从零开始学习TFLearn(二)
TFLearn究竟给了我们什么?
本文将对TFLearn所提供的一些功能包进行简要地介绍,从而帮助我们对TFLearn有一个整体地了解,主要参考Getting started with TFLearn。
1.简要剖析TFLearn
打开TFLearn包,其中有以下文件:
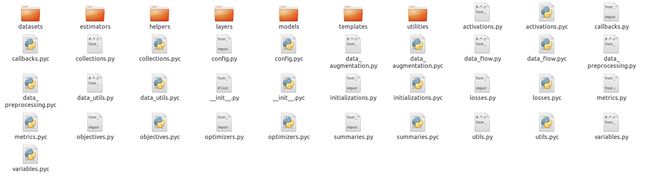
从上图中可以看见,TFLearn中包含了7个文件夹,它们分别是datasets、estimators、helpers、layers、models、templates、utilities,以及一些很常用的函数(定义在各个.py文件中)。
下面我们来看一下各个文件夹中都有哪些乾坤。
1)datasets:
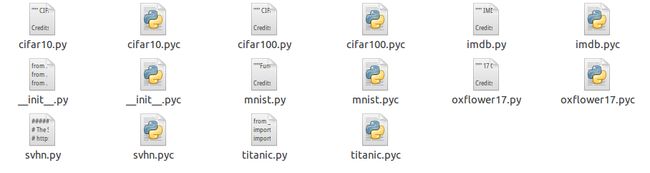
其中包含了a)小型图像识别数据库CIFAR-10 and CIFAR-100,b)互联网电影资料库IMDb,c)手写数字识别数据库MNIST,d)17类花卉数据集oxflower17,e)真实世界街道门牌号数据集SVHN,f)泰坦尼克号数据集titanic。
2)estimators:

在我安装的这个版本中,除了ensemble中实现了一个随机森林之外,其他的几个这些.py文件中的类的定义都是pass,这里就暂时不聊了,等更新。
3)helpers:

其中evaluator用于执行预测以及评估一个模型的好坏,与上面的estimators是不一样的。从英语释义来看,evaluate指的是评估,而estimate指的是估计。事实上,estimator是一些函数估计器,比如神经网络等;而evaluator则是模型的评估器,传入模型,评估其好坏,或者利用模型对一组Tensor进行预测。
generator是一个序列产生器,仍然是raise NotImplementedError,也就不说了......
在regularizer定义的函数中,目前能用的,或者说实现了的,只有add_weights_regularizer,这个函数用于正则化我们的权重参数,防止过拟合。
summarizer定义了一些帮助我们去记录参数更新过程的函数,比如summarize_all()、summarize_variables()等,可以用Tensorboard查看。
最后trainer中主要定义了两个类,Trainer和TrainOp。Trainer用于对训练中的一些变量和函数进行封装,TrainOp则对优化一个model时会用到的一些operations进行表示。此外,trainer中还定义了一些工具函数,后面用到的时候再进行分析。
4)layers:
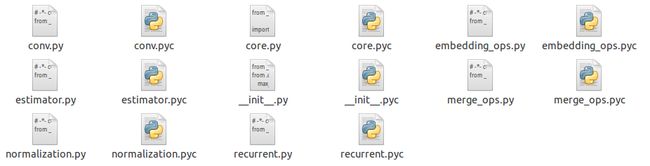
显而易见,这个文件夹中包含的就是对于常用神经网络层的一些定义,比如卷积神经网络,批正则化(batch normalization),以及input_data层、fully_connected层、dropout层(这几个定义在core.py中)等等,其中extimator.py文件中定义了regression的一个wrapper,也即对回归进行了封装,返回值类型仍然为Tensor。值得一提的是,在core.py中还提供了一个特殊的函数custom_layer(),这个函数允许我们自己定义函数操作作为参数传入。此外,在core.py中还定义了一些有用的函数,比如reshape()、flatten()、one_hot_encoding()等。
5)models:

这里就两个.py文件,一个是dnn.py,定义了一个深度神经网络的wrapper,我们传入一个net(其实就是通过ops对Tensor进行操作得到的最后的一个Tensor,所以可以看做一个网络)。而generator.py中则是定义了一个SequenceGenerator,这其实就是上面helper中的generator.py没有完成的事情,可以看出来现在TFLearn的在完善当中......
6)templates:

这个文件夹就一个cnn.py,而且其中还是空的......
7)utilities:

嗯,这个文件夹也可以忽略不计......
好了,回过头来看,其实TFLearn库的结构并不复杂,而且很多功能仍在完善中,有兴趣的同学还可以去GitHub上帮帮忙~
2.TFLearn API
在这一小节中,我们主要看看TFLearn都提供了哪些常用的API。
1)Layer:
TFLearn中的layers可以看成是一个TensorFlow ops的集合体,比如说,一个卷积层将会
a)创建并初始化权值weights和偏置biases变量;
b)对于传入的Tensor应用卷积操作;
c)卷积之后再弄一个激活函数;
d)......
比如说,我们使用TensorFlow搭一个卷积层:
with tf.name_scope('conv1'):
W = tf.Variable(tf.random_normal([5, 5, 1, 32]), dtype=tf.float32, name='Weights')
b = tf.Variable(tf.random_normal([32]), dtype=tf.float32, name='biases')
x = tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
x = tf.add_bias(x, b)
x = tf.nn.relu(x)tflearn.conv_2d(x, 32, 5, activation='relu', name='conv1')
| File | Layers |
|---|---|
| core | input_data, fully_connected, dropout, custom_layer, reshape, flatten, activation, single_unit, highway, one_hot_encoding, time_distributed |
| conv | conv_2d, conv_2d_transpose, max_pool_2d, avg_pool_2d, upsample_2d, conv_1d, max_pool_1d, avg_pool_1d, residual_block, residual_bottleneck, conv_3d, max_pool_3d, avg_pool_3d, highway_conv_1d, highway_conv_2d, global_avg_pool, global_max_pool |
| recurrent | simple_rnn, lstm, gru, bidirectionnal_rnn, dynamic_rnn |
| embedding | embedding |
| normalization | batch_normalization, local_response_normalization, l2_normalize |
| merge | merge, merge_outputs |
| estimator | regression |
除了上面的用于搭建神经网络的各种层之外,TFLearn还提供了许多不同的ops来帮助我们建立神经网络。当然这些ops首先是被用来搭建上面的各种层的,其次,还可以被用来构建TensorFlow图模型。在实践中,我们只需要提供op的名字作为参数,比如activation='relu' or regularizer='L2' for conv_2d,当然,这些参数也可以换成自己写的函数。
| File | Ops |
|---|---|
| activations | linear, tanh, sigmoid, softmax, softplus, softsign, relu, relu6, leaky_relu, prelu, elu |
| objectives | softmax_categorical_crossentropy, categorical_crossentropy, binary_crossentropy, mean_square, hinge_loss, roc_auc_score, weak_cross_entropy_2d |
| optimizers | SGD, RMSProp, Adam, Momentum, AdaGrad, Ftrl, AdaDelta |
| metrics | Accuracy, Top_k, R2 |
| initializations | zeros, uniform, uniform_scaling, normal, truncated_normal, xavier, variance_scaling |
| losses | l1, l2 |
# Activation and Regularization inside a layer:
fc2 = tflearn.fully_connected(fc1, 32, activation='tanh', regularizer='L2')
# Equivalent to:
fc2 = tflearn.fully_connected(fc1, 32)
tflearn.add_weights_regularization(fc2, loss='L2')
fc2 = tflearn.tanh(fc2)
# Optimizer, Objective and Metric:
reg = tflearn.regression(fc4, optimizer='rmsprop', metric='accuracy', loss='categorical_crossentropy')
# Ops can also be defined outside, for deeper customization:
momentum = tflearn.optimizers.Momentum(learning_rate=0.1, weight_decay=0.96, decay_step=200)
top5 = tflearn.metrics.Top_k(k=5)
reg = tflearn.regression(fc4, optimizer=momentum, metric=top5, loss='categorical_crossentropy')在TensorFlow中,我们需要定义一个train_op:
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
# Use the optimizer to apply the gradients that minimize the loss
train_op = optimizer.minimize(loss, global_step=global_step)network = ... (some layers) ...
network = regression(network, optimizer='sgd', loss='categorical_crossentropy')
model = DNN(network)
model.fit(X, Y) 同样,DNN中也集成预测函数:
network = ...
model = DNN(network)
model.load('model.tflearn')
model.predict(X)4)Visualization:
在使用TensorFlow时,如果想要记录某些训练中的数据,比如参数变化,比如损失函数的值的变化等,我们需要添加tensorboard summaries,这是很麻烦的。而TFLearn本身就带有很好用的logs,它支持自动summaries:
a)0:Loss & Metric (Best speed).
b)1:Loss, Metric & Gradients.
c)2:Loss, Metric, Gradients & Weights.
d)3:Loss, Metric, Gradients, Weights, Activations & Sparsity (Best Visualization).
比如,我们可以在DNN模型类中添加一个tensorboard_verbose参数:
model = DNN(network, tensorboard_verbose=3)然后我们就可以利用tensorboard来可视化网络及其性能了:
$ tensorboard --logdir='/tmp/tflearn_logs
在对模型进行训练的过程中,我们肯定是想保存其中某些时刻的模型参数的,比如当模型在某次迭代之后代价函数达到最优,我们希望将此时模型的参数记录下来;或者,我们希望从某次记录的参数中恢复模型,可以直接调用DNN模型类的函数:
# Save a model
model.save('my_model.tflearn')
# Load a model
model.load('my_model.tflearn')我们也可以很快地获取某一层的参数:
# Let's create a layer
fc1 = fully_connected(input_layer, 64, name="fc_layer_1")
# Using Tensor attributes (Layer will supercharge the returned Tensor with weights attributes)
fc1_weights_var = fc1.W
fc1_biases_var = fc1.b
# Using Tensor name
fc1_vars = tflearn.get_layer_variables_by_name("fc_layer_1")
fc1_weights_var = fc1_vars[0]
fc1_biases_var = fc1_vars[1]获取或设置某个变量的值:
input_data = tflearn.input_data(shape=[None, 784])
fc1 = tflearn.fully_connected(input_data, 64)
fc2 = tflearn.fully_connected(fc1, 10, activation='softmax')
net = tflearn.regression(fc2)
model = DNN(net)
# Get weights values of fc2
model.get_weights(fc2.W)
# Assign new random weights to fc2
model.set_weights(fc2.W, numpy.random.rand(64, 10))当然,我们也可以用TensorFlow的eval()和assign()函数对变量的值进行获取和设置。具体见weight_persistence.py。
6)Fine-tuning:
我们知道,网上会有别人挂出的一些自己训练好了的模型,我们想要将其用于解决自己的问题,但是我们的问题和别人的问题又不是很一致,因此我们就需要对网上的模型进行精调。在TFLearn中,我们可以指定哪些层的权重是想要从下载的模型中恢复的(当然,这只能对有权重的层进行设置):
# Weights will be restored by default.
fc_layer = tflearn.fully_connected(input_layer, 32)
# Weights will not be restored, if specified so.
fc_layer = tflearn.fully_connected(input_layer, 32, restore='False') 所有不需要被恢复的权重变量都将被添加到tf.GraphKeys.EXCL_RESTORE_VARS collection中,当我们加载一个pre-trained模型时,这些变量在恢复过程中将被忽略。例子finetuning.py中,将会为我们展示如何通过恢复除了最后一个全连接层之外的所有层的参数,并在新的数据集上训练,从而精调一个pre-trained模型,用于一个新的任务。
7)Data management:
TFLearn支持numpy array数据格式,此外,它还支持HDF5用于处理大型数据集(我们需要自行安装h5py):
# Load hdf5 dataset
h5f = h5py.File('data.h5', 'r')
X, Y = h5f['MyLargeData']
... define network ...
# Use HDF5 data model to train model
model = DNN(network)
model.fit(X, Y)具体可以参考hdf5.py。
8)Data Preprocessing and Data Augmentation:我们通常要对数据进行预处理或进行数据集增强处理,所以TFLearn库就提供了一些wrappers使得这些操作更加方便。值得注意的是,TFLearn的数据流是管道型的,利用CPU进行数据预处理,利用GPU进行模型训练,从而达到加速的目的。
# Real-time image preprocessing
img_prep = tflearn.ImagePreprocessing()
# Zero Center (With mean computed over the whole dataset)
img_prep.add_featurewise_zero_center()
# STD Normalization (With std computed over the whole dataset)
img_prep.add_featurewise_stdnorm()
# Real-time data augmentation
img_aug = tflearn.ImageAugmentation()
# Random flip an image
img_aug.add_random_flip_leftright()
# Add these methods into an 'input_data' layer
network = input_data(shape=[None, 32, 32, 3],
data_preprocessing=img_prep,
data_augmentation=img_aug) 更多细节见Data Preprocessing和Data Augmentation。
所有的层都通过variable_op_scope来建立,这使得我们在多个层之间共享变量更为简单,并且使得TFLearn能够用于分布式训练。同样scope name的layers将会共享相同的weights。
# Define a model builder
def my_model(x):
x = tflearn.fully_connected(x, 32, scope='fc1')
x = tflearn.fully_connected(x, 32, scope='fc2')
x = tflearn.fully_connected(x, 2, scope='out')
# 2 different computation graphs but sharing the same weights
with tf.device('/gpu:0'):
# Force all Variables to reside on the CPU.
with tf.arg_scope([tflearn.variables.variable], device='/cpu:0'):
model1 = my_model(placeholder_X)
# Reuse Variables for the next model
tf.get_variable_scope().reuse_variables()
with tf.device('/gpu:1'):
with tf.arg_scope([tflearn.variables.variable], device='/cpu:0'):
model2 = my_model(placeholder_X)
# Model can now be trained by multiple GPUs (see gradient averaging)
...10)Graph Initialization:
或许有时我们想要对计算资源进行限制,比如分配更多或更少的GPU RAM memory。为了达到这一目的,TFLearn提供了一个graph initializer在运行之前配置一个graph:
tflearn.init_graph(set_seed=8888, num_cores=16, gpu_memory_fraction=0.5)具体见config。
好了,本文就介绍到这里,下一篇博客将介绍如何将TensorFlow中的operations和TFLearn中的built-in layers及operations进行结合,详见Extending Tensorflow。
马上周末咯,祝大家周末愉快,开开心心休息两天~