深度之眼Paper带读笔记NLP.11:FASTTEXT.Baseline.06
文章目录
- 前言
- 论文总览
- 第一课 论文导读
- 文本分类简介
- 相关技术
- 词表征
- 词袋模型
- 词频与逆词频指数Term Frequency-Inverse Document frequency
- 基于特征的表征Feature based Representations
- 单词到向量Word 2 Vector
- 用于文本分类的卷积神经网络
- 文本分类的再思考
- Fasttext历史意义
- 前期知识储备
- 第二课 论文精读
- 论文整体框架
- 经典算法模型
- 卷积神经网络
- 动机:输入序列的编码
- 用于文本的CNN
- 用于文本的卷积:堆卷积stack convolution
- 延迟CNN
- 用于文本的通道
- 整体流程
- 小结
- 论文提出的模型
- n-gram表征
- 线性模型
- 回顾:skipgram模型
- 损失函数的近似:霍夫曼树
- CBoW 模型
- FastText模型
- Fasttext模型和CBOW模型的区别和联系
- n-gram feature
- Hashing Trick
- 实验和结果
- 实验Experiments
- 情感分析-性能
- 情感分析-运行时间
- 标签预测
- 讨论和总结
- 讨论
- 创新点
- 参考文献
- Sub Word
- 原因
- 解决方案
- Sub Word模型的训练
- 实验
- 复现
- 数据集
- 数据加载
- 模型构建
- 训练和测试
- 作业
前言
本课程来自深度之眼deepshare.net,部分截图来自课程视频。
文章标题:Bag of Tricks for Efficient Text Classification
原标题翻译:高效率文本分类的技巧包
or.Fasttext:对于高效率文本分类的一揽子技巧
划重点:Efficient 快~~!模型的名字也体现了这一点,比上一个baseline快了好几个数量级。
作者:Armand Joulin; Edouard Grave; Piotr Bojanowski; Tomas Mikolov
最后一个作者是word2vec的作者
单位:Facebook AI Research
发表会议及时间:EACL2017
这个东东已经开源了:
https://fasttext.cc/
FastText is an open-source, free, lightweight library that allows users to learn text representations and text classifiers. It works on standard, generic hardware. Models can later be reduced in size to even fit on mobile devices.

另外,还涉及到另外一篇文章:
Enriching Word Vectors with Subword Information
作者也是这几个人,不过顺序换了
Piotr Bojanowski∗
and Edouard Grave∗
and Armand Joulin
and Tomas Mikolov
关于Subword的讲解放在后面。
在线LaTeX公式编辑器
论文总览
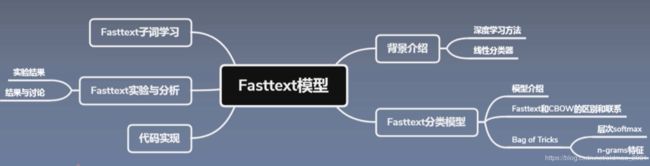
第一课 论文导读
a、文本分类
文本分类是根据文本内容为文本分配标签或类别的过程。 它是自然语言处理中的基本任务之一,具有广泛的应用,如情感分析,主题标记,垃圾邮件检测和意图检测。
b、词频与逆词频指数
词频与逆词频指数是文本分类中非常重要的特征,具有非常强的实战价值与意义,在许多的工程项目中以及自然语言处理的比赛中都有非常强的应用,要求熟练掌握。
c、词表征
如果说自然语言处理问题中,几乎所有的问题都是序列问题,那么最细粒度的表征就是词表征,因为这些序列都是有词构成的(当然还char embedding),词表征是自然语言处理必要的基本功,解决任何有关的问题都必须要了解的知识点。
d、卷积神经网络
在将文本转换为具体的词表征后,再利用卷积神经网络从这样的表征中抽取特征完成文本的分类,这是文本分类中最经典有效的神经网络方法,许多其他的state-of-art都建立在这样的baseline中,要求完成复现。
文本分类简介
·Input:
·A document d d d
·A fxed set of classes C = c 1 , c 2 … , c n C={c_1,c_2…,c_n} C=c1,c2…,cn
·The input document can be considered as a sequence
·Output:
·A prediction class c ∈ C c\in C c∈C
相关技术
词表征
In traditional NLP,we regard words as discrete symbols:localist representation Words can be represented by one-hot vectors:one 1,the rest 0s
motel=[000000010000]
hotel=[010000000000]
Vector dimension=number of words in vocabulary
词袋模型
词频与逆词频指数Term Frequency-Inverse Document frequency
t f i d f ( t , d , D ) = t f ( t , d ) × i d f ( t , D ) tfidf(t,d,D)=tf(t,d)\times idf(t,D) tfidf(t,d,D)=tf(t,d)×idf(t,D)
term-frequency(tf):number of times the term t appears in the document d
i d f ( t , D ) = l o g N ∣ { d ∈ D : t ∈ d } ∣ idf(t,D)=log\frac{N}{|\{d\in D:t\in d\}|} idf(t,D)=log∣{d∈D:t∈d}∣N
t:term
D:set of documents
TF-IDF is high:this word appears much more frequently in this document compared to other documents
TF-IDF is low:this word appears infrequently in this document,or it appears in many documents
基于特征的表征Feature based Representations
·Linguistic features-POS tags,Dependency labels
·Location based features-position of a token,relative positions
·Morphological features-case,number of characters
·Task specific features-presence of certain tokens etc.
重点:
·Features should be discriminative enough to help the classifier
Drawbacks
·hand-engineered
·Less understanding about the context
·Sparse Features
·Not transferable across tasks
单词到向量Word 2 Vector
Word2Vec Overview:
Predict surrounding words
图略
说明见上篇文章
用于文本分类的卷积神经网络
基于卷积神经网络的文本分类模型 2014
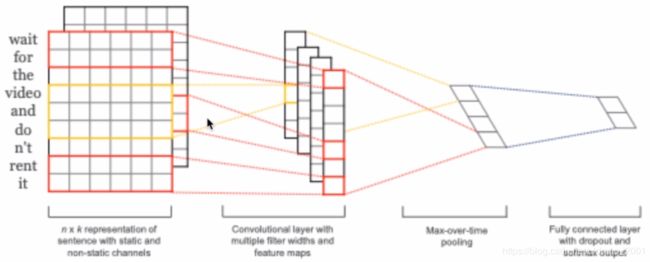
·Concatenation of word representations
·resemblance with images
·What does a windows mean here?
·N-gram!
·Multiple sized windows capture various n-grams
·Bi-gram,tri-gram,4-gram are generally used
·A Bag of n-grams!
基于CNN的词级别的文本分类 2015
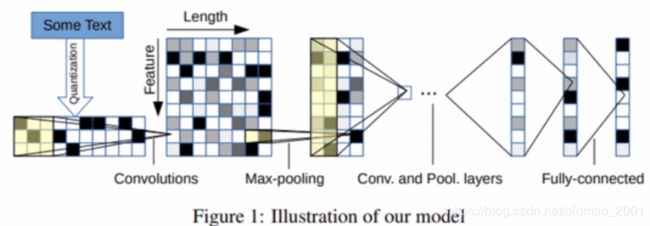
文本分类的再思考
deep learning classifiers:
·good performance in practice
·relatively slow both at train and test time
·limiting their use to very large datasets!
linear classifiers:
·simple
·obtain state-of-the-art performances if the right features are used
·potential to scale to very large corpus
于是就有了本文,考虑使用词向量+线性分类器进行文本分类。

以上基于深度学习的文本分类模型
优点:
1.效果好,一般能达到了目前最好的分类效果。
2.不用做特征工程,模型简洁。
缺点:
速度太慢,无法在大规模的文本分类任务上使用。
当然还有基于机器学习的文本分类模型
优点:
1.速度一般都很快,因为模型都是线性分类器,所以比较简单。
2.效果还可以,在某些任务上也能取得最好的效果。
缺点:
需要做特征工程,分类效果依赖于有效特征的选取。
因此,本文的动机就出来了:
综合深度学习的文本分类模型和机器学习的文本分类模型的优点,达到:
·速度快
·效果好
·自动特征工程
Fasttext历史意义
·提出了一种新的文本分类方法——Fasttext,能够进行快速的文本分类,并且效果很好。
·提出了一种新的使用子词的词向量训练方法——Fasttext,能够一定程度上解决OOV问题。
·将Fasttext开源,使得工业界和学术界能够快速使用Fasttext。
前期知识储备
CNN:了解卷积神经网络(CNN)的文本分类,句子建模上的基本应用
文本分类:了解文本分类的意义与应用
word2vec:了解word2vec的动机,具体算法,实现细节(大厂面试几乎必问)
TF-IDF:掌握文本分类中非常重要的非深度学习的特征
第二课 论文精读
论文整体框架
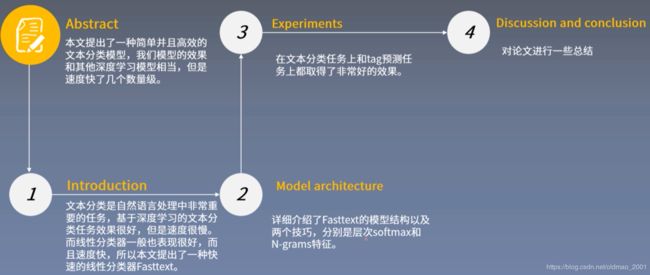
■Abstract
- 本文为文本分类任务提出了一种简单并且高效的基准模型——Fasttext。
This paper explores a simple and efficient baseline for text classification. - Fasttext模型在精度上和基于深度学习的分类器平分秋色,但是在训练和测试速度上Fasttext快上几个数量级。
Our experiments show that our fast text classifier fastText is often on par with deep learning classifiers in terms of accuracy, and many orders of magnitude faster for training and evaluation. - 我们使用标准的多核CPU在10亿词的数据集上训练Fasttext,用时少于10分钟,并且在一分钟内分类好具有312K类别的50万个句子。
We can train fastText on more than one billion words in less than ten minutes using a standard multicore CPU, and classify half a million sentences among 312K classes in less than a minute.
■1.Introduction
- 文本分类是自然语言处理的重要任务,可以用于信息检索、网页搜索、文档分类等。
Text classification is an important task in Natural Language Processing with many applications, such
as web search, information retrieval, ranking and document classification (Deerwester et al., 1990;
Pang and Lee, 2008). - 基于深度学习的方法可以达到非常好的效果,但是速度很慢,限制了文本分类的应用。
Recently, models based on neural networks have become increasingly popular (Kim, 2014; Zhang and LeCun, 2015; Conneau et al., 2016). While these models achieve very good performance in practice, they tend to be relatively slow both at train and test time, limiting their use on very large datasets. - 基于机器学习的线性分类器效果也很好,有用于大规模分类任务的潜力。
Meanwhile, linear classifiers are often considered as strong baselines for text classification problems (Joachims, 1998; McCallum and Nigam, 1998; Fan et al., 2008). Despite their simplicity, they often obtain stateof-the-art performances if the right features are used (Wang and Manning, 2012). They also
have the potential to scale to very large corpus (Agarwal et al., 2014). - 从现在词向量学习中得到的灵感,我们提出了一种新的文本分类方法Fasttext,这种方法能够快速的训练和测试并且达到和最优结果相似的效果。
In this work, we explore ways to scale these baselines to very large corpus with a large output space, in the context of text classification. Inspired by the recent work in efficient word representation learning (Mikolov et al., 2013; Levy et al., 2015), we show that linear models with a rank constraint and a fast loss approximation can train on a billion words within ten minutes, while achieving performance on par with the state-of-the-art. We evaluate the quality of our approach fastText on two different tasks, namely tag prediction and sentiment
analysis.
■2.Model architecture
·2.1Hierarchical softmax
·2.2N-gram features
■3.Experiments
·3.1Sentiment analysis
·3.2 Tag prediction
■Discussion and Conclusion
经典算法模型
卷积神经网络

Input Space
-Sequences
-can be of varying length
-comes with a natural order which defines a context around a token
动机:输入序列的编码
A natural way of encqding is capturing the temporality Temporal order(时序) are typically captured by RNNs
Let’s see how encoding is done in computer vision-We use CNNs
Filters learn in a convolution process has correspondence to actual filters we use for different image conversions(blur filter, edge filter, Gabor filter)
But interpretation of internal representations are not direct in RNNs.
We only know each hidden unit encodes the previous contexts
Can we achieve somewhat similar with textual inputs too?
1.N-grams:A collection of bag of tokens
N-grams are heavily used in various feature engineering stages in traditional NLP
2. Given a token, we typically collect the combinations of n-other tokens We expect that this individual bag of tokens is efficient to encode context around a token
3. CNN is a natural way of creating such bag of features
The filters capture a window of input (a bag) and perform linear and non-linear operations back-to-back
4. The work by Yoon Kim was one of the successful early applications of CNN to encode texts
模型结构及原理在之前的第八篇带读有,不贴了。。
用于文本的CNN
· The idea mainly came from Collobert et al.(NLP from scratch)
·1-d convolution is equivalent of time delay neural network
· Two major paradigms:
Context window modelling (embedding the surrounding context)(这个主要用于标签tagging)
Sentence modelling (extract n-grams,pool to combine over whole sentence)(这个主要用于文本分类)
What are different ways can you think of to use CNN(Kim,2014) as an encoding block to capture the linguistic constituents of a sentence?
(hint: character, phrases. dependency trees)
用于文本的卷积:堆卷积stack convolution
来自:Goldberg Book
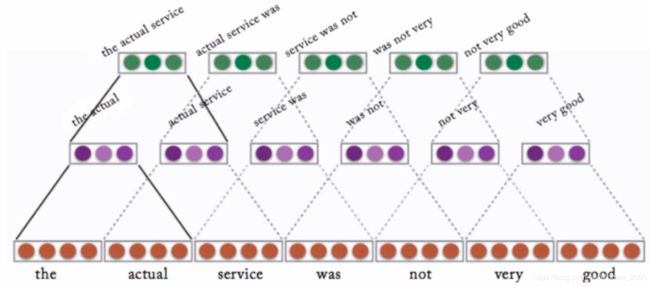
延迟CNN
来自:Kalchbrenner et al.2016
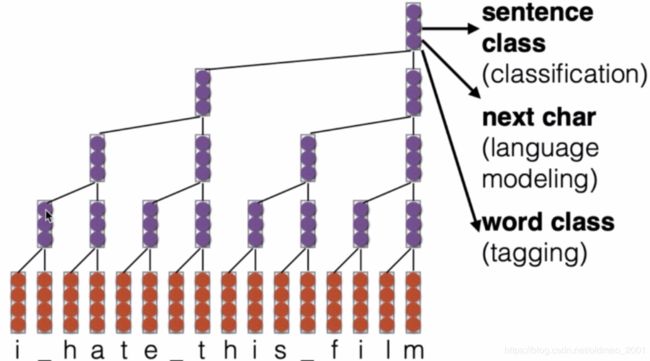
延时体现在对第一个词i进行卷积后,先不进行下一个卷积而是等第二个词卷积结果出来再进行卷积操作。
用于文本的通道
·We know RGB channel in images
·What does a channel mean for text?
·Multi-channel CNN
·Variety of word representations are used
·Static(frozen,do not get updated)
·Dynamic(fine-tuned,task specific)
整体流程
Input Space is formed by pre-trained word vectors.
Encoding is done by CNN.
A softmax classifier for m-class classification.
小结
优点
·achieve very good performance in practice
缺点
·relatively slow both at train and test time
·limiting their use on very large datasets
咋整:
So what about the linear classifiers?
·simple(bag of words BoW representation +linear classifiers)
·obtain state-of-the-art performances if the right features are used
·have the potential to scale to very large corpus
Several drawbacks:
·No sentence representations:Taking the average pre-trained word vector is popular But does not work very well.
·Not exploiting morphology:Words with same radicals don’t share parameters 例如:类似这样的词对disastrous/disaster mangera/mangerai无法学到的。
论文提出的模型
fastText=text representation +linear model
·text representation
·n-gram
·look-up table over the words
·CBoW
·linear model
·with rank constraint(这里可以参数共享)
·hierarchical softmax

模型的损失函数原文是这样写的:
L = − 1 N ∑ n = 1 N y n log ( f ( B A x n ) ) L=-\cfrac{1}{N}\sum_{n=1}^Ny_n\text{log}(f(BAx_n)) L=−N1n=1∑Nynlog(f(BAxn))
其中 x n x_n xn是词袋模型得到的特征表示
y n y_n yn是标签
f f f是softmax函数
N是有N个文档
例如:我们有4个分类,用过softmax分类得到四个结果 [ 0.1 , 0.2 , 0.6 , 0.1 ] [0.1,0.2,0.6,0.1] [0.1,0.2,0.6,0.1]
对应的标签是:[0,0,1,0]
根据损失函数公式:计算求和部分:
0×log0.1+0×log0.2+1×log0.6+0×log0.1=1×log0.6
可以看到实际上损失函数只用计算标签对应的项即可。
n-gram表征
1-gram

2-gram

·Possible to add higher-order features
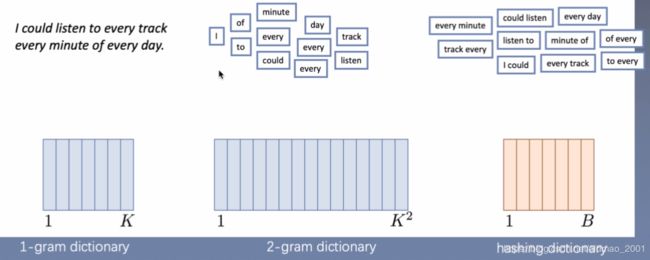
·Avoid building n-gram dictionary
就是1-gram的时候得到的词典长度为n,2-gram词典长度为n-1,以此类推,n-gram的长度为1。所有可能性就是 ( 1 + n ) n 2 \frac{(1+n)n}{2} 2(1+n)n,然后这里的词典复杂度就朝着 n 2 n^2 n2发展,这里一段没怎么理解。
因此把词典弄成hash模式。
线性模型

Minimizing the Negative Log-Likelihood:
− 1 ∣ D ∣ ∑ i = 1 ∣ D ∣ y i l o g ( y ~ i ) -\frac{1}{|D|}\sum_{i=1}^{|D|}y_ilog(\tilde y_i) −∣D∣1i=1∑∣D∣yilog(y~i)
其中 y i y_i yi是由softmax函数得来的:
− 1 ∣ D ∣ ∑ i = 1 ∣ D ∣ y i l o g ( s o f t m a x ( W ∗ x i ) ) -\frac{1}{|D|}\sum_{i=1}^{|D|}y_ilog(softmax(W*x_i)) −∣D∣1i=1∑∣D∣yilog(softmax(W∗xi))
其中: ∣ D ∣ |D| ∣D∣:Number of Documents
y i y_i yi:Label
W W W: Hidden Layer Weights
x i x_i xi:Vector Representation
然后根据softmax的结构得到:
− 1 ∣ D ∣ ∑ i = 1 ∣ D ∣ y i l o g ( e W ∗ x i ∑ j = 1 ∣ D ∣ e W ∗ x j ) -\frac{1}{|D|}\sum_{i=1}^{|D|}y_ilog(\frac{e^W*x_i}{\sum_{j=1}^{|D|}e^{W*x_j}}) −∣D∣1i=1∑∣D∣yilog(∑j=1∣D∣eW∗xjeW∗xi)
回顾:skipgram模型


·Replace the multiclass loss by a set of binary logistic losses
·Negative sampling

·Hierarchical softmax
class c c c represented by set of codes y c k y_{ck} yck
Huffman tree to generate codes
frequent classes:short codes
∑ k ∈ K c l o g ( 1 + e y c k x w t T v n ) \sum_{k\in K_c}log(1+e^{y_{ck}x^T_{w_t}v_n}) k∈Kc∑log(1+eyckxwtTvn)
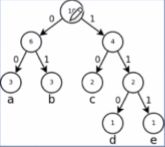
损失函数的近似:霍夫曼树
Many Classes
Hierarchical Softmax
Huffman Coding Tree

This is an example of a huffman tree.
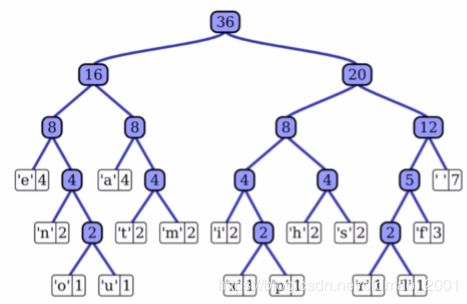
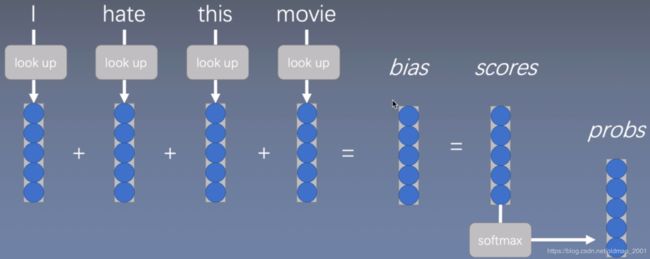
CBoW 模型

FastText模型
·Model probability of a label given a paragraph
p ( l ∣ P ) = e h p T v l ∑ k = 1 K e h p T v k p(l|P)=\frac{e^{h^T_pv_l}}{\sum_{k=1}^Ke^{h^T_pv_k}} p(l∣P)=∑k=1KehpTvkehpTvl
·Paragraph feature段落特征
h P = ∑ w ∈ P x w h_P=\sum_{w\in P}x_w hP=w∈P∑xw
·Word vectors are latent and not useful per se
·If scarce supervised data,use pre-trained word vectors
Fasttext模型和CBOW模型的区别和联系
联系:
1.都是Log-linear模型,模型非常简单。
2.都是对输入的词向量做平均,然后进行预测。Fasttext预测的是标签,CBOW预测的是中心词
3.模型结构完全一样。
区别:
1.Fasttext提取的是句子特征,CBOW提取的是上下文特征。
2.Fasttext需要标注语料,是监督学习,CBOW不需要标注语料,是无监督学习。
目前的Fasttext存在的问题:
1.当类别非常多的时候,最后的softmax速度依旧非常慢。(本文用了312K,相当于31万个类别)
2.使用的是词袋模型,没有词序信息。
解决方法:
1.类似于word2vec,使用层次softmax(原文2.1节)。
2.使用n-gram特征(原文2.2节)。
层次softmax在word2vec里面有详解,这里不赘述,看下n-gram特征
n-gram feature
这个在原文的2.2节,用这个东西的原因很简单,词袋模型是不讲究词序的,也就是基本忽略上下文信息,所以这里要引入n-gram,n-gram原来就是CBOW中用上下文预测中心词的方法。这里用了上下文的词,所以词表示可以包含词序特征。
Bag of words is invariant to word order but taking explicitly this order into account is often computationally very expensive. Instead, we use a bag of n-grams as additional features to capture some partial information about the local word order. This is very efficient in practice while achieving comparable results to methods that explicitly use the order (Wang and Manning, 2012).
Hashing Trick
由于在训练过程中用了多种gram,例如1-gram,2-gram,3-gram。
例如我们的词库有3万个词:
1-gram后还是3万
2-gram后就变成10万(估计的,因为2-gram是两个词进行可能的组合)
3-gram后就变成了40万
3个类型合起来就变成了53万,对于词库而言,太大了,解决这个的方法就是Hashing Trick
这个和数据结构里面hash查找有关。
具体做法如下:
先定一个小目标,我们的gram词库大小为10万;
其中1-gram肯定要存,因为单个词使用概率挺高的,10-3=7,还剩7w个位置;
剩下7万的位置,还有50万的萝卜怎么办,用求模的方式把这50万个萝卜都塞到7万个坑中,就是1-7w的萝卜对应1-7w的位置,7万零1到14万的萝卜又对应到1-7w的坑,以此类推。
有点像数据结构的拉链法:
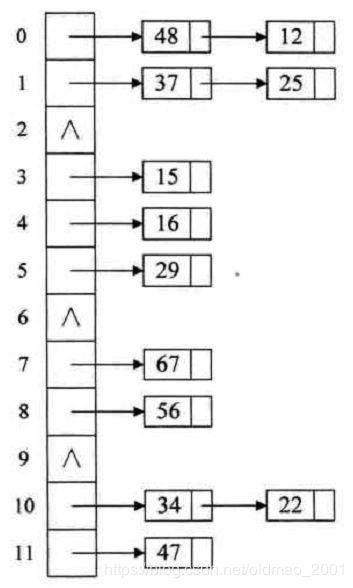
We maintain a fast and memory efficient mapping of the n-grams by using the hashing trick (Weinberger et al., 2009) with the same hashing function as in Mikolov et al. (2011) and 10M bins if we only used bigrams, and 100M otherwise.
实际上:

实验和结果
实验Experiments
Tag Prediction
·YFCC 100M Dataset:
100M images with captions,titles and tags
Sentiment Analysis
·Uses the same 8 datasets as Zhang et al.(2015)
情感分析-性能
看第一行8个数据集和上篇baseline一样
AG’s news corpus:新闻数据集,分4类,主题相关,每个类别3w记录。
Sogou news corpus:新闻数据集,分5类,主题相关,每个类别9w记录。这个是中文数据,作者用pypinyin package combined with jieba Chinese segmentation system to produce Pinyin得到拼音。
DBPedia ontology dataset:来自维基百科,主题相关。
Yelp reviews:餐馆评论数据集,2分类:1 and 2 negative, and 3 and 4 positive.
5分类:5星评论各为一类。语义相关。
Yahoo! Answers dataset:10分类,主题相关
Amazon reviews:和Yelp 一样有两种分类方法。语义相关。
————————————————

词向量大小为10
最后一行词向量大小为10,且使用了2-gram
情感分析-运行时间
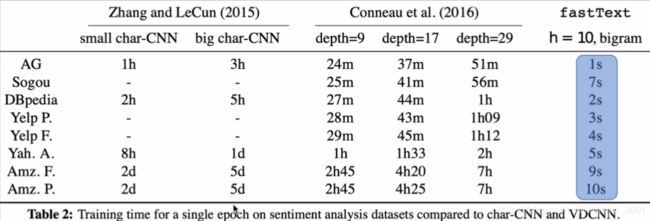
快了不止一个量级,在small char-CNN中跑一个epoch要一个小时,我自己跑过,用CPU是40多分钟,用本文模型1s搞定。
标签预测
·Using Flickr Data
·Given an image caption
·Predict the most likely tag
·Sample outputs:(YFCC100M数据集实验效果及时间对比)


讨论和总结
关键点
·基于深度学习的文本分类方法效果好,但是速度比较慢
·基于线性分类器的机器学习方法效果还行,速度也比较快,但是需要做烦琐的特征工程
·Fasttext模型
创新点
·提出了一种新的文本分类模型–Fasttext模型
·提出了一些加快文本分类和使得文本分类效果更好的技巧——层次softmax和n-gram特征。
·在文本分类和tag预测两个任务上得到了又快又好的结果。
启发点
·虽然这些深度学习模型能够取得非常好的效果,但是他们在训练和测试的时候到非常慢,这限制了他们在大数据集上的应用。
While these models achieve very good performance in practice,they tend to be relatively slow both at train and test time,limiting their use on very large datasets(Introduction P1)
·然而,线性分类器不同特征和类别之间不共享参数,这可能限制了一些只有少量样本类别的泛化能力。
However,linear classifiers do not share parameters among features and classes.This possibly limits their generalization in the context of large output space where some classes have very few examples.(2 Model architecture P1)
讨论
问题
如何减少训练时间:用线性模型
线性模型不能实现参数共享?对线性模型的参数进行一个rank constraint
如何提升训练的时间以及准确率:n-grams +hierarchical softmax
创新点
A改进了之前的线性模型处理文本分类
B在标签分类和情感分类问题效果很好
C训练速度非常快,具有非常强的工程意义
参考文献
[1]http://www.phontron.com/class/nn4nlp2019/assets/slides/nn4nlp-03-wordemb.pdf
[2]http://phontron.com/class/nn4nlp2019/assets/slides/nn4nlp-04-cnn.pdf
[3]https://nlpparis.files.wordpress.com/2016/11/fasttext-nlpmeetup-23112016.pptx
[4]https://github.com/kperi/pydata2018/blob/master/embeddings.pdf
Sub Word
和skip-gram模型比较相似,就从中心词预测周围词的思想。
原因
由于词表示有缺点,尤其是对于只关注词本身,例如某一个单词:representation,已经训练好了词向量,如果由于拼写错误,写成了reprisentation,那么词表示模型就会认为这个词是另外一个词,不是representation,而且这个词由于拼写错误,没有出现在词表中,变成了一个OOV词,这种情况在一些博客或者评论语料中会经常出现,亦或者是representations,多了一个s,变成复数形式后,模型也认为这个是一个新的词。
也就是说词表示忽略了词本身的表征信息。
Continuous word representations, trained on large unlabeled corpora are useful for many natural language processing tasks. Popular models that learn such representations ignore the morphology of words, by assigning a distinct vector to each word.
这个缺陷在一些词库较大,且生僻字较多的语言中更为明显,解决这个问题就是从字符来进行向量的表示(每个字符映射为一个向量,然后组合为词,C2W模型也是想解决这个问题)。
但是有一个问题,如果用字符来做这个事情太细,速度很慢。
解决方案
In this paper, we propose a new approach based on the skipgram model, where each word is represented as a bag of character n-grams. A vector representation is associated to each character n-gram; words being represented as the sum of these representations.
将单词进行分解,分解为n-gram的形式,然后分别进行表征,最后求和(当然也可以求平均,但是原文用求和,估计平均效果不好)
具体做法(以原文的例子看):
取n=3,即3-gram;
每个单词前后都加上尖括号<>,而且这两个符号还参与到单词的计算中(加这个可以区分前缀还是后缀);
以单词【where】为例,拆分为3-gram的表示后:
< w h , w h e , h e r , e r e , r e > , < w h e r e >
注意这里加上了整个单词本身的表示,这里subword中的her和单词 < h e r >
然后学习每个subword的向量表示,然后把所有subword向量求和得到单词【where】的表示。
原文中把3-gram,4-gram,5-gram,6-gram,都整出来了,因为要考虑不同长度的前后缀(由于用的子词很多,所以这里也用了hashing trick)。6已经够长的,没有什么前后缀超过6。当然,所有subword的特征都是可以共享的。
然后计算scoring function:
s ( w , c ) = ∑ g ∈ g w z g ⊤ v c s(w,c)=\sum_{g\in g_w}z_g^\top v_c s(w,c)=g∈gw∑zg⊤vc
其中 z g z_g zg是n-gram的subword的向量
v c v_c vc是中心词向量表示
用上面的例子,也就是用词【where】取预测 < w h , w h e , h e r , e r e , r e > , < w h e r e >
根据原文理解:给定一个n-gram的sub word字典,字典大小为 G G G,对于某个单词 w w w,可以拆分为 g w g_w gw的sub word集合。我们将字典每个n-gram的sub word g g g用向量 z g z_g zg表示。然后可以计算scoring function,目标是分数越高越好。
Sub Word模型的训练
以单词【where】为例,拆分为3-gram的表示后:
< w h , w h e , h e r , e r e , r e > , < w h e r e >
然后将上面的Sub Word向量由字符向量来表示,求平均得到中心词 v c v_c vc,然后用 v c v_c vc来预测 < w h , w h e , h e r , e r e , r e > , < w h e r e >
实验
Subword词向量的词相似度实验。
其中sisg-是对于OOV没有处理,sisg将OOV词也输出了对于的向量表示。

复现
代码结构

数据集
AG News:https://s3.amazonaws.com/fast-ai-nlp/ag_news_csv.tgz
DBPedia:https://s3.amazonaws.com/fast-ai-nlp/dbpedia _csv.tgz
Sogou news:https://s3.amazonaws.com/fast-ai-nlp/sogou_news_csv.tgz
Yelp Review Polarity:https://s3.amazonaws.com/fast-ai-nlp/yelp_review_polarity_csv.tgz
Yelp Review Full:https://s3.amazonaws.com/fast-ai-nlp/yelp_review_full_csv.tgz YahoolAnswers:https://s3.amazonaws.com/fast-ai-nlp/yahoo_answers_csv.tgz
Amazon Review Full:https://s3.amazonaws.com/fast-ai-nlp/amazon_review_full_csv.tgz
Amazon Review Polarity:https://s3.amazonaws.com/fast-ai-nlp/amazon_review polarity _csv.tgz
数据加载
·数据集加型
·读取标签和数据
·创建word2id
·将数据转化成id
如果使用了2-gram:

list中就是这个样子,红线画出来的就是2-gram,当我们在模型中额外加入n-gram信息后,需要对句子的长度进行加长设置,加大句子length。
# coding:utf-8
from torch.utils import data
import os
import csv
import nltk
import numpy as np
# 继承自torch.utils.data.DataLoader
class AG_Data(data.DataLoader):
def __init__(self, data_path, min_count, max_length, n_gram=1, word2id=None, uniwords_num=0):
self.path = os.path.abspath(".")
if "data" not in self.path:
self.path += "/data"
self.n_gram = n_gram
self.load(data_path)
if word2id == None:
self.get_word2id(self.data, min_count)
else:
self.word2id = word2id
self.uniwords_num = uniwords_num
self.data = self.convert_data2id(self.data, max_length)
self.data = np.array(self.data) # sample_num*length
self.y = np.array(self.y) # sample_num*1
# 读取标签和数据
def load(self, data_path, lowercase=True):
self.label = []
self.data = []
with open(self.path + data_path, "r") as f:
# 读取文件,指定分隔符以及指定引号内的东西就是数据
datas = list(csv.reader(f, delimiter=',', quotechar='"'))
for row in datas:
# 第一列是标签,由于标签要从0开始,所以这里要减一。然后把label放到list里面
self.label.append(int(row[0]) - 1)
txt = " ".join(row[1:])
if lowercase:
txt = txt.lower()
txt = nltk.word_tokenize(txt) # 将句子转化为词
new_txt = []
for i in range(0, len(txt)):
for j in range(self.n_gram): # 添加n-gram词
if j <= i:
new_txt.append(" ".join(txt[i - j:i + 1]))
self.data.append(new_txt)
self.y = self.label
# 获得word2id
def get_word2id(self, datas, min_count=3):
word_freq = {}
for data in datas:
for word in data: # 首先统计词频,后续通过词频过滤低频词
if word_freq.get(word) != None:
word_freq[word] += 1
else:
word_freq[word] = 1
word2id = {"" : 0, "" : 1}
for word in word_freq:
# 先构建uni-gram,因为hashing trick中uni-gram先处理,不进行hash,那么其他的2-gram以上是由多个词组成,里面有空格。
# 所以,单词中不包含空格的就是uni-gram(这里的条件是忽略包含空格的词)
if word_freq[word] < min_count or " " in word:
continue
word2id[word] = len(word2id)
self.uniwords_num = len(word2id)
# 构建2-gram以上的词,需要用hash
for word in word_freq:
if word_freq[word] < min_count or " " not in word:
continue
word2id[word] = len(word2id)
self.word2id = word2id
def convert_data2id(self, datas, max_length):
for i, data in enumerate(datas):
for j, word in enumerate(data):
if " " not in word:
datas[i][j] = self.word2id.get(word, 1)
else:
# hashing trick
datas[i][j] = self.word2id.get(word, 1) % 100000 + self.uniwords_num
# datas[i][j] = self.word2id.get(word, 1)
datas[i] = datas[i][0:max_length] + [0] * (max_length - len(datas[i]))
return datas
def __getitem__(self, idx):
X = self.data[idx]
y = self.y[idx]
return X, y
def __len__(self):
return len(self.label)
if __name__ == "__main__":
ag_data = AG_Data("/AG/train.csv", 3, 100)
print(ag_data.data.shape)
print(ag_data.data[-20:])
print(ag_data.y.shape)
print(len(ag_data.word2id))
模型构建
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# 非常简单的模型,一共包含三层
class Fasttext(nn.Module):
def __init__(self, vocab_size, embedding_size, max_length, label_num):
super(Fasttext, self).__init__()
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embedding_size)
# 平均pool
self.avg_pool = nn.AvgPool1d(kernel_size=max_length, stride=1)
# FC层
self.fc = nn.Linear(embedding_size, label_num)
def forward(self, x):
x = x.long()
# shape:batch_size*length*embedding_size
out = self.embedding(x)
# shape:batch_size*embedding_size*length
out = out.transpose(1, 2).contiguous()
# shape:batch_size*embedding_size
out = self.avg_pool(out).squeeze()
# shape:batch_size*label_num,label_num是分类数量
out = self.fc(out)
return out
if __name__ == "__main__":
fasttext = Fasttext(100, 200, 100, 4)
x = torch.Tensor(np.zeros([64, 100])).long() # 这里注意类型要是long型
out = fasttext(x)
print(out.size())
训练和测试
代码略

这里的速度和论文中描述的有些差别,因为原文用的C++,这里用的python,所以一个epoch大概1分多。
作业
寻找网络资源,写出霍夫曼二叉树的算法推导。
写出,n-gram的hash算法步骤。
为什么hierarchy softmax的算法复杂度需要分训练以及测试两个环节讨论?
Fastext为何能取得这么好的结果,试分析原因?
完善代码,划分验证集,加入early stopping,在其他7个数据集中选取一个进行测试。
总结Fasttext模型以及Fasttext楼型的代码实现。