MapReduce实现WordCount词频统计
文章目录
- 一.设计分析
- 二.代码开发
- 1.新建maven工程,添加依赖
- 2.编写Mapper类
- 3.编写Reduce类
- 4.编写Driver类执行Job
- 5.执行会在本工程目录出现一个test目录打开目录中的part-r-00000文件即统计词频文件,如下:
- 6.在hadoop中运行
- 1)修改Driver类中输入输出路径:
- 2)打jar包将jar包上传到hadoop的lib目录下
- 3)将测试数据上传到hdfs目录中:
- 4)提交MapReduce作业运行: (注意如果存在output目录需要先删除)
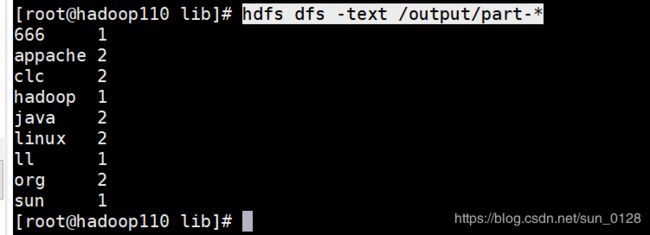
- 5)查看作业输出结果,如下图所示:
一.设计分析
- 1.Map过程:并行读取文本,对读取的单词进行map操作,每个词都以
- 2.Reduce操作是对map的结果进行排序合并最后得出词频
二.代码开发
1.新建maven工程,添加依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
2.编写Mapper类
package hadoop.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author sunyong
* @date 2020/07/01
* @description
* KEYIN:输入的key类型
* VALUEIN:输入的value类型
* KEYOUT:输出的key类型
* VALUEOUT:输出的value类型
*/
public class WCMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.将文本转化成字符串
String line = value.toString();
//2.将字符串切割
String[] words = line.split("\\s+");
//3.循环遍历,将每一个单词写出去
for (String word : words) {
k.set(word);
context.write(k,v);
}
}
}
3.编写Reduce类
package hadoop.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author sunyong
* @date 2020/07/01
* @description
* KEYIN:reduce端输入的key类型,即map端输出的key类型
* VALUEIN:reduce输入的value类型,即map端输出的value类型
* KEYOUT:reduce输出的key类型
* VALUEOUT:reduce输出的value类型
*/
public class WCReducer extends Reducer< Text,IntWritable,Text, IntWritable> {
IntWritable v = new IntWritable();
int sum;
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//reduce端接收到的类型大概是这样的 (wish,(1,1,1,1))
//对迭代器进行累加求和
//sum必须赋值为0初始化,因为reduce方法是每个键都会执行一次
sum=0;
for (IntWritable count : values) {
sum+=count.get();
}
v.set(sum);
//将key和value进行写出
context.write(key,v);
}
}
4.编写Driver类执行Job
package hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author sunyong
* @date 2020/07/01
* @description
*/
public class WCDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1.创建配置文件,创建Job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"wordcount");
//2.设置jar的位置,参数为本类类名.class
job.setJarByClass(WCDriver.class);
//3.设置map和reduce的位置
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
//4.设置map输出端的key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置reduce输出的key,value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置输入和输出路径,输入的是本地自己建的txt文件,会输出一个test目录
FileInputFormat.setInputPaths(job,new Path("F:\\sunyong\\Java\\codes\\javaToHdfs\\download\\a.txt"));
FileOutputFormat.setOutputPath(job,new Path("test"));
//7.提交程序运行
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
5.执行会在本工程目录出现一个test目录打开目录中的part-r-00000文件即统计词频文件,如下:

6.在hadoop中运行
1)修改Driver类中输入输出路径:
//6.设置输入输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
2)打jar包将jar包上传到hadoop的lib目录下
3)将测试数据上传到hdfs目录中:
hdfs dfs -mkdir /input,hdfs dfs -put /tmp/test.txt /input/
4)提交MapReduce作业运行: (注意如果存在output目录需要先删除)
hadoop jar /opt/install/hadoop/lib/javaToHdfs.jar hadoop.mapreduce.WCDriver /input/test.txt /output
5)查看作业输出结果,如下图所示:
hdfs dfs -text /output/part-*