华为云modelarts中pytorch的分类模型的部署
模型包规范
modelarts的模型导入的模型包的规范如下:
https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0091.html
文件目录
OBS桶/目录名
|── vgg16
| ├── model 必选: 固定子目录名称,用于放置模型相关文件
| │ ├── <<自定义Python包>> 可选:用户自有的Python包,在模型推理代码中可以直接引用
| │ ├── vgg6.pth 必选,pytorch模型保存文件,保存为“state_dict”,存有权重变量等信息。
| │ ├──config.json 必选:模型配置文件,文件名称固定为config.json, 只允许放置一个
| │ ├──customize_service.py 可选:模型推理代码,文件名称固定为customize_service.py, 只允许放置一个,customize_service.py依赖的py文件可以直接放model目录下
模型配置文件
{
"model_type": "PyTorch",
"runtime": "python3.6",
"model_algorithm": "image_classification",
"metrics": {
"f1": 0.0,
"accuracy": 0.95,
"precision": 0.0,
"recall": 0.0
},
"apis": [{
"protocol": "https",
"url": "/",
"method": "post",
"request": {
"Content-type": "multipart/form-data",
"data": {
"type": "object",
"properties": {
"images": {
"type": "file"
}
}
}
},
"response": {
"Content-type": "multipart/form-data",
"data": {
"type": "object",
"properties": {
"predicted_label": {
"type": "string"
},
"scores": {
"type": "array",
"items": [{
"type": "array",
"minItems": 2,
"maxItems": 2,
"items": [{
"type": "string"
},
{
"type": "number"
}
]
}]
}
}
}
}
}],
"dependencies": [{
"installer": "pip",
"packages": [{
"restraint": "ATLEAST",
"package_version": "1.15.0",
"package_name": "numpy"
},
{
"restraint": "",
"package_version": "",
"package_name": "h5py"
},
{
"restraint": "ATLEAST",
"package_version": "1.0.0",
"package_name": "torch"
},
{
"restraint": "ATLEAST",
"package_version": "5.2.0",
"package_name": "Pillow"
}
]
}]
}
推理代码
from PIL import Image
import numpy as np
import torch.nn as nn
import torch
from model_service.pytorch_model_service import PTServingBaseService
from torchvision import transforms
transform = transforms.Compose(
[
transforms.Resize([224,224]),
transforms.ToTensor()
]
)
use_gpu = torch.cuda.is_available()
label_id_name_dict = \
{
0: "猫",
1: "狗",
}
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, features, num_classes=2):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
def vgg16(**kwargs):
model = VGG(make_layers(cfg['D']), **kwargs)
return model
class cat_dog_Service(PTServingBaseService):
def __init__(self, model_name, model_path):
print( "[LIRUI(1):]" )
print(model_name,model_path)
# 调用父类的初始化方法,方法参数为(model_name, model_path)
super(cat_dog_Service, self).__init__(model_name, model_path)
self.model_name = model_name
self.model_path = model_path
# self.model定义为用户load后的模型
self.model = vgg16()
self.model.load_state_dict(torch.load(self.model_path))
if use_gpu:
self.model = self.model.cuda()
else:
self.model = self.model.cpu()
self.model.eval()
torch.no_grad()
print("[LIRUI(2):]")
print(self.model)
def _preprocess(self, data):
# 预处理成{key:input_batch_var},input_batch_var为模型输入张量
preprocessed_data = {}
for k, v in data.items():
print("[lirui]")
print(k,v)
input_batch = []
for file_name, file_content in v.items():
with Image.open(file_content) as image1:
image1=image1.convert("RGB")
test_image_tensor = transform(image1).unsqueeze(0)
print("[lirui]")
print(test_image_tensor.size())
if use_gpu:
test_image_tensor = test_image_tensor.cuda()
else:
test_image_tensor = test_image_tensor.cpu()
#input_batch.append(test_image_tensor)
#input_batch_var = torch.autograd.Variable(torch.stack(input_batch, dim=0), volatile=True)
#preprocessed_data[k] = input_batch_var
preprocessed_data[k] = test_image_tensor
return preprocessed_data
def _inference(self, data):
result = {}
for k, v in data.items():
print("[lirui]")
print(k,v)
print(v.size())
output = self.model(v)
print(output)
result[k] = output.data.cpu().numpy()
print(result[k])
return result
def _postprocess(self, data):
#根据标签索引到图片的分类结果
#print(data)
for output_name, preds in data.items():
print(preds)
if preds is not None:
idx = np.argmax(preds, axis=1)
pred_result = {'result': label_id_name_dict[idx[0]]}
else:
pred_result = {'result': 'predict score is None'}
return pred_result
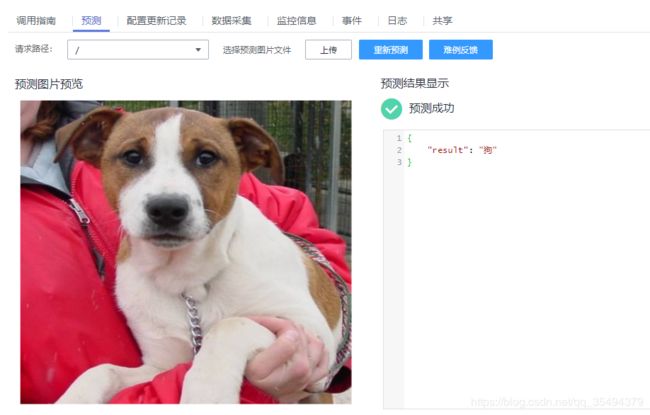
测试结果如下