漂亮的人脸卡通化,小视科技开源成熟模型与训练数据

卡通画一直以幽默、风趣的艺术效果和鲜明直接的表达方式为大众所喜爱。近年来,随着多部动漫电影陆续成为现象级爆款,越来越多的人开始在社交网络中使用卡通画作为一种表意的文化载体。
在这个过程中,以表情包和定制头像的兴起为例,人们开始尝试以融入个人特征和个性想法的卡通画来实现信息的精准传播。且传播主体不再局限于传统动画制作公司,而是以大众为主体的娱乐化传播。
因此,人们对于定制卡通画的需求与日俱增。然而高质量的卡通画需要有经验的画师精心绘制,从线稿设计到色彩搭配,整个流程耗时费力,对于大众而言购买成本较高。
小视科技AI团队近期上线的“AI卡通秀”小程序能够自动实现真实世界照片的卡通风格转变,效果精美自然。为增加行业内交流,促进技术层面的共同提升,该团队现已开源卡通化模型和数据。

图1 “AI卡通秀”小程序卡通风格化效果
图像卡通风格渲染是一项具有挑战性的任务,其目的是将真实照片转换为卡通风格的非真实感图像,同时保持原照片的语义内容和纹理细节。现有的图像卡通风格渲染的方法主要分成两大类:
一是利用传统图像处理技术的方法。该方法只能处理纹理内容简单的图片,因为这些方法本质上是图像滤波和边缘增强的结合,效果受图像内容的影响很大,泛化能力较差。
二是基于深度神经网络的方法。此方法通常难以在转换图像全局风格和保持图像局部的细节语义内容之间取得良好的平衡,易导致风格化程度不足或者丢失图像中的语义细节,产生人工痕迹(Artifacts)。
目前,图像卡通化任务的主要难点:
卡通图像往往有清晰的边缘,平滑的色块和经过简化的纹理,与其他艺术风格有很大区别。使用传统图像处理技术生成的卡通图无法自适应地处理复杂的光照和纹理,效果较差;基于风格迁移的方法无法对细节进行准确地勾勒。
数据获取难度大。绘制风格精美且统一的卡通画耗时较多、成本较高,且转换后的卡通画和原照片的脸型及五官形状有差异,因此不构成像素级的成对数据,难以采用基于成对数据的图像翻译(Paired Image Translation)方法。
照片卡通化后容易丢失身份信息。基于非成对数据的图像翻译(UnpairedImage Translation)方法中的循环一致性损失(Cycle Loss)无法对输入输出的id进行有效约束。

具体方法
基于上述分析,研究人员提出了一种基于生成对抗网络的卡通化模型,只需少量非成对的训练数据,就能获得漂亮的结果。卡通风格渲染网络是本方法提出的解决方案核心,它主要由特征提取、特征融合和特征重建三部分组成。整体框架由图2所示。
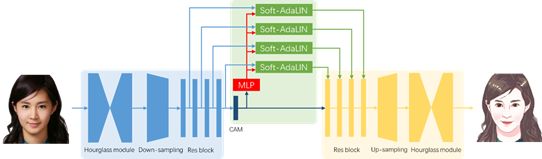
图2 卡通化模型整体框架
特征提取部分包含堆叠的Hourglass模块、下采样模块和残差模块。Hourglass模块常用于姿态估计,它能够在特征提取的同时保持语义信息位置不变。本方法采用堆叠的Hourglass模块,渐进地将输入图像抽象成易于编码的形式。4个残差模块编码特征并提取统计信息用于后续的特征融合。
特征融合部分使用研究人员提出的Soft-AdaLIN(Soft Adaptive Layer-Instance Normalization),先将输入图像的编码特征统计信息和卡通特征统计信息相融合,再以AdaLIN的方式反规范化解码特征,使卡通画结果更好地保持输入图像的语义内容。
不同于原始的AdaLIN,这里的“Soft”体现在不直接使用卡通特征统计量来反规范化解码特征,而是通过可学习的权重![]() 来加权平均卡通特征和编码特征的统计量,并以此对规范化后的解码特征进行反规范化。
来加权平均卡通特征和编码特征的统计量,并以此对规范化后的解码特征进行反规范化。
编码特征统计量![]() 提取自特征提取部分中各Resblock的输出特征,卡通特征统计量
提取自特征提取部分中各Resblock的输出特征,卡通特征统计量![]() 通过全连接层提取自CAM(Class Activation Mapping)模块输出的特征图。加权后的统计量为:
通过全连接层提取自CAM(Class Activation Mapping)模块输出的特征图。加权后的统计量为:
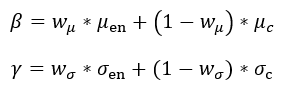
则Soft-AdaLIN操作可以表示为:
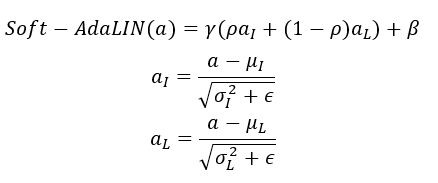
其中![]() 为特征重建部分中各Resblock提取的解码特征,
为特征重建部分中各Resblock提取的解码特征,![]() 为channel-wise均值、标准差,
为channel-wise均值、标准差,![]() 为layer-wise均值、标准差,
为layer-wise均值、标准差,![]() 用于调整InstanceNorm和Layer Norm的比重,
用于调整InstanceNorm和Layer Norm的比重,![]() 为防止除零的常数。
为防止除零的常数。
特征重建部分负责从编码特征生成对应的卡通图像。特征重建部分采用与特征提取部分对称的结构,通过解码模块、上采样模块和Hourglass模块生成卡通画结果。
损失函数
除了常规的Cycle Loss和GAN Loss,研究人员还引入了ID Loss,使用预训练的人脸识别模型来提取输入真人照和生成卡通画的id特征,并用余弦距离来约束,使卡通画的id信息与输入照片尽可能相似。
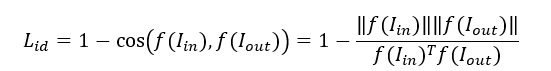
其中,![]() 为输入的真实图像,
为输入的真实图像,![]() 为生成的卡通图像,
为生成的卡通图像,![]() 为预训练的人脸特征提取模型用于提取512维的id特征。
为预训练的人脸特征提取模型用于提取512维的id特征。
实验
实验所用的卡通图像数据共204张,人脸照片数据共820张,均收集自互联网。由于实验数据有限,为了降低训练难度,我们将数据处理成固定的模式。
首先检测图像中的人脸及关键点,根据关键点旋转校正图像,并按统一标准裁剪,再将裁剪后的头像输入人像分割模型去除背景,流程如图3所示。

图3 数据预处理
实验效果如下:

图4 卡通化效果
更多训练细节参见github项目:
https://github.com/minivision-ai/photo2cartoon
“AI卡通秀”小程序
为了更好地展示实验效果,小视科技推出基于此技术的“AI卡通秀”微信小程序。该小程序能实时将用户自拍转换为卡通风格,并提供滤镜和动图合成功能。
团队采用少量定制的卡通图像素材进行训练,保留了卡通画风格的同时,在五官细节的勾勒上效果远好于其他同类算法,这也意味着该算法可以更好地还原人像本身的可辨识信息。
得益于深度神经网络渲染算法的泛化能力,算法在不同人群、光线、背景、表情、姿态等多种变量下都具有出色的鲁棒性,最终模型能够较为稳定地生成精美的卡通肖像。

图5 “卡通秀”小程序卡通人像生成效果

图6 同类软件效果对比,第一张为真实照片,第二张为“卡通秀”生成结果,后三张为同类软件效果

图7 “卡通秀”小程序滤镜效果


图8 “卡通秀”小程序动图合成效果
开源模型与更多细节:
https://github.com/minivision-ai/photo2cartoon
END

备注:人脸

人脸技术交流群
人脸卡通化、检测、识别、对齐、重建、表情识别、表情迁移等技术,
若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 