【7 月 7 日开课】Python 进阶版硬核课程【王的机器出品】

本次课是整套 Python 第二阶段的课。我把整套知识体系分成四个模块:
Python 基础: 已直播完 (录播已上传),点击【课程介绍】和【课后复盘】看详细信息
Python 数据分析:这次的课程,NumPy, Pandas, SciPy
Python 数据可视化:Matplotlib, Seaborn, PyEcharts
Python 机器学习:Scikit Learn, Keras
上面提到的四个模块见下图:


课程内容
本次课程一共 16 节,每节 90 分钟:
2 节讲用于数组计算的 NumPy
2 节讲用于数据分析的 Pandas
2 节讲用于科学计算的 SciPy
10 节讲金融案例 (如何用 NumPy, Pandas, SciPy 来解决实际问题)
2 节数据分析
用 split-apply-combine 分析房产数据
从 Tick 到 Bar 采样高频数据
2 节热门课题 - 追两大热点
LIBOR 被 SOFR 取代 (曲线构建)
负利率负油价 (模型转换)
2 节产品定价 - 定价奇异衍生品
投行产品百慕大期权 (蒙特卡洛模拟)
私募产品 Autocallable/KIKO (偏微分方程有限差分)
2 节风险管理
私人银行中外汇交易组合保证金制定框架 (Greeks/VaR)
商业银行中信用组合的经济资本计量 (默顿模型)
2 节量化投资
构建完整的量化交易框架 (个人投资)
风险平价 + Crash CAPM (资产配置)
课表如下:

教课理念
抛开那 10 节金融案例课,有个人可能会问 NumPy-Pandas-SciPy 不都是免费资源吗,为什么还要花钱来上课?没错,我也是参考了大量书籍、优质博客和付费课程中汲取众多精华,才打磨出来的前六节课。
我先来谈谈我的学习思路和教课理念,看是不是符合你的胃口:
WHY:为什么会有三者?
每一个工具包的创建必是解决痛点。
WHAT:三者是什么?
NumPy 和 Pandas 是数据结构
SciPy 是基于 NumPy 添加的功能。
HOW:怎么去学三者?
对于数据结构,无非从“创建-存载-获取-操作”这条主干线去学习,当然面向具体的 NumPy 数组和 Pandas 数据帧时,主干线上会加东西。
对于功能,无非从它能干什么而目的导向去学习,比如如何插值,如何积分,如何优化,等等。
HOW WELL:怎么学好三者?
需要你们用心去学(必要条件)
需要我用心去准备(充分条件)
接下来看我的表演。
NumPy
WHY
看下面数组和列表之间的计算效率对比:两个大小都是 1000000,把每个元素翻倍,运行 10 次用 %time 记时。(前者比后者快 20-30 倍)
%%time
lst = list(range(1000000))
for _ in range(10):
my_list = [x * 2 for x in lst]
Wall time: 1.2 sarr = numpy.arange(1000000)
for _ in range(10):
my_arr = arr * 2
Wall time: 34.9 msWHAT
NumPy 数组是一种数据结构。很多资料都从它的表象开始教,比如一维、二维、多维数组长什么样子。但这都不是本质,NumPy 数组的本质是“计算机内存的连续一维段 (1D segment),并与若干个指针一起来在视图中展示高维度”。
听着很绕口,但这样理解数组之后很多问题都可以轻易理解,比如:
高维数组的转置
数组的重塑和打平
不同维度上的整合
我为上面那句话画了三幅图,注意比较数组“想象中的样子”、“打印出的样子”和“内存里的样子”。

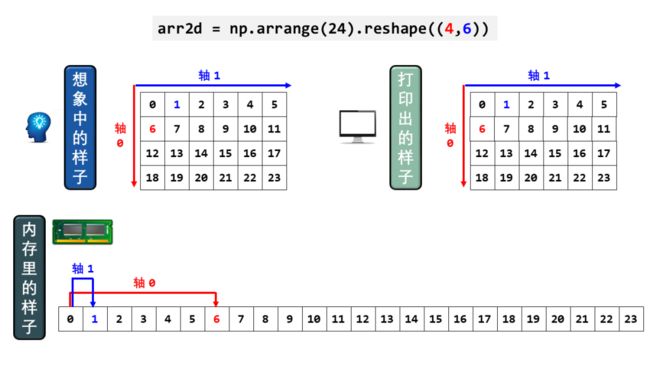
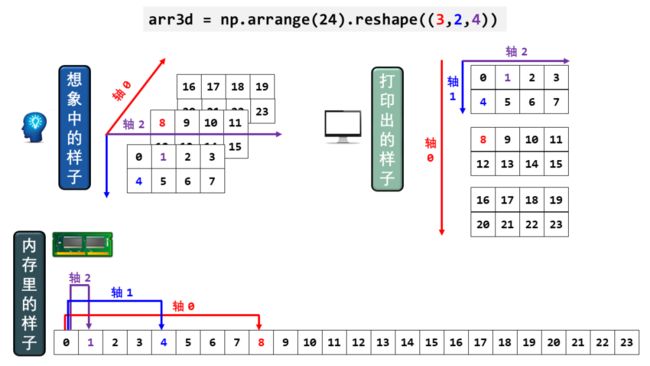
看懂之后,你会了解 NumPy 数组其实就是一连串横向的元素,用指针来控制维度 (axis) 和每个维度包含的元素个数 (shape)。
HOW
了解完数组本质之后,就可以把它当做对象(Python 中万物皆对象嘛)把玩了:
怎么创建数组 (不会创建那还学什么)
怎么存载数组 (存为了下次载,载的是上回存)
怎么获取数组 (和索引切片列表相似又不相似)
怎么变形数组 (把数组用不同的样子来展示)
怎么计算数组 (这才是数组的最大用处)
总体内容用思维导图来表示,这也是我经常强调的系统化学东西。有了总体框架,你在接触到繁多的细节时才会把握主干线。
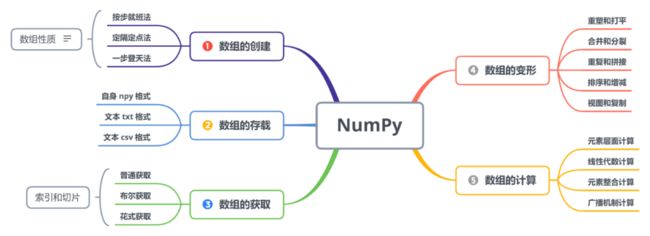
HOW WELL
上面提到了要学好,不仅仅需要你们用心学,也需要我用心教。对于一切难点,我都会将其可视化,这样会大大降低了你们的理解门槛。
比如在讲广播机制时,下面的一图胜千言。
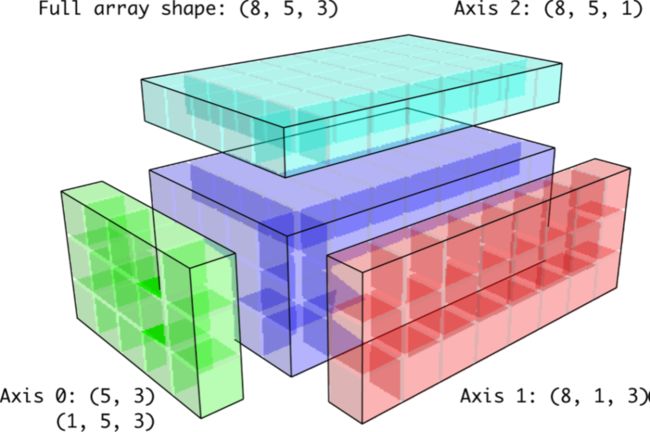
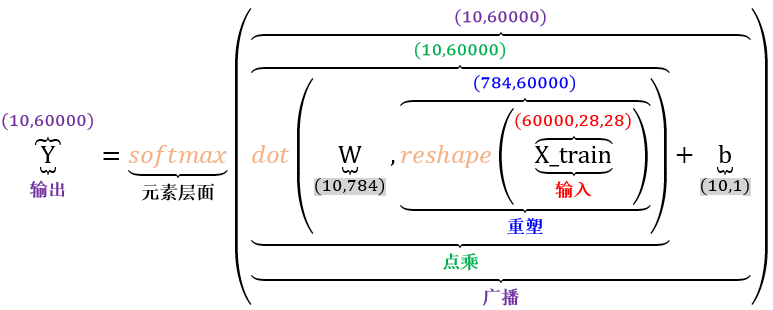
比如在讲数组计算时,用神经网络中一个公式可把重塑 (reshape)、点乘 (dot)、广播 (broadcast) 和元素层面 (element-wise) 几个知识点一次性捋清。
其实我觉得这个“课程推广”帖子就已经很多干货了  。你们看到哪个广告贴会这么用心的去写
。你们看到哪个广告贴会这么用心的去写  ?
?
Pandas
WHY
下图左边的「二维 NumPy 数组」 仅仅储存了一组数值 (具体代表什么意思却不知道),而右边的「数据帧 DataFrame」一看就知道这是平安银行和茅台从 2018-1-3 到 2019-1-3 的价格。

Pandas 的数据结构在每个维度上都有可读性强的标签,比起 NumPy 的数据结构涵盖了更多信息。
此外 Pandas 主要是为异质 (heterogeneous) 的表格 (tabular) 数据而设计的,而 NumPy 主要是为同质 (homogeneous) 的数值 (numerical) 数据而设计的。
WHAT
Pandas DataFrame 是一种数据结构 (Series 可不严谨的看成一维的 DataFrame,而 Panel 已经被废弃)。DataFrame 数据帧可以看成是
数据帧 = 二维数组 + 行索引 + 列索引
在 Pandas 里出戏的就是行索引和列索引,它们
可基于位置 (at, loc),可基于标签 (iat, iloc)
可互换 (stack, unstack)
可重设 (pivot, melt)
HOW
了解完数据帧本质之后,我们可从 Pandas 功能角度来学习它:
数据创建 (不会创建那还学什么)
数据存载 (存为了下次载,载的是上回存)
数据获取 (基于位置、基于标签、层级获取)
数据结合 (按键合并、按轴结合)
数据重塑 (行列互转、长宽互转)
数据分析 (split-apply-combine, pivot_table, crosstab)
数据可视 (df.plot( kind='type') )
数据处理 (处理缺失值和离群值、编码离散值,分箱连续值)
总体内容用思维导图来表示。

HOW WELL
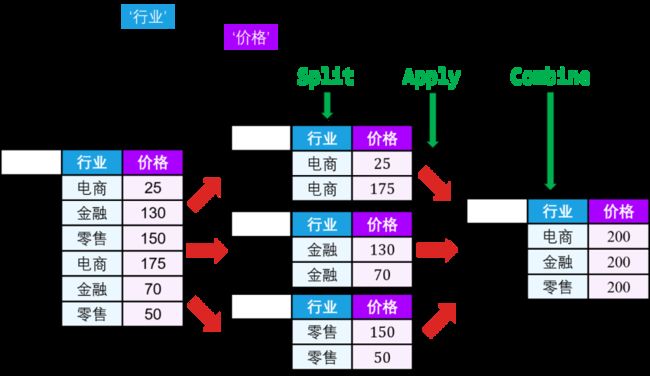
比如在讲拆分-应用-结合 (split-apply-combine) 时,我会先从数据帧上的 sum() 或 mean() 函数引出无条件聚合,但通常希望有条件地在某些标签或索引上进行聚合。这时数据会根据某些规则分组 (split),然后应用 (apply) 同样的函数在每个组,最后结合 (combine) 成整体。
这波操作称被 Hadley Wickham 称之为拆分-应用-结合,具体而言,该过程有三步:
在 split 步骤:将数据帧按照指定的“键”分组
在 apply 步骤:在各组上平行执行四类操作:
整合型 agg() 函数
转换型 transform() 函数
筛选型 filter() 函数
通用型 apply() 函数
在 combine 步骤:操作之后的每个数据帧自动合并成一个总体数据帧
一图胜千言:
SciPy
WHY
NumPy 是数据结构,而 SciPy 是基于该数据结构的科学工具包,能够处理插值、积分、优化、常 (偏) 微分方程数值求解、信号处理、图像处理等问题。
此外,原来 SciPy 底下的子工具包 scipy.stats.models 也独立成为 statsmodels 包,它提供了一套完整回归体系,具体操作包括数据访问方式,拟合,绘图和报告诊断。
WHAT / HOW
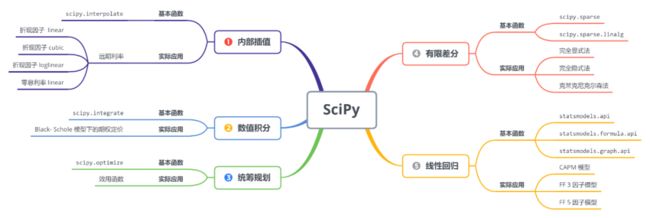
既然 SciPy 偏向功能,我就从金融方向用到最多的几个功能来介绍 SciPy:
插值:scipy.interpolate
积分:scipy.integrate
优化:scipy.optimize
PDE:scipy.sparse
回归:statsmodels.api
对于以上每种功能,我的想法是先用一个简单例子来介绍如何去用子工具包,再用一个金融例子来巩固学到的东西。
插值:计算远期利率
积分:计算期权价值
优化:最大化效用
PDE:有限差分 - 完全显式、完全隐式和克莱克尼克尔森
回归:CAPM, FF 3 因子, FF 5 因子
总体内容用思维导图来表示。
HOW WELL
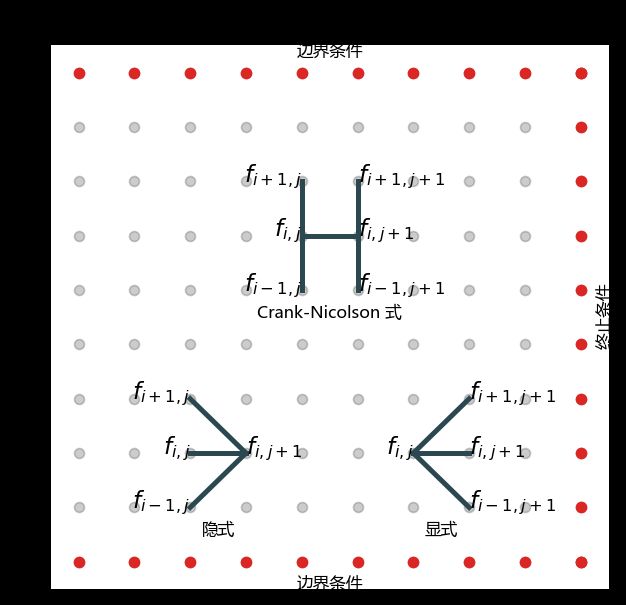
偏微分方程有限差分 (finite difference, FD) 算是金融工程中比较难学的,但我会讲里面所有难懂的概念可视化出来。下图可是我用 matplotlib 写代码画出 (敢问谁会这么用心来这么做) 用 FD 求解 PDE 所了解的核心元素:
网格:空间维度的 S (对应标的资产价格),时间维度的 t (对应衍生品到期日)
终止条件:任何金融产品都是支付函数,可设为 PDE 的终止条件
边界条件:很多金融产品的支付在标的很大或很小时会确定比如看涨期权
在标的为零时支付为零
在标的很大时近似为一个远期。
求解格式:完全显式 (explicit)、完全隐式 (implicit) 和克莱克尼克尔森 (Crank-Nicolson)
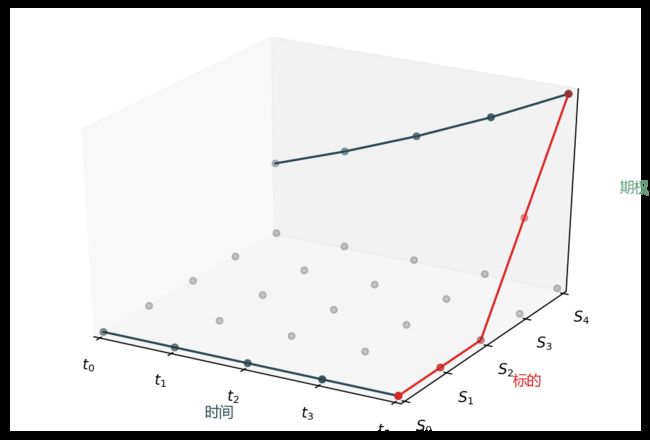
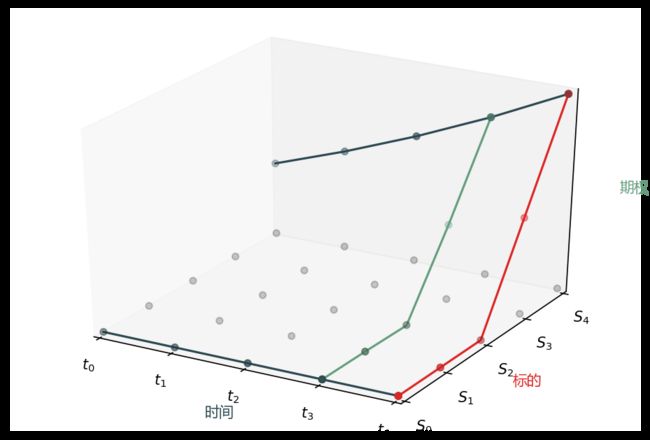
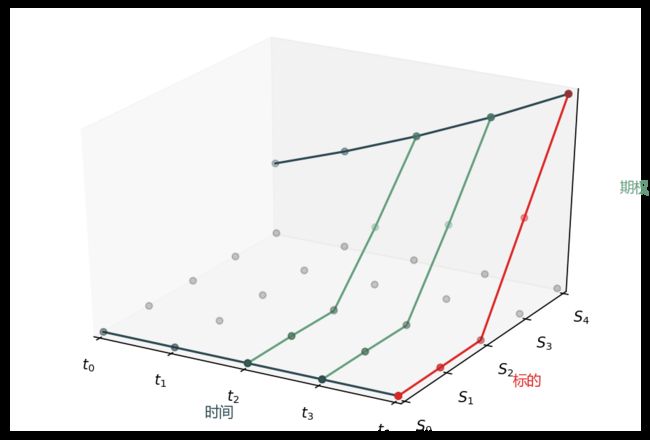
在求解 PDE 时,我只说五句话,配着下面的图 (也是用 matpplotlib 写代码画的)。
水平面上的灰点是网格
红线是终值条件 (产品在到期日支付函数)
两条深青线是边界条件 (产品在标的上下界时的支付)
蓝点是期权值 (产品在 0 时点的值)
从 T4 到 T0 一步步解的 (从后往前解)
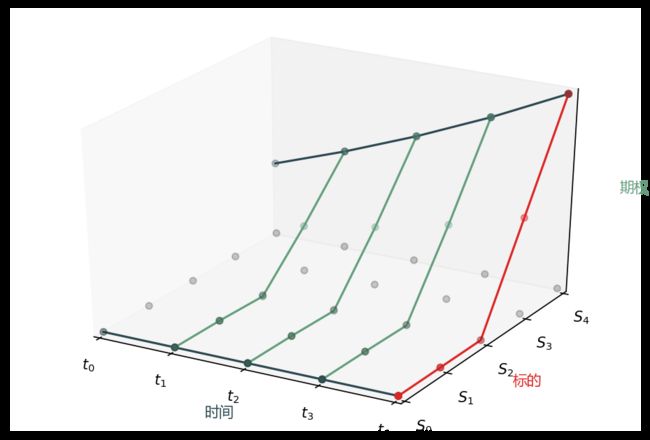
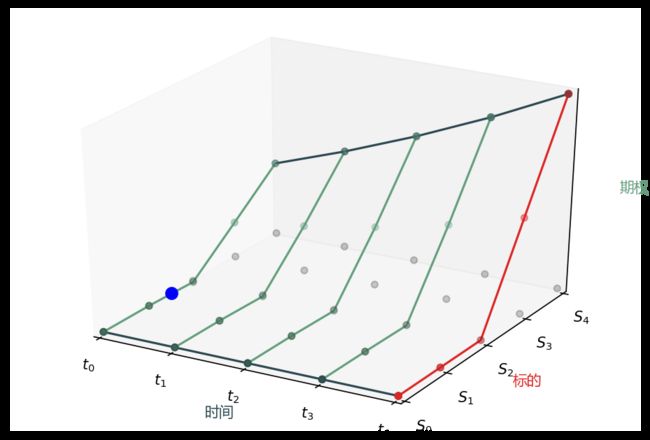
以上步骤弄明白了,要得到更精确的值,需要把 S 和 t 轴上的点打的更密就完事了,你看,其他书讲的很难懂的 PDE FD 我用几张简图可视化一下就好懂多了吧。
FD 对于定价标的少于 4 个的金融衍生品是个很好的方法:
高效:和蒙特卡洛方法比快很多
稳定:和蒙特卡洛方法比稳很多
普适:对于不同产品整个求解过程几乎一样,不同的就是设定不同的上下界、终止条件和边界条件。
十大案例我就不多说了,有的是我亲自为客户做过的项目 (当然讲出来的时候会修改数据),有的是私募的朋友要发行产品让我帮其估值,有的是业界 best practice。最值钱的是这些案例,除了将 NumPy, Pandas 和 SciPy 应用在金融上,你还能学到各种关于产品定价、风险管理、量化投资等金融工程的知识。 只要你们认真学习这些案例,听完之后可以做很多金融从业者做的事情了。
报名方式
扫描下方二维码即可报名
????????????
海报上的信息有些让人困惑,在这里说明吧:
全套课原价 6,000 人民币
早鸟时期 (一个月) 报名半价 - 3,000
上过基础课学员可再打六折 - 1,800
推荐两个学员,免费上进阶课
学生注册后会在账号中得到专属分享码
假设 A 可以分享课程给其他同学们
只要另外两个 B 和 C 在购课时用该分享码
那么 A 的这门课程将会得到全额退款
扫完二维码会看到这个界面
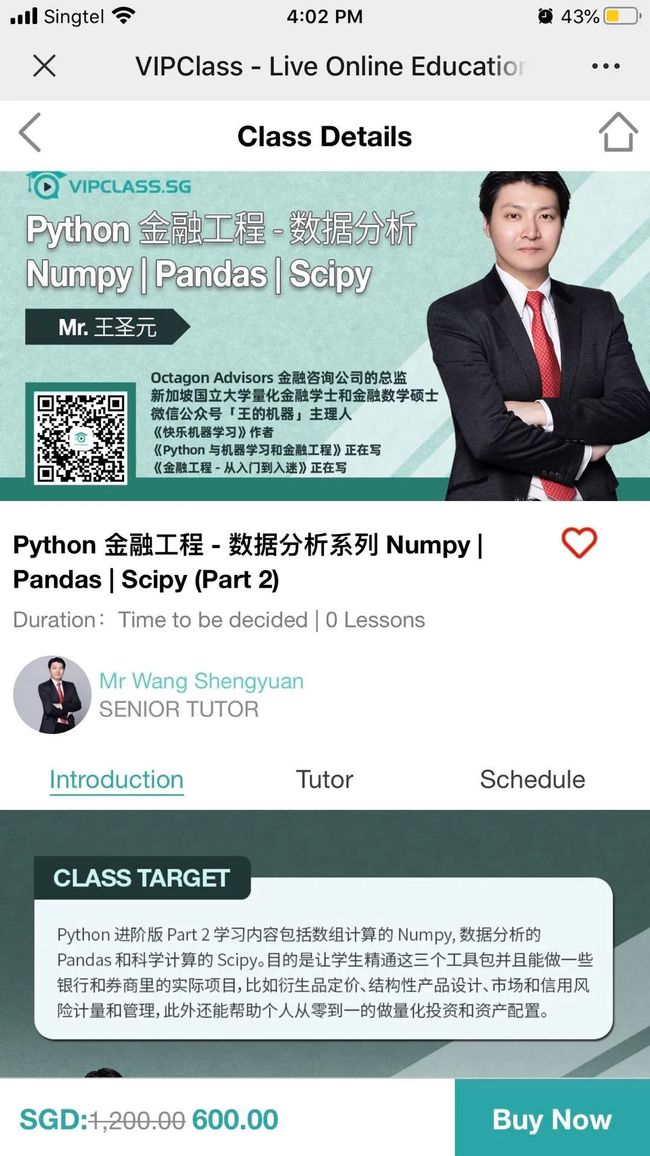
价格是早鸟时期的 600 新币 = 3000 人民币
点击 Buy Now 会跳到 VIPCLASS 的登录界面
对于已经购买基础课的同学
登录就可以看到下个界面
复制优惠码来购买
就能再额外享受六折
报名只需 1800 人民币
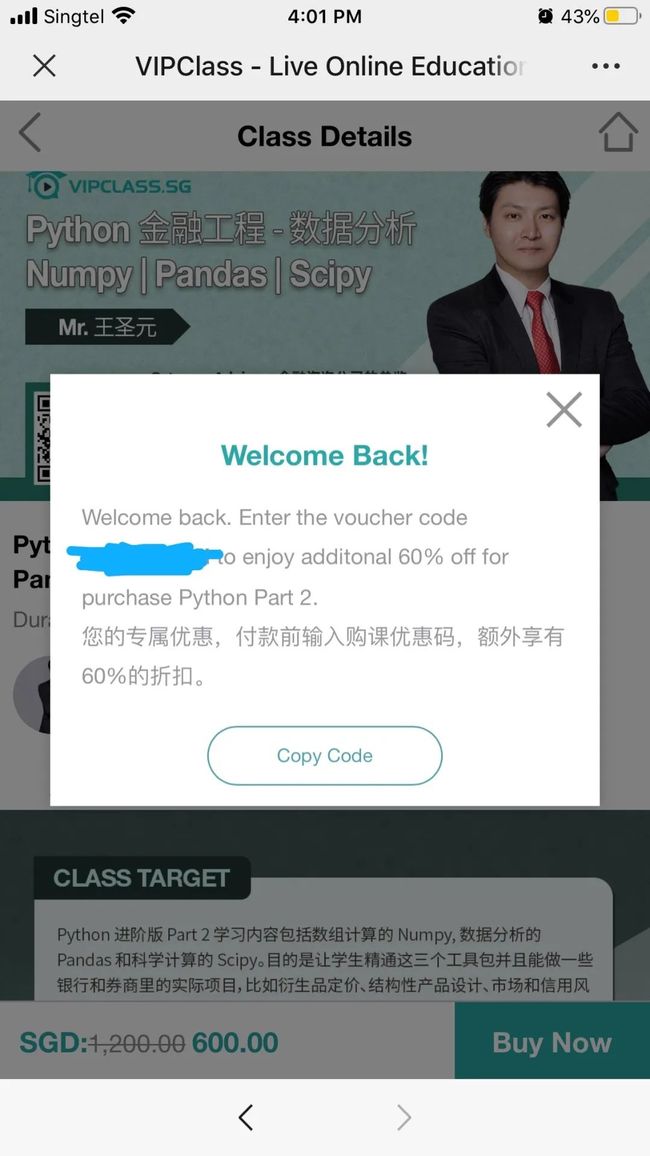
早鸟时期一过就会恢复原价
报名了同学在公众号对话框回复购买信息
我来拉群,同时也加你为微信好友
授课时间
2020 年 7 月 7 日开课
每周二和周五晚上 8 点直播
每堂课 90 分钟
之后也有视频录播
如果你同意我的教课理念,看过并喜欢我的文章,也相信我的课程质量,那么就来报名吧,让我来给(再给)你一次不一样的超硬核的 Python 课。