',
... 'This is the second second document.',
... 'And the thrid one.',
... 'Is this the first document?',
... ]
>>> X = vectorizer.fit_transform(corpus)
>>> X
<4x9 sparse matrix of type ''
with 19 stored elements in Compressed Sparse Row format> 获取对应的特征名称:
>>> vectorizer.get_feature_names() == (
... ['and', 'document', 'first', 'is', 'one', 'second',
... 'the', 'third', 'this'])
False获取词袋数据,至此,我们已经完成词袋化:
>>> X.toarray()
array([[0, 1, 1, 1, 0, 0, 1, 1, 0],
[0, 1, 0, 1, 0, 2, 1, 1, 0],
[1, 0, 0, 0, 1, 0, 1, 0, 1],
[0, 1, 1, 1, 0, 0, 1, 1, 0]], dtype=int64)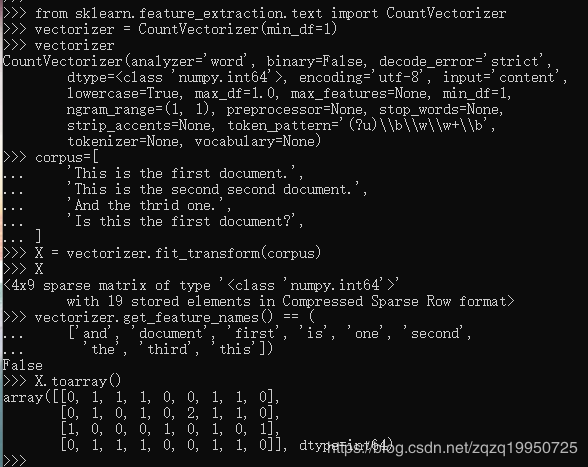
3、朴素贝叶斯算法
流程图:

代码:
# -*- coding: utf-8 -*-
from sklearn.feature_extraction.text import CountVectorizer
from tflearn.layers.normalization import local_response_normalization
import os
import numpy as np
import tensorflow as tf
import tflearn
max_features=5000
max_document_length=100
#将整个邮件当成一个字符串处理,其中回车和换行需要过滤掉
def load_one_file(filename):
x=""
with open(filename,'r',encoding='utf-8',errors='ignore') as f:
for line in f:
line=line.strip('\n')
line=line.strip('\r')
x+=line
return x
#遍历指定文件夹下所有文件,加载数据
def load_files_from_dir(rootdir):
x=[]
list = os.listdir(rootdir)
for i in range(0, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
v=load_one_file(path)
x.append(v)
return x
#加载所在的文件夹,正常邮件在ham中,垃圾邮件在spam中。
def load_all_files():
ham=[]
spam=[]
for i in range(1,2):
#path="../data/mail/enron%d/ham/" % i
#path="C:/Users/Administrator/Downloads/enron%d/ham/" % i
path = "C:/Users/Administrator/PycharmProjects/tensortflow快速入门/tensorflow_study\MNIST_data_bak/enron%d/ham/" % i
print("Load %s" % path)
ham+=load_files_from_dir(path)
#path="../data/mail/enron%d/spam/" % i
#path = "C:/Users/Administrator/Downloads/enron%d/spam/" % i
path = "C:/Users/Administrator/PycharmProjects/tensortflow快速入门/tensorflow_study\MNIST_data_bak/enron%d/spam/" % i
print("Load %s" % path)
spam+=load_files_from_dir(path)
return ham,spam
#使用词袋模型,向量化邮件样本,ham标记为0,spam标记为1
def get_features_by_wordbag():
ham, spam=load_all_files()
x=ham+spam
y=[0]*len(ham)+[1]*len(spam)
vectorizer = CountVectorizer(
decode_error='ignore',
strip_accents='ascii',
max_features=max_features,
stop_words='english',
max_df=1.0,
min_df=1 )
print(vectorizer)
x=vectorizer.fit_transform(x)
x=x.toarray()
return x,y
#构建贝叶斯模型
def do_nb_wordbag(x_train, x_test, y_train, y_test):
print("NB and wordbag")
gnb = GaussianNB()
gnb.fit(x_train,y_train)
y_pred=gnb.predict(x_test)
print(metrics.accuracy_score(y_test, y_pred))
print(metrics.confusion_matrix(y_test, y_pred))
if __name__ == "__main__":
print("Hello spam-mail")
print("get_features_by_wordbag")
x,y=get_features_by_wordbag()
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.4, random_state = 0) #测试集比例为40%
do_nb_wordbag(x_train, x_test, y_train, y_test)完整输出结果:
Hello spam-mail
get_features_by_wordbag
Load C:/Users/Administrator/PycharmProjects/tensortflow快速入门/tensorflow_study\MNIST_data_bak/enron1/ham/
Load C:/Users/Administrator/PycharmProjects/tensortflow快速入门/tensorflow_study\MNIST_data_bak/enron1/spam/
CountVectorizer(analyzer='word', binary=False, decode_error='ignore',
dtype=, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=5000, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words='english',
strip_accents='ascii', token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
NB and wordbag
0.9545674238762687
[[1405 58]
[ 36 570]]
在词袋最大特征数为5000的情况下,整个系统的准确度为95.46%,评价结果准确度如下表所示:
| 类型名称 | 相关 | 不相关 |
| 检索到 | 1405 | 58 |
| 未检索到 | 36 | 570 |