工作中涉及的有用的SQL表达式
这篇文章主要记录自己工作大半年来经常涉及的SQL表达式,以下SQL语句仅适用于MySQL!
一、和日期相关的SQL表达式
工作中用到的数据表,有很多字段都和时间有关,而且基本上所有的时间字段格式都是:“yyyy-MM-dd HH:mm:ss“。对此,我经常会对时间进行以下几种操作:
-
时间格式函数 :
(1)DATE_FORMAT(xx,‘yyyy-MM-dd’)
例:select DATE_FORMAT(‘1970-01-01 00:00:00’,‘yyyy-MM’)
结果为:‘1970-01-01’
类似的还有:DATE_FORMAT(xx,‘yyyy-MM’)、DATE_FORMAT(xx,‘yyyy’)
(2)year(xx):取时间中的年份
例:select year(‘1970-01-01 00:00:00’)
结果为:‘1970’
(3)month(xx):取时间中的月份
例:select month(‘1970-01-01 00:00:00’)
结果为:‘1’
(4)date(xx):取时间中的日期
例:select date(‘1970-01-01 00:00:00’)
结果为:‘1970-01-01’ -
日期加减函数 :
(1)date_add(xx,interval n day)——加上n天
例:select date_add(‘1970-01-01’,interval 10 day)
结果为:‘1970-01-11’
类似的还有:date_add(xx,interval n hour)、date_add(xx,interval n week)、date_add(xx,interval n month)、date_add(xx,interval n quarter)、date_add(xx,interval n year)
(2)date_sub(xx,interval n day)——减去n天
例:select date_sub(‘1970-01-11’,interval 10 day)
结果为:‘1970-01-01’
(3)datediff(date1,date2)——date1和date2两日期相减后的天数
例:select datediff(‘1970-01-11’,‘1970-01-01’)
结果为:10
datediff这个函数因为可以用来计算两个日期的相差天数,因此在工作中经常用来计算用户的活跃日期(or 交易日期)与注册日期的差值,从而计算用户的流失率、留存率、转化率等指标。
二、模糊查询
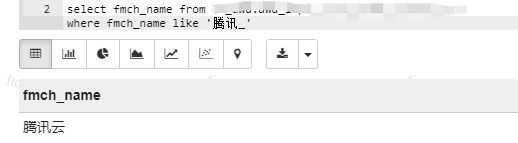
1.like搭配%或者_ :like是常用的模糊匹配关键字,其中,%代表一个或多个字符的通配符,_仅仅代表一个字符的通配符;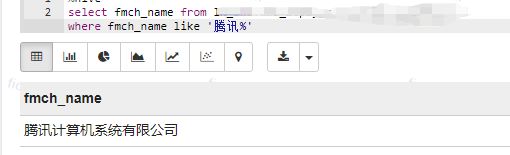
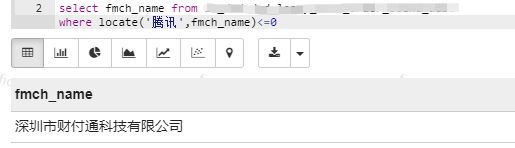
2.locate(substr,str) :这个函数是工作中更常用的模糊匹配函数,返回子串substr第一次出现在字符串str的位置,若substr没有出现在str中,则返回0;

三、排序函数
1.rank :有相同序号,会跳跃,比如:1,1,3,4,……
2.dense_rank:有相同序号,连续,比如:1,1,2,3,4,……
3.**row_number()over(PARTITION by 分组字段 order by 排序字段) ** :序号不同且连续,比如:1,2,3,4,……
三个函数用法类似,参考文档:https://www.cnblogs.com/52XF/p/4209211.html
工作中最常用的函数是row_number() 这个排序函数,比如:在一张交易表里,一个用户有多次交易,一次交易在表里有一条记录,我们想取用户首次完成交易的记录,此时就可以用到这个SQL,SQL代码如下:
// 查询用户首次完成交易的记录
select * from(
select *,
row_number() over(partition by user_id order by transe_date) as rank
from transe_table) t
where rank=1
四、聚合函数
sum,count,max,min,avg这些聚合函数在工作中会经常用到,大家对它应该也很熟悉。但是,在工作中,这些聚合函数,也可以和row_number()函数一样,配合**over(PARTITION by 分组字段 order by 排序字段)**进行在指定分组字段内聚合,这里用一段SQL来解释说明:
// 按照指定的分组字段进行内部聚合
select user_id,
order_id,
sum(transe_amount) over (partition by fuid) as amount1,--按用户汇总各个用户的交易金额
max(transe_amount) over(partition by fuid) as amount2, --获取每个用户的最大一笔交易金额
min(transe_amount) over(partition by fuid) as amount2, --获取每个用户的最小一笔交易金额
avg(transe_amount) over(partition by fuid) as amount2, --获取每个用户的平均交易金额
from transe_table
五、字符串函数
- 从左开始截取字符串 :
left(str,n)
例:select left(‘腾讯视频’,2)
结果为:‘腾讯’ - 从右开始截取字符串 :
right(str,n)
例:select right(‘腾讯视频’,2)
结果为:‘视频’ - substring按指定位置截取字符串 :
substring(str,pos)——substring(被截取字段,从第几位开始截取)
substring(str,pos,length)——substring(被截取字段,从第几位开始截取,截取长度)
例1:select substring(‘1970-01-01’,1)
结果为:‘1970-01-01’
例2:select substring(‘1970-01-01’,1,7)
结果为:‘1970-01’ - substring_index按指定关键字截取字符串 :
substring_index(str,delim,count)——substring(被截取字段,关键字,关键字出现的次数)
例1:select substring_index(‘1970-01-01’,’-’,1)
结果为:‘1970’
例2:select substring_index(‘1970-01-01’,’-’,2)
结果为:‘1970-01’