最近在看一个超级好看的剧,里面的女主涂着红红的口红,我也涂了~
文中需要用到MLxtend,MLxtend是一个基于Python的开源项目,主要为日常处理数据科学相关的任务提供了一些工具和扩展。
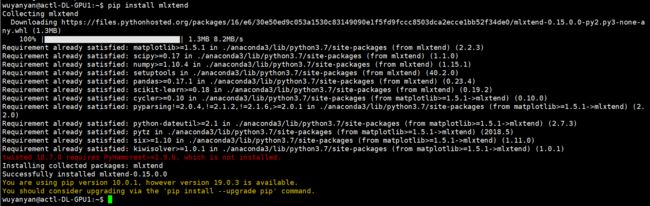
一、安装包:MLxtend
pip install mlxtend
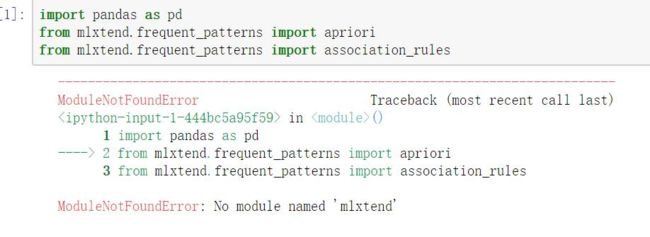



二、加载数据
1.出现问题
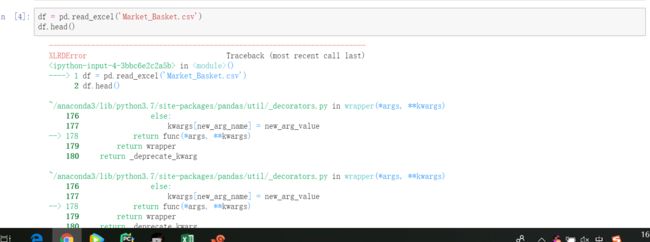
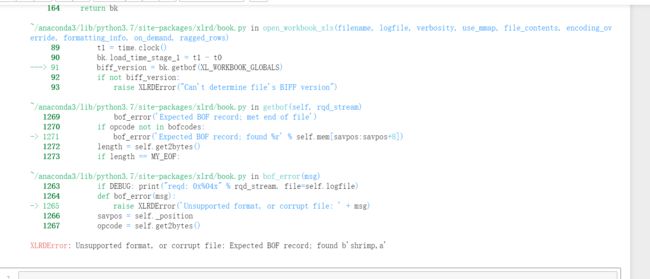
二、解决方法

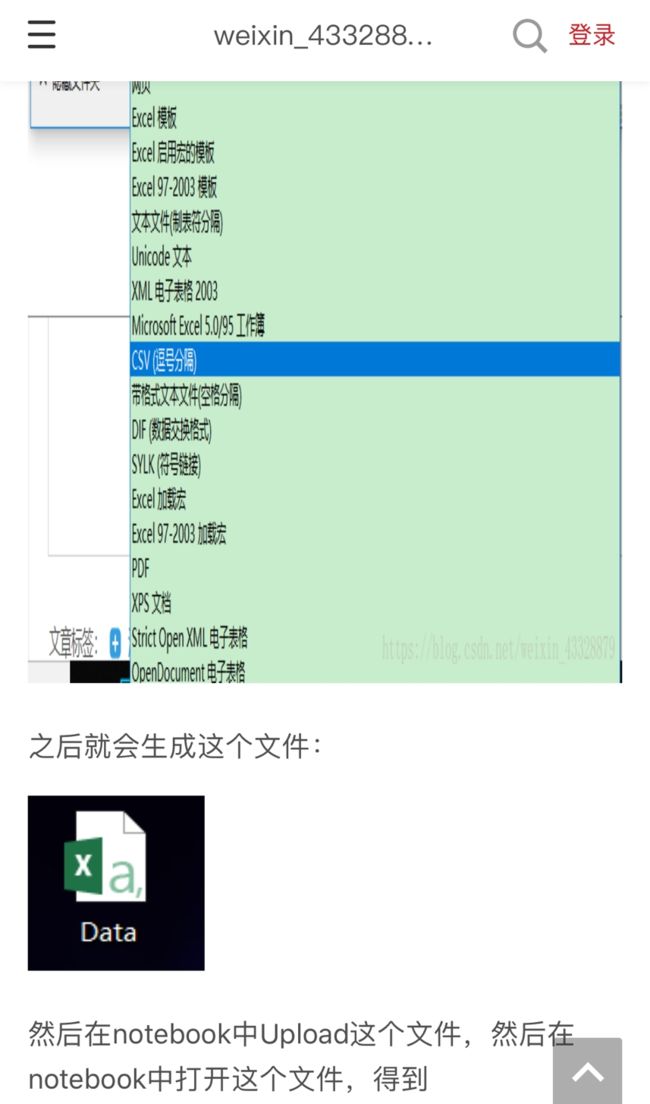

由于已经是csv格式,所以直接输入:
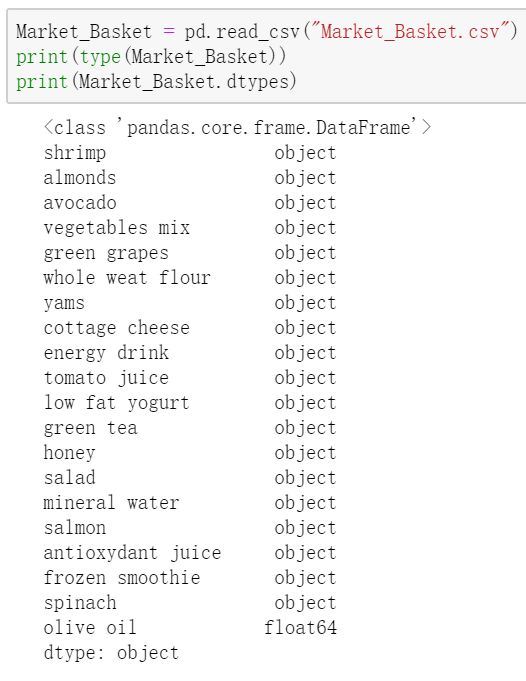
pd.read_csv:


无从下手,应该规定一下每一行、每一列的意义
每一行:一个购物篮
每一列:购物篮中的商品
先看看pd读的对不对:
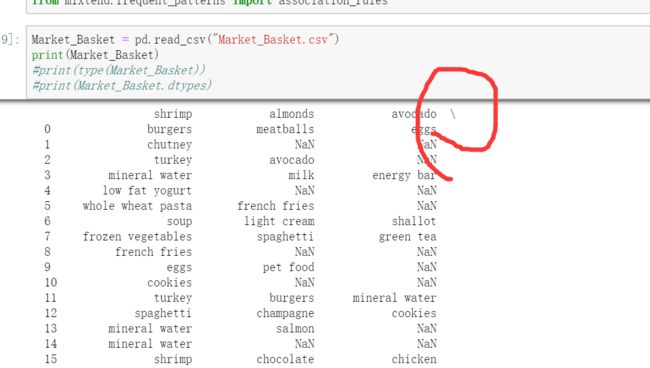
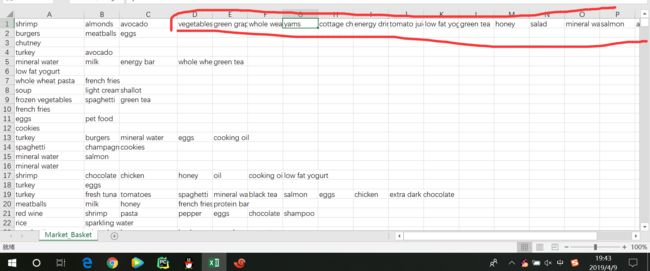
但是被截断了

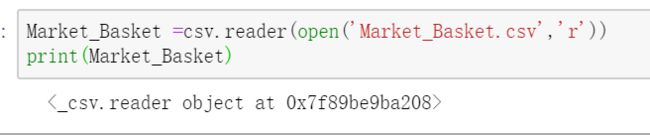
然后按行打印:
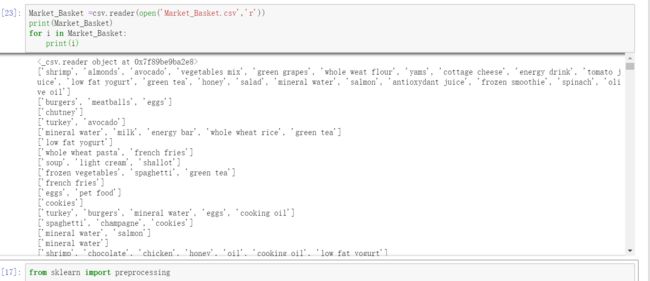
再将这些存在一个数组中:
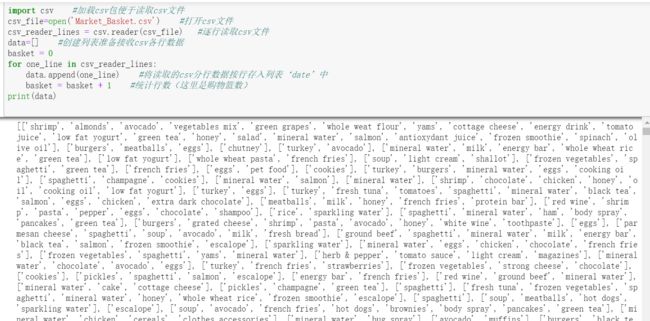
统计商品种类:
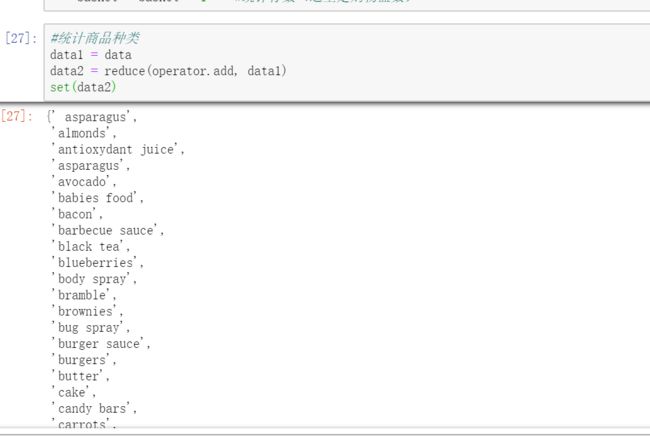

One-Hot编码:
1、什么是独热码
独热码,在英文文献中称做 one-hot code, 直观来说就是有多少个状态就有多少比特,而且只有一个比特为1,其他全为0的一种码制,更加详细参加one_hot code(维基百科)。在机器学习中对于离散型的分类型的数据,需要对其进行数字化比如说性别这一属性,只能有男性或者女性或者其他这三种值,如何对这三个值进行数字化表达?一种简单的方式就是男性为0,女性为1,其他为2,这样做有什么问题?
使用上面简单的序列对分类值进行表示后,进行模型训练时可能会产生一个问题就是特征的因为数字值得不同影响模型的训练效果,在模型训练的过程中不同的值使得同一特征在样本中的权重可能发生变化,假如直接编码成1000,是不是比编码成1对模型的的影响更大。为了解决上述的问题,使训练过程中不受到因为分类值表示的问题对模型产生的负面影响,引入独热码对分类型的特征进行独热码编码。
可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征(如成绩这个特征有好,中,差变成one-hot就是100, 010, 001)。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
这样做的好处主要有:
(1)解决了分类器不好处理属性数据的问题
(2)在一定程度上也起到了扩充特征的作用



威神女神
S
K
A
M
以下为我摘取的别人的,贴上原文链接https://blog.csdn.net/hellozhxy/article/details/80600845
著名的啤酒与尿布, 这是典型的购物篮问题, 在数据挖掘界叫做频繁项集(Frequent Itemsets).
note: 数据类型写法按照Python的格式.
一. 目标与定义
1. 问题背景
超市中购物清单中总是有一些项目是被消费者一同购买的. 如果我们能够发现这些关联规则(association rules), 并合理地加以利用, 我们就能取得一定成果. 比如我们发现热狗和芥末存在这种关系, 我们对热狗降价促销, 而对芥末适当提价, 结果能显著提高超市的销售额.
2. 目标
找到频繁地共同出现在消费者结账小票中项目(比如啤酒和尿布), 来一同促销, 相互拉动, 提高销售额.
3. 定义
支持度support: 其实就是概率论中的频次frequency
支持度阈值support threshhold: 记为s, 指分辨频繁项集的临界值.
频繁项集: 如果I是一个项集(Itemset), 且I的出现频次(i.e.支持度)大于等于s, 那么我们说I是频繁项集.
一元项, 二元项, 三元项: 包含有一种商品, 两种, 三种商品的项集.
4. 关联规则
关联规则: 形式为I->j, 含义是如果I种所有项都出现在某个购物篮的话, 那么j很有可能也出现在这个购物篮中. 我们可以给出相应的confidence值(可信度, 即概率论中的置信度).
其中, 这个关联规则的可信度计算为Confidence = I∪{j} / I, 本身是非常符合直觉和常识的. 比如我们说关联规则{dog, cat} -> and 的可信度为0.6, 因为{dog, cat}出现在了1, 2, 3, 6, 7五个购物篮中, 而and出现在了1,2,7中, 因此我们可以算出Confidence = freq[{dog, cat, and}] / freq[{dog, cat}] = 3/5 = 0.6
注意到, 分子部分的频次总是比分母低, 这是因为{dog, cat} 出现的次数总是大于等于{dog, cat, and}的出现次数.
二. 购物篮与A-Priori算法
1. 购物篮数据表示
我们将有一个文本文件输入, 比如allBills.txt, 或者allBills.csv. 里面每行是一个购物篮.
文件的头两行可能是这样(df.show(2)):
{23, 456, 1001}
{3, 18, 92, 145}
我们假定这是一家大型连锁超市, 比如沃尔玛, 因此这个文本文件是非常大的, 比如20GB. 因此我们无法一次将该文件读入内存. 因此, 算法的主要时间开销都是磁盘IO.
我们同时还假定, 所有购物篮的平均规模是较小的, 因此在内存中产生所有大小项集的时间开销会比读入购物篮的时间少很多.
我们可以计算, 对于有n个项目组成的购物篮而言, 大小为k的所有子集的生成时间约为(n, k) = n! / ((n-k)!k!) = O(n^k/ k!), 其中我们只关注较小的频繁项集, 因此我们约定k=2或者k=3. 因此所有子集生成时间T = O(n^3).
Again, 我们认为在内存中产生所有大小项集的时间开销会比读入购物篮的时间少很多.
2. Itemset计数过程中的内存使用
我们必须要把整个k,v字典放在内存中, 否则来一个Itemset就去硬盘读取一次字典将十分十分地慢.
此处, 字典是k=(18, 145), v=15这种形式. 此处, 应当注意到, 如果有{bread, milk, orange}这样的String类型输入, 应当预先用一个字典映射成对应的整数值编码, 比如1920, 4453, 9101这样.
那么, 我们最多能用字典存储多少种商品?
先看下我们存储多少个count值.
我们假定项的总数目是n, 即超市有n种商品, 每个商品都有一个数字编号, 那么我们需要(n, 2) = n^2/2 的大小来存储所有的二元组合的count, 假设int是占4个byte, 那么需要(2·n^2)Byte内存. 已知2GB内存 = 2^31 Byte, 即2^31/2 = 2^30 >= n^2 --> n <= 2^15. 也就是说n<33 000, 因此我们说商品种类的最多是33k种.
但是, 这种计算方法存在一个问题, 并不是有10种商品, 那么这10种商品的任意二元组合都会出现的. 对于那些没出现的组合, 我们在字典中完全可以不存储, 从而节省空间.
同时, 别忘了我们同样也得存储key = (i, j), 这是至少额外的两个整数.
那么我们到底具体怎么存储这些计数值?
可以采用三元组的方式来构造字典. 我们采用[i, j, count]形式来存储, 其中i代表商品种类1, j代表商品种类2, 前两个值代表key, 后面的value就是count, 是这个二元组合下的计数.
现在, 让我们注意到我们(1)假定购物篮平均大小较小, 并(2)利用三元组(2个key的)字典和(3)不存储没出现组合优势. 假设有100k = 10^5种商品, 有10million=10^7个购物篮, 每个购物篮有10个项, 那么这种字典空间开销是(10, 2) · 10^7 = 45 x 10^7 x 3= 4.5x10^8x3 = 1.35x10^9 个整数. 这算出来约为4x10^8 Byte = 400MB, 处于正常计算机内存范围内.
3. 项集的单调性
如果项集I是频繁的, 那么它的所有子集也都是频繁的. 这个道理很符合常识, 因为{dog, cat} 出现的次数总是大于等于{dog, cat, and}的出现次数.
这个规律的推论, 就是严格地, 我们频繁一元组的个数> 频繁二元组的个数 > 频繁三元组的个数.
4. A-Priori算法
我们通过Itemset计数中内存使用的部门, 已经明确了我们总是有足够的内存用于所有存在的二元项集(比如{cat, dog})的计数. 这里, 我们的字典不存放不存在于购物篮中的任何二元项集合, 而且频繁二元组的数目将会大于三元频繁三元组> ...
我们可以通过单边扫描购物篮文件, 对于每个购物篮, 我们使用一个双重循环就可以生成所有的项对(即二元组). 每当我们生成一个项对, 就给其对应的字典中的value +1(也称为计数器). 最后, 我们会检查所有项对的计数结果,并且找出那些>=阈值s的项对, 他们就是频繁项对.
1) A-Priori算法的第一遍扫描
在第一遍扫描中, 我们将建立两个表. 第一张表将项的名称转换为1到n之间的整数, 从而把String类型这样的key转为空间大小更小的int类型. 第二张表将记录从1~n每个项在所有购物篮中出现的次数. 形式上类似
table 0(name table): {'dolphin': 7019, 'cat': 7020} //dict形式, 其实也可以做成list形式 [['dolphin', 7019], ['cat', 7020]]
table 1(single-item counter table): {7019: 15, 7020: 18} //dict形式, 其实也可以做成数组形式A[7019] = 2, A[7020] = 18
2) 第一遍扫描完的处理
第一遍扫描完后, 我们会按照自己设定的阈值s, 对整个table 1再进行一次mapping, 因为我们只关注最后counter值大于等于阈值的项目, 而且不关心其counter值具体多少. 因此, mapping策略是:
对凡是counter
3) 第二遍扫描
第二遍扫描所做的事有三:
(1) 对每个购物篮, 在table 1中检查其所有的商品项目, 把所有为频繁项的留下来建立一个list.
(2) 通过一个双重循环生成该list中的所有项对.
(3) 再走一次循环, 在新的数据结构table 2(dict或者list)中相应的位置+1. 此时的效果是dicta = {48: {13: 5}, 49: {71, 16}} 或者 lista [ [48, 13, 5],[49, 71, 16], ... ]
注意此时内存块上存储的结构: table1(name table), table2(single-item counter table), table3(double-item counter table)
5. 推广: 任意大小频繁项集上的A-Priori算法
我们对上面这个算法进行推广.
从任意集合大小k到下一个大小k+1的转移模式可以这么说:
(1) 对每个购物篮, 在table 1中检查其所有的商品项目, 把所有为频繁项的留下来建立一个list.
(2) 我们通过一个k+1重循环来生成该list中的所有(k+1)元组
(3) 对每个k+1元组, 我们生成其的(k+1 choose k)个k元组, 并检查这些k元组是否都在之前的table k中. (注意到k=1的时候, 这步与(1)是重复的, 可以省略)
(4)再走一次循环, 在新的数据结构table k+1(dict或者list)中相应的位置+1. 此时的效果是k=2, k+1=3, 生成dicta = {48: {13: {19: 4}}, 49: {71: {51: 10}}, ... } 或者 生成lista [ [48, 13, 19, 4],[49, 71, 51, 10], ... ]
注意, 在进入下一次扫描前, 我们还需要额外把counter中值小于s的元组的计数值都记为0.
模式总体是: C1 过滤后 L1 计数后 C2 置零后 C2' 过滤后 L2 计数后 C3 置零后 C3' ......
END.

S
K
A
M

生成的商品种类为set形式:转成list形式
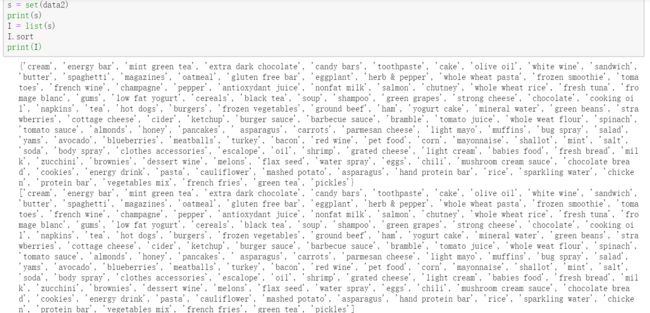
第一张表:把项名称转换为1~n的整数:
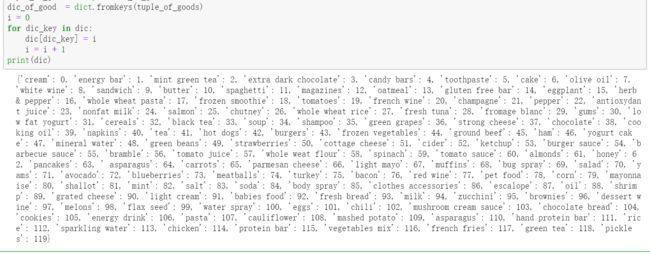

至于数数,大神说,你就用collections.Counter就好:哈?




哈哈,可爱的wyy,开始分析吧~噜噜噜啦啦啦~噜啦噜啦噜~

生成全零矩阵:
换成zeros:
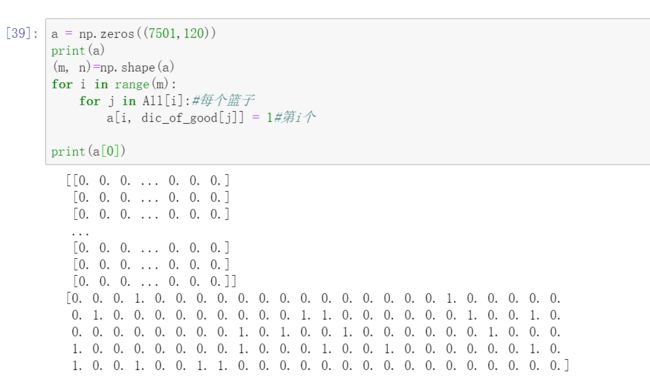

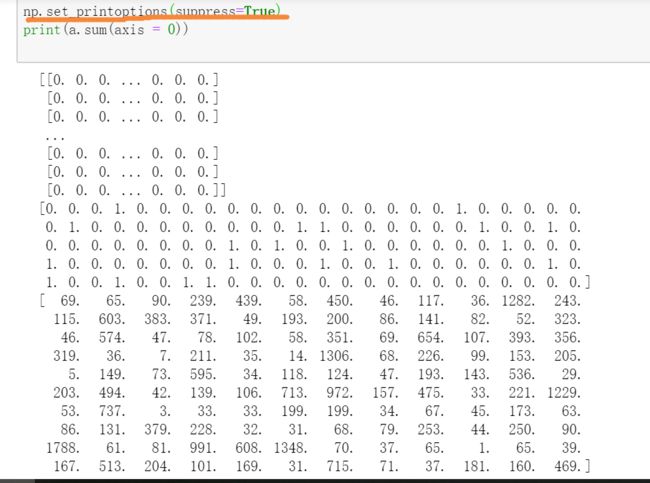
统计每一列的和,即每种商品的购买总数:
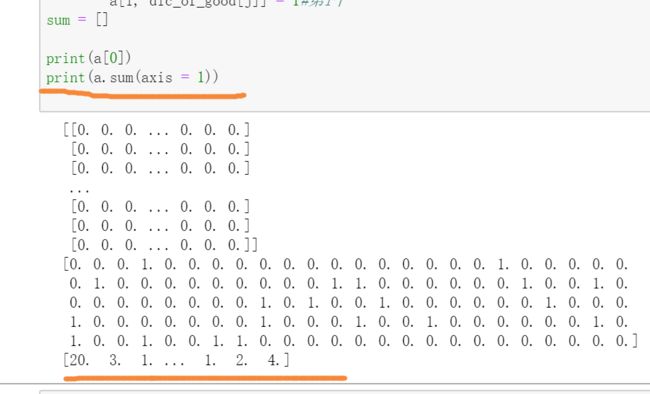
每一行列:


第一行:

建立一个新的只含有频繁一项集的购物篮矩阵:
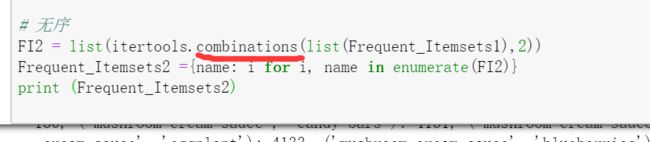
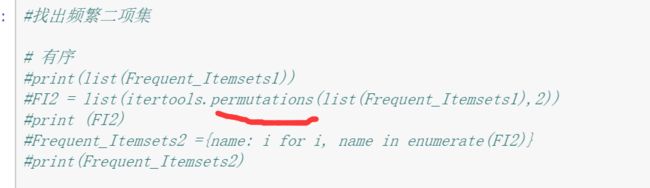
频繁二项集: