用WEKA进行数据挖掘,第3部分:最近邻和服务器端库
简介
在这个 “用 WEKA 进行数据挖掘” 系列之前的两篇文章中,我介绍了数据挖掘的概念。如果您还未曾阅读过 用 WEKA 进行数据挖掘,第 1 部分:简介和回归 和 用 WEKA 进行数据挖掘,第 2 部分:分类和群集,那么请先阅读这两个部分,因为二者涵盖了一些在继续之前必须了解的关键概念。而且更重要的是,在这两个部分中我谈及了数据挖掘中常用的三种技术,它们可以将难以理解的无用数据转变为有意义的规则和趋势。第一种技术是回归,用来基于其他的示例数据预测一个数值输出(比如房屋价值)。第二种技术是分类(即分类树或决策树),用来创建一个实际的分支树来预测某个未知数据点的输出值。(在我们的例子中,我们预测的是对 BMW 促销活动的反应。)我介绍的第三种技术是群集,可用它来创建数据组(群集)并从中识别出趋势和其他规则(在我们的例子中,即 BMW 的销售)。三者的相似点在于它们都能将数据转换成有用信息,但它们各自的实现方法以及使用的数据各不相同,而这正是数据挖掘最为重要的一点:正确的模型必须用于正确的数据。
本文将讨论四种常用的数据挖掘技术中的最后一种:最近邻。您将看到它更像是分类与群集的组合,并为我们消灭数据误导的使命提供了另一种有用的武器。
在我们之前的文章中,我们将 WEKA 用作一种独立的应用程序。那么它在实际中能多有用呢?很显然,它并不完美。由于 WEKA 是一种基于 Java 的应用程序,它有一个可被用在我们自己的服务器端代码中的 Java 库。对于大多数人而言,这可能是最为常见的用法,因为您可以编写代码来不断地分析您的数据并动态地做出调整,而不必依赖他人提取数据、将其转换成 WEKA 格式,然后再在 WEKA Explorer 内运行它。
最近邻
最近邻(也即 Collaborative Filtering 或 Instance-based Learning)是一种非常有用的数据挖掘技术,可用来用输出值已知的以前的数据实例来预测一个新数据实例的未知输出值。从目前的这种描述看来,最近邻非常类似于回归和分类。那么它与这二者究竟有何不同呢?首先,回归只能用于数值输出,这是它与最近邻的最直接的一个不同点。分类,如我们在前一篇文章的例子中看到的,使用每个数据实例 来创建树,我们需要遍历此树才能找到答案。而这一点对于某些数据而言会是一个很严重的问题。举个例子,亚马逊这样的公司常常使用 “购买了 X 的顾客还购买了 Y" 特性,如果亚马逊拟创建一个分类树,那么它将需要多少分支和节点?它的产品多达数十万。这个树将有多巨大呀?如此巨大的一个树能有多精确呢?即便是单个分支,您都将会惊讶地发现它只有三个产品。亚马逊的页面通常会有 12 种产品推荐给您。对于这类数据,分类树是一种极不适合的数据挖掘模型。
而最近邻则可以非常有效地解决所有这些问题,尤其是在上述亚马逊的例子中遇到的这些问题。它不会受限于数量。它的伸缩性对于 20 个顾客的数据库与对于 2000 万个顾客的数据库没有什么差异,并且您可以定义您想要得到的结果数。看起来是一个很棒的技术!它的确很棒 — 并且可能对于那些正在阅读本文的电子商务店铺的店主最为有用。
让我们先来探究一下最近邻背后的数学理论,以便能更好地理解这个过程并了解此技术的某些限制。
最近邻背后的数学理论
最近邻技术背后的数学理论非常类似于群集技术所涉及到的数学理论。对于一个未知的数据点,这个未知数据点与每个已知数据点之间的距离需要被计算出来。如果用电子数据表计算此距离将会非常繁琐,而一个高性能的计算机则可以立即完成这些计算。最容易也是最为常见的一种距离计算方式是 “Normalized Euclidian Distance”。它看起来复杂,实则不然。让我们通过一个例子来弄清楚第 5 个顾客有可能会购买什么产品?
清单 1. 最近邻的数学理论
Customer Age Income Purchased Product 1 45 46k Book 2 39 100k TV 3 35 38k DVD 4 69 150k Car Cover 5 58 51k ??? Step 1: Determine Distance Formula Distance = SQRT( ((58 - Age)/(69-35))^2) + ((51000 - Income)/(150000-38000))^2 ) Step 2: Calculate the Score Customer Score Purchased Product 1 .385 Book 2 .710 TV 3 .686 DVD 4 .941 Car Cover 5 0.0 ??? |
如果使用最近邻算法回答我们上面遇到的 “第 5 个顾客最有可能购买什么产品” 这一问题,答案将是一本书。这是因为第 5 个顾客与第 1 个顾客之间的距离要比第 5 个顾客与其他任何顾客之间的距离都短(实际上是短很多)。基于这个模型,可以得出这样的结论:由最像第 5 个顾客的顾客可以预测出第 5 个顾客的行为。
不过,最近邻的好处远不止于此。最近邻算法可被扩展成不仅仅限于一个最近匹配,而是可以包括任意数量的最近匹配。可将这些最近匹配称为是 “N-最近邻”(比如 3-最近邻)。回到上述的例子,如果我们想要知道第 5 个顾客最有可能购买的产品,那么这次的结论是书和 DVD。而对于上述的亚马逊的例子,如果想要知道某个顾客最有可能购买的 12 个产品,就可以运行一个 12-最近邻算法(但亚马逊实际运行的算法要远比一个简单的 12-最近邻算法复杂)。
并且,此算法不只限于预测顾客购买哪个产品。它还可被用来预测一个 Yes/No 的输出值。考虑上述例子,如果我们将最后一列改为(从顾客 1 到 顾客 4)“Yes,No,Yes,No,”,那么用 1-最近邻模型可以预测第 5 个顾客会说 “Yes”,如果用一个 2-最近邻算法也会得到预测结果 “Yes”(顾客 1 和 3 均说 “Yes”),若用 3-最近邻模型仍会得到 “Yes”(顾客 1 和 3 说 “Yes”,顾客 2 说 “No”,所以它们的平均值是 “Yes”)。
我们考虑的最后一个问题是 “我们应该在我们的模型中使用多少邻?” 啊哈 — 并不是每件事都这么简单。为了确定所需邻的最佳数量,需要进行试验。并且,如果要预测值为 0 和 1 的列的输出,很显然需要选择奇数个邻,以便打破平局。
针对 WEKA 的数据集
我们将要为我们的最近邻示例使用的数据集应该看起来非常熟悉 — 这个数据集就与我们在上一篇文章的分类示例中所用的相同。该示例关于的是一个虚构的 BMW 经销店及其向老客户销售两年延保的促销活动。为了回顾这个数据集,如下列出了我在上一篇文章中曾介绍过的一些指标。
延保的以往销售记录中有 4,500 个数据点。数据集中的属性有:收入水平 [0=$0-$30k, 1=$31k-$40k, 2=$41k-$60k, 3=$61k-$75k, 4=$76k-$100k, 5=$101k-$150k, 6=$151k-$500k, 7=$501k+]、顾客首辆 BMW 购买的年/月、最近一辆 BMW 购买的年/月、顾客是否在过去对延保的促销有过响应。
清单 2. 最近邻 WEKA 数据
@attribute IncomeBracket {0,1,2,3,4,5,6,7}
@attribute FirstPurchase numeric
@attribute LastPurchase numeric
@attribute responded {1,0}
@data
4,200210,200601,0
5,200301,200601,1
... |
WEKA 内的最近邻
我们为何要使用与分类例子中相同的数据集呢?这是因为分类模型得到的结果,只有 59 % 的准确率,而这完全不能接受(比猜想好不到哪去)。我们将提高准确率并为这个虚构的经销商提供一些有用的信息。
将数据文件 bmw-training.arff 载入 WEKA,步骤与我们之前在 Preprocess 选项卡中使用的相同。加载数据后,屏幕应该类似于图 1。
图 1. WEKA 内的 BMW 最近邻数据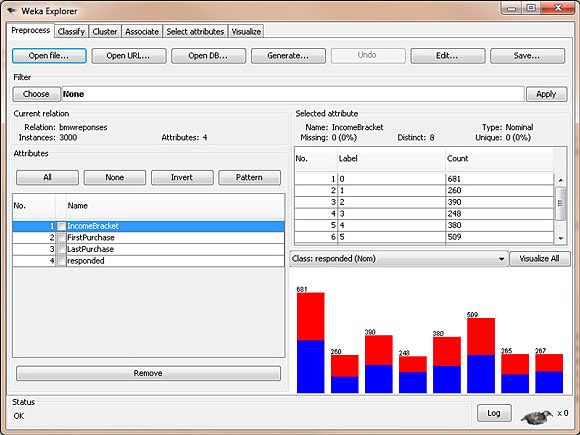
与我们在之前文章的回归和分类模型中所做的类似,我们接下来应该选择 Classify 选项卡。在这个选项卡上,我们应该选择 lazy,然后选择 IBk(IB 代表的是 Instance-Based,而 k 则允许我们指定要使用的邻的数量)。
图 2. BMW 最近邻算法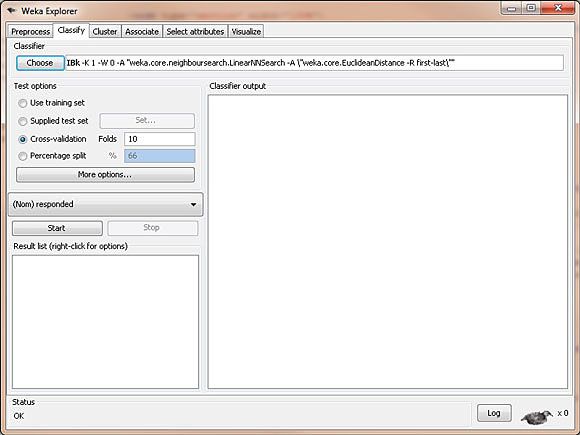
现在,我们就准备好可以在 WEKA 内创建我们的模型了。请确保选中 Use training set 以便我们使用刚载入的这个数据集来创建我们的模型。 单击 Start,让 WEKA 运行。图 3 显示了一个屏幕快照,清单 3 则包含了此模型的输出。
图 3. BMW 最近邻模型
清单 3. IBk 计算的输出
=== Evaluation on training set ===
=== Summary ===
Correctly Classified Instances 2663 88.7667 %
Incorrectly Classified Instances 337 11.2333 %
Kappa statistic 0.7748
Mean absolute error 0.1326
Root mean squared error 0.2573
Relative absolute error 26.522 %
Root relative squared error 51.462 %
Total Number of Instances 3000
=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.95 0.177 0.847 0.95 0.896 0.972 1
0.823 0.05 0.941 0.823 0.878 0.972 0
Weighted Avg. 0.888 0.114 0.893 0.888 0.887 0.972
=== Confusion Matrix ===
a b <-- classified as
1449 76 | a = 1
261 1214 | b = 0 |
上述结果与我们用分类创建模型时的结果有何差异呢?使用最近邻的这个模型的准确率为 89 %,而分类模型的准确率只有 59 %,所以这绝对是一个很好的开始。接近 90 % 的准确率是非常可以接受的。让我们再进一步来分析这些结果的假正和假负的情况,以便深入了解来自 WEKA 的这些结果在实际业务中的适用。
此模型的结果显示我们有 76 个假正(2.5 %),有 261 个假负(8.7 %)。请记住在本例中一个假正意味着我们的模型预测该客户会购买延保而实际上却未购买,而一个假负则意味着我们的模型预测客户不会购买延保而实际却购买了。让我们估测经销商的宣传单的派发成本是每个传单 $3,延保为经销商带来了 $400 的利润。这个模型对经销商的成本/收益的预测应为 $400 - (2.5% * $3) - (8.7% * 400) = $365。所以,从此模型看来,这个经销商相当有利可图。与之相比,使用分类模型预测的成本/收益只有 $400 - (17.2% * $3) - (23.7% * $400) = $304,由此可以看出使用正确的模型可以为此经销商提供 20 % 潜在收入的提高。
您可以自己练习着在这个模型中尝试不同数量的最近邻(您可以右键单击下一个 “IBk -K 1....”,就会看到一列参数)。可以任意更改 "KNN"(K-最近邻)。在本例中您将会看到随着加入更多的邻,模型的准确率实际上却降低了。
此模型的一些不尽人意之处:当我们谈论像亚马逊这样的数据集时,最近邻的强大威力是显而易见的。对于有 2000 万用户的亚马逊,此算法非常准确,因为在亚马逊的数据库中与您有着类似购买习惯的潜在客户很多。您的最近邻会非常相似。因而,所创建的模型会十分准确和高效。相反,如果能比较的数据点相对很少的话,这个模型很快就会损坏,不再准确。在在线电子商务店铺的初期,比如只有 50 个顾客,那么产品推荐特性很可能一点都不准确,因为最近邻实际上与您本身相差甚远。
最近邻技术最后的一个挑战是该算法的计算成本有可能会很高。在亚马逊的例子中,对于它的 2000 万客户,每个客户都必须针对其他的 2000 万客户进行计算以便找到最近邻。首先,如果您的业务也有 2000 万的客户群,那么这便不成问题,因为您会财源广进。其次,这种类型的计算非常适合用云来完成,因为它们能够被分散到许多计算机上同时完成,并最终完成比较。(比如,Google 的 MapReduce。)第三,实际上,如果我只是购买了一本书,那么根本不必针对我对比亚马逊数据库内的每个 客户。只需将我与其他的购书者进行对比来寻找最佳匹配,这样一来,就将潜在的邻缩小到整个数据库的一部分。
请记住:数据挖掘模型并不只是简单的输入-输出机制 — 必须先对数据进行检查以决定该选择哪种正确的模型,让输入能够设法减少计算时间,而输出则必须被分析且要确保准确后才能据此做出整体的判断。
进一步的阅读:如果您有兴趣进一步学习最近邻算法,可以按如下术语搜索相关信息:distance weighting、Hamming distance、Mahalanobis distance。
在服务器上使用 WEKA
有关 WEKA 最酷的一件事情是它不仅是一个独立的应用程序,而且还是一个完备的 Java JAR 文件,可以将其投入到您服务器的 lib 文件夹并从您自己的服务器端代码进行调用。这能为您的应用程序带来很多有趣的、和重要的功能。您可以添加充分利用了我们到目前所学的全部数据挖掘技术的报告。您可以为您的电子商务店铺创建一个“产品推荐”小部件,类似于亚马逊站点上的那个(由于根本不可能为每个顾客都按需这么做,因此需要贯彻这个独立的应用程序运行它)。WEKA 独立应用程序本身只调用底层的 WEKA Java API,所以您应该已经看到过这个 API 的运转了。现在,我们应该看看如何将它集成到您的自己代码中。
实际上,您已经下载了这个 WEKA API JAR;它就是您启动 WEKA Explorer 时调用的那个 JAR 文件。为了访问此代码,让您的 Java 环境在此类路径中包含这个 JAR 文件。在您自己的代码中使用第三方 JAR 文件的步骤如常。
正如您所想,WEKA API 内的这个中心构建块就是数据。数据挖掘围绕此数据进行,当然所有我们已经学习过的这些算法也都是围绕此数据的。那么让我们看看如何将我们的数据转换成 WEKA API 可以使用的格式。让我们从简单的开始,先来看看本系列有关房子价值的第一篇文章中的那些数据。
注: 我最好提前告诫您 WEKA API 有时很难导航。首要的是要复核所用的 WEKA 的版本和 API 的版本。此 API 在不同的发布版间变化会很大,以至于代码可能会完全不同。而且,即便此 API 完备,却没有什么非常好的例子可以帮助我们开始(当然了,这也是为什么您在阅读本文的原因)。我使用的是 WEKA V3.6。
清单 4 显示了如何格式化数据以便为 WEKA 所用。
清单 4. 将数据载入 WEKA
// Define each attribute (or column), and give it a numerical column number
// Likely, a better design wouldn't require the column number, but
// would instead get it from the index in the container
Attribute a1 = new Attribute("houseSize", 0);
Attribute a2 = new Attribute("lotSize", 1);
Attribute a3 = new Attribute("bedrooms", 2);
Attribute a4 = new Attribute("granite", 3);
Attribute a5 = new Attribute("bathroom", 4);
Attribute a6 = new Attribute("sellingPrice", 5);
// Each element must be added to a FastVector, a custom
// container used in this version of Weka.
// Later versions of Weka corrected this mistake by only
// using an ArrayList
FastVector attrs = new FastVector();
attrs.addElement(a1);
attrs.addElement(a2);
attrs.addElement(a3);
attrs.addElement(a4);
attrs.addElement(a5);
attrs.addElement(a6);
// Each data instance needs to create an Instance class
// The constructor requires the number of columns that
// will be defined. In this case, this is a good design,
// since you can pass in empty values where they exist.
Instance i1 = new Instance(6);
i1.setValue(a1, 3529);
i1.setValue(a2, 9191);
i1.setValue(a3, 6);
i1.setValue(a4, 0);
i1.setValue(a5, 0);
i1.setValue(a6, 205000);
....
// Each Instance has to be added to a larger container, the
// Instances class. In the constructor for this class, you
// must give it a name, pass along the Attributes that
// are used in the data set, and the number of
// Instance objects to be added. Again, probably not ideal design
// to require the number of objects to be added in the constructor,
// especially since you can specify 0 here, and then add Instance
// objects, and it will return the correct value later (so in
// other words, you should just pass in '0' here)
Instances dataset = new Instances("housePrices", attrs, 7);
dataset.add(i1);
dataset.add(i2);
dataset.add(i3);
dataset.add(i4);
dataset.add(i5);
dataset.add(i6);
dataset.add(i7);
// In the Instances class, we need to set the column that is
// the output (aka the dependent variable). You should remember
// that some data mining methods are used to predict an output
// variable, and regression is one of them.
dataset.setClassIndex(dataset.numAttributes() - 1); |
现在我们已经将数据载入了 WEKA。虽然比想象中的要稍微难一点,但您可以看到编写自己的包装器类来快速从数据库提取数据并将其放入一个 WEKA 实例类还是很简单和有益的。实际上,我强烈建议如果打算在服务器上使用 WEKA,那么就不要怕花时间,因为以这种方式处理数据是很繁琐的。一旦将数据放入了这个实例对象,您就可以在数据上进行任何您想要的数据挖掘了,所以您想要这个步骤尽可能地简单。
让我们把我们的数据通过回归模型进行处理并确保输出与我们使用 Weka Explorer 计算得到的输出相匹配。实际上使用 WEKA API 让数据通过回归模型得到处理非常简单,远简单于实际加载数据。
清单 5. 在 WEKA 内创建回归模型
// Create the LinearRegression model, which is the data mining
// model we're using in this example
LinearRegression linearRegression = new LinearRegression();
// This method does the "magic", and will compute the regression
// model. It takes the entire dataset we've defined to this point
// When this method completes, all our "data mining" will be complete
// and it is up to you to get information from the results
linearRegression.buildClassifier(dataset);
// We are most interested in the computed coefficients in our model,
// since those will be used to compute the output values from an
// unknown data instance.
double[] coef = linearRegression.coefficients();
// Using the values from my house (from the first article), we
// plug in the values and multiply them by the coefficients
// that the regression model created. Note that we skipped
// coefficient[5] as that is 0, because it was the output
// variable from our training data
double myHouseValue = (coef[0] * 3198) +
(coef[1] * 9669) +
(coef[2] * 5) +
(coef[3] * 3) +
(coef[4] * 1) +
coef[6];
System.out.println(myHouseValue);
// outputs 219328.35717359098
// which matches the output from the earlier article |
大功告成!运行分类、群集或最近邻都不如回归模型简单,但它们也没有那么困难。运行数据挖掘模型要比将数据载入模型简单得多。
我们希望这一小节能够让您产生将 WEKA 集成到您自己的服务器端代码的兴趣。不管您是运营一个电子商务的店铺并想为客户提供更好的产品推荐,还是您有一个礼券促销活动需要加以改善,抑或是您想要优化您的 AdWords 活动,又或者是您想要优化您的着陆页,这些数据挖掘技术都能帮助您在这些领域改善您的结果。比如,借助于 WEKA API 的内置特性,您就可以编写服务器端代码来轮换您的着陆页并使用数据挖掘不断地分析结果以找到最为有效的着陆页。通过在 AdWords 上综合它与数据挖掘分析,您就可以快速找到最佳的途径来将客户吸引到您的站点并将客户的到访变为销售。
结束语
本文是由三篇文章组成的系列文章的终结篇,该系列向您介绍了数据挖掘的概念尤其是 WEKA 软件。正如您所见,WEKA 可以完成很多在商业软件包中才能完成的数据挖掘任务。WEKA 功能强大且 100 % 免费。像这样的好事绝无仅有,因为您可以迅速启动 WEKA 并即刻就开始处理您的数据。
本文探究了第四种常见的数据挖掘算法,“最近邻”。这种算法非常适合于寻找接近于一个未知数据点的那些数据点并使用来自这些值的已知输出来预测未知输出。我向您展示了这种数据挖掘为何对在线购物网站上的推荐产品功能非常理想。通过一些数据挖掘,像亚马逊这样的站点可以快速(对于这类站点是最起码的,因为有数千台计算机)告诉您与您类似的其他顾客购买的东西。
本文的最后一节显示了您不应该将自己限制于只使用 WEKA 与 Explorer 窗口作为一个独立的应用程序。WEKA 还能被用作一个独立的 Java 库,您可以将其放入到您服务器端的环境内并像其他 Java 库那样调用它的 API。我向您展示了您如何能将数据载入此 WEKA API(并且建议您花些时间围绕您的数据库编写一个漂亮的包装程序以便让这个过于复杂的过程简单一些)。最后,我向您展示了创建一个回归模型并从获自此独立应用程序的这个 API 获得相同的结果是多么地容易。
我对使用此 API 的最后一点建议是通读相关文档并花些时间来阅读所提供的全部可用函数。我发现这个 API 多少有点难以使用,所以如果事先仔细地研读就能顺利地使用它,而不至于最终将它扔入回收站。
希望,在阅读完本系列后,您能跃跃欲试地下载 WEKA 并尝试从您自己的数据中找到模式和规则。
下载
| 描述 | 名字 | 大小 | 下载方法 |
|---|---|---|---|
| 经销商信息和 Java 代码 | os-weka3-Examples.zip | 17KB | HTTP |
关于下载方法的信息