SP-Cache: 基于选择性热点数据分割策略,实现分布式内存系统负载均衡
编者按:在Alluxio开源社区,越来越多高校研究人员使用Alluxio作为研究载体。本博客将介绍一系列基于Alluxio的前沿研究工作。该系列的第一篇博客邀请到了香港科技大学于英豪博士撰写介绍了他基于Alluxio的研究成果。本文不仅有技术介绍,还会分享他在开源软件上开展研究的心得与经验。
常用链接
Alluxio项目官网
Alluxio Inc网站
Alluxio在各大厂用例
关注Alluxio微信公众号:Alluxio_China
随着现代数据中心网络的大幅提速,传统的HDFS提供的基于硬盘存储的数据本地性变得越来越不重要 (文献1)。而同时对象存储(Object Store,包括Amazon S3 和 OpenStack Swift等)作为更便宜和更容易水平扩展的数据存储层系统,在广泛发展的众多大数据应用中越来越受到欢迎。由于硬盘的I/O速度仍远低于内存读写,因此在大数据应用和对象存储之间部署一个以Alluxio为代表的内存文件缓存层来缓存数据,可以有效提升整体的读写效率,并弥补网络带宽受限场景下存储与计算分离带来的数据本地性问题。为了进一步提升内存缓存层的整体性能,本文揭示了内存缓存层中由于文件热度不均导致的负载失衡的严重风险,并提出了一种选择性热点文件分割的策略来保障系统负载均衡。
负载均衡
研究表明,数据中心里不同数据的访问有显著的热度差异。当这些数据被缓存在内存层中时,极容易产生负载失衡的问题:一部分数据被高频率地访问,形成局部热点(hot spot)。热点机器的网络拥塞往往会成为数据读写的瓶颈;而另一部分访问频率较低的数据因为占用缓存资源,导致资源不能更加优化地分配给热点数据,进而影响内存资源的使用效率。
图1:分布式内存系统负载失衡
为了深度观察负载失衡在生产环境中的严重程度,我们分析了Yahoo! 公开的一个生产集群的trace(文献2)。在这个涉及上千台机器、跨度数月的数据访问日志中,我们统计了涵盖其中数百万文件的读写频率及其文件大小。我们有两个发现,总结如下图。

图2:Yahoo! trace的统计
- 数据热度的差异性十分显著。图2中的蓝色柱子显示了文件访问频次的分布,我们发现只有2%的文件被频繁的访问(总次数超过100次),而77%的文件则是冷数据(访问次数少于10次)。
- 热点数据往往是大文件。图2中的黄色柱子显示了不同热度区间文件的平均大小。例如,访问次数超过100次的文件,平均大小是729MB,将近二十倍于“冷文件”的平均大小。
以上两点实际情况给系统造成了严重的负载失衡风险:存储热点文件的机器将被频繁地访问,且每次访问都需要传输大量的数据(大文件),造成网络拥塞,使得读写速度变慢。因此,负载均衡是影响分布式内存系统性能的关键要素。
现有策略的问题
现有的用于实现内存系统负载均衡的算法大致可分为两类。
- 多副本热点文件,例如Alluxio1.x版本中提供的被动复制机制,以及选择性地主动复制热数据(selectivereplication,文献3)。通过多份副本分流,实现均衡负载。
- 使用纠删码(erasure coding,文献4)将大文件编码为若干小数据块(包括信息块和校验块),并将它们存储于不同的机器上。对大文件的读取任务将被分流到这些小数据块中,实现负载均衡。
然而,我们发现现有的这两类算法都不能有效地解决实际问题。一方面,复制热点文件(往往是大文件)会造成大量的内存冗余,使内存的整体命中率降低,进而降低读写速度;另一方面,若使用纠删码,每次文件的读/写都需要解码/编码操作,拖慢对内存的读写速度并增加CPU的负担(经我们测量,解码时间可占总的读文件时间的30%)。
选择性分割
为了减少内存的冗余,同时避免编解码的计算负担,我们设计了一种选择性文件分割的算法来实现负载均衡。
文件分割
文件分割的基本思路是将大的热点文件分割成小块(仅分割,无编码),然后将这些小块均匀分散存储在集群中。图3显示的这个示例中,文件A 是一个热点文件;它被分割为四个小块,放在四台机器上。这样做有三个好处。
- 热点文件的负载被分流至多台机器,可以均衡负载,同时利用并行I/O可以降低读延迟;
- 无需任何编解码操作;
- 没有任何内存冗余。

图3:文件分割示例
但是,文件并不合适被无限地分割成任意粒度的小块,其中一个重要的原因是straggler(拖后腿者)节点的存在。我们将集群当前状态下响应慢的机器称为straggler,它们的产生原因非常复杂且是动态变化的(文献5)。文件被分割后,由于每次文件读取需要并发地读所有的小块,总的读延迟受限于最慢获取到的小块。因此,一旦有任何一台存放小块的机器是straggler,文件读取就会被拖慢。由于straggler的发生难以提前预知和控制,我们只能尽可能降低分割算法被straggler影响的概率,即去控制分割小块的数目。为此,我们提出了选择性文件分割算法。
选择性文件分割
顾名思义,选择性文件分割就是优先选择内存中被频繁访问的、大的热点文件进行分割,而尽量减少对小文件、冷文件的分割。这样,一方面热点文件可以被充分分割而达到均衡负载的目的,另一方面straggler的影响被尽可能地降低了。
为了找到每个文件各自的最佳分割数量,我们将整个分布式内存系统简化为一个fork-join queue模型。在这个模型中,每一个文件读请求被分叉(fork)为多个子任务,分发至储存了该文件分割小块的内存节点,最终所有的子任务的读取结果被合并(join)为原文件,返回至文件请求源。我们将测量、估计出来的文件大小、被访问频率等信息加入模型后,计算出每个文件的最佳分割数量,使得热点文件的负载可以恰好被充分分散,同时straggler的影响被尽可能限制。

图4:fork-join queue 模型
性能测试
我们在Alluxio中实现了选择性文件分割的算法(SP-Cache),并同其他两种现有算法,选择性文件复制(selective replication)和纠删码(EC-Cache),进行了性能比较。
- 图5展示了采用三种不同负载均衡算法后,一个30节点的Alluxio集群中每个节点的负载。可以看出,选择性文件分割(SP-Cache)均衡负载的效果最佳,节点之间的负载差别最小。
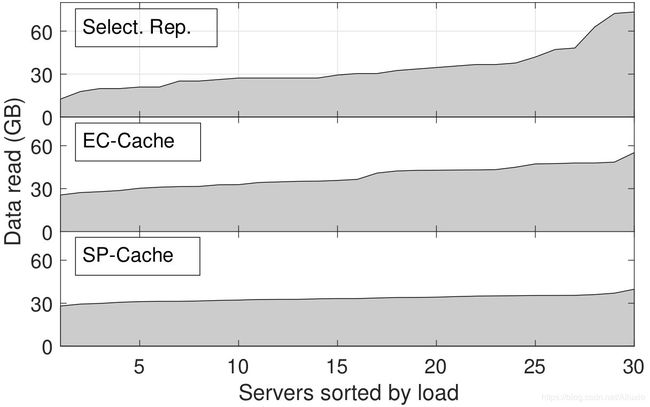
图5:三种算法负载均衡效果的比较
- 由于选择性文件分割算法没有任何内存冗余以及编解码的时间开销,相比其他负载均衡算法,可以大幅降低读延迟。如图6所示,与复制算法(以及纠删码算法)相比,选择性文件分割算法可以降低平均读延迟29 − 50% (40 −70%),降低尾部读延迟(95 百分位)22 − 55% (33 − 60%)。

图6:三种算法读延迟比较
经验分享
最后,我们分享总结一些在Alluxio上开展科研项目的工程经验。 得益于Alluxio开源项目成熟的模块化设计,我们在开发实现我们的算法的过程中,能够在原版本Alluxio的框架和结构不变的基础之上,仅对几个可插拔的模块进行集中改动。具体而言,在原版本Alluxio的基础上,我们主要实现了三个模块。
-
在Alluxio master中实现一个SP-Master模块,负责管理所有与选择性分割算法有关的元数据,例如每个文件有几个分割数,每个分割小块分别存在哪些Alluxio worker上等;同时,SP-Master会根据过去一段时间的文件访问热度,定期计算并更新每个文件的最优分割值;
-
在原来的Alluxio client之外封装一个SP-Client。来自上层应用的文件读写请求会先经过SP-Client。例如,对于读请求,SP-Client先向SP-Master查询被访问文件各个分割小块所在的worker地址,然后再通过Alluxio client 读取所有小块,最后由SP-Client将读来的数据按照相对顺序结合为原来的文件,返回上层应用;
-
由于在很多现实应用中文件的访问热度会随着时间而改变,因此我们实现了一个定期重新分割文件的模块SP-Repartitioner。在每个分割周期到来时,SP-Repartitioner会首先向SP-Master查询更新后的文件最优分割值,然后在多个Alluxio worker上并行地对内存中的文件进行重分割。
Alluxio的源代码结构组织合理并且实现思路清晰,这有助于我们快速锁定需要修改的模块,以及我们自己实现的模块应该如何添加到Alluxio源码结构中,例如,SP-Master需要在Alluxio master被初始化时即被创建,因此我们把它放在alluxio.master.file这个package中; 而SP-Client是一个独立的package, 只是在其中调用了部分Alluxio client的接口;另外,关于SP-Master和SP-Client之间的通信,我们可以直接借助Alluxio原有的thrift框架创建所需要的通信接口。
总地来说,我们的经验是,在Alluxio平台上开展科研项目,第一步要弄清楚源代码中每一个模块的功能是什么,对Alluxio源代码本身有全局的了解,然后再根据自己的需求去精读、修改对应的模块,这样可以节省不少看代码的时间;另外一个建议,研究者最好将自己的改动设计成可插拔的子模块,这样可以方便源码维护并与原版本的Alluxio进行性能对比。
本文作者:余英豪
作者简介:香港科技大学电子与计算机工程系博士研究生,专注于分布式内存系统的性能优化
导师:王威教授,Khaled Ben Letaief教授
特别鸣谢:感谢Alluxio PMC范斌博士以及南京大学顾荣老师的校阅、指正