Redis基础入门知识
Redis是非关系型的数据库
1、关系型数据库SQL与非关系型数据库NoSQL的区别:
SQL的特点:
1、以表格的形式存储格式化的数据,是一个二维表的数据结构
2、严格遵循数据格式和长度的规范
3、表与表之间存在关联关系(主键、外键【都是相对的关系】)
4、数据以行为单位,一行数据表示一个实体类,每一行的数据属性是相同的
优点:易理解、操作方便、数据一致性、数据稳定、服务稳定。
缺点:高并发下IO压力大、为维护索引付出的代价大、为维护数据的一致性付出的代价大、水平扩展困难、表结构扩展不方便、全文搜索功能弱
KV型的NoSQL(Not Only SQL,这里主要讲解的就是redis)的特点:
1、以键值对进行存储
优点:数据基于内存,读写的效率高;KV型数据,时间复杂度为O(1),查询速度快
缺点:只能根据K查询V,查询方式单一,内存有限,无法支持海量的数据存储,由于是基于内存进行存储,会有丢失数据的风险。
这种搜索型的NoSQL最适合的场景就是:有条件搜索尤其是全文的搜索。
2、Redis的特性
相关的网站:
中文网站:https://www.redis.net.cn/
官方网站:https://redis.io/
1、基于内存存储,读写速度快
2、支持数据的持久化,过期策略;持久化:可以将内存中的数据保存到磁盘中,重启时进行加载使用;过期策略:在保存数据的时候设置数据的过期时间,一旦数据过期就会从内存中删除掉。
3、支持存储多种的数据类型:List、Set、ZSet、Hash.........
4、支持数据的备份,即master-slave模式
5、支持事务,redis中的所有操作都是原子性的,同时Redis支持对几个操作合并之后的原子性操作【单线程的】。
6、支持多种编程语言。
7、高可用,集群操作配置简单。
3、redis中常用的数据类型
默认有16个库【0=15】

String字符串,List集合 、Set集合、HSet、Hash
参考命令:http://redisdoc.com/index.html
存储原理:redis 是KV键值对存储的数据库,通过hashtable 实现,所以每个键值对都会有一个dictEntry,里面指向了key 和 value的指针。next指向的是下一个dictEntry键值对节点.
对应的dictEntry源码:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct redisObject {
unsigned type:4; //对象的类型,OBJ_STRING/OBJ_LIST/OBJ_HASH/OBJ_SET/OBJ_ZSET
unsigned encoding:4; //具体的数据结构编码
unsigned lru:LRU_BITS; /* 内存淘汰策略:
LRU time 最近被使用 (relative to global lru_clock) or
* LFU data 最近的使用频率(least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; /*引用计数,当refcount为0 时,表示该对象已经不被任何对象引用,可以进行垃圾回收*/
void *ptr; /*指向对象实际的数据结构*/
} robj;
dictEntry的结构图:
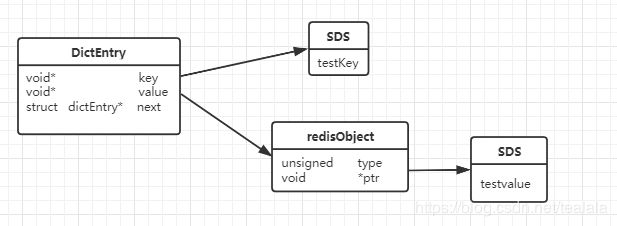
对应的redisObject 源码:
3.1 String字符串类型
用来存储字符串,整型、浮点型。
内部编码有三种:
1、int类型,存储8个字节的长度(long,2^63-1)
2、embstr,代表embstr格式的SDS(Simple Dynamic String简单动态字符串),存储小于44个字节的字符串。
3、raw,存储大于44个字节的字符串
SDS(Simple Dynamic String)是什么?
是redis中使用最多的一个基础字符串数据结构,
Redis中的字符串的实现
为什么Redis要用SDS实例?
在C语言中本身是没有字符串类型的,只能使用字符数组char[]来实现。
1、使用字符数组必须给目标变量分配足够的空间,否则会出现溢出的现象。
2、如果要获取字符的长度,必须遍历字符数组,时间的复杂度就是O(n)。
3、字符串长度的变更会对字符数组重新进行内存分配。
4、通过从字符串开始到结束碰到的第一个'\0'来标记字符串的结束,因此不能保存图片,音频,视频,压缩文件等二进制bytes保存的内容,二进制不安全。
SDS的特点:
1、可以动态扩展内存,SDS表示的字符串内容可以进行修改,也可以追加,不用担心内存溢出的问题,如果需要SDS会自动进行扩容。
2、二进制安全(Binary Safe)的数据结构,sds 可以存储任意的二进制数据,而不仅仅是可打印的字符。
3、获取字符串长度的时间复杂度为O(1),因为其中有len属性,用来存储当前字符数组的长度。
4、通过空间预分配和惰性空间释放,防止多次重新分配内存。
5、判断是否结束的标志是len属性。
embstr和raw的区别?
embstr是只读的,使用只分配一次内存空间,删除只释放一次空间,(RedisObject和SDS是连续的)寻找方便,而raw需要分配两次内存空间(分别为RedisObject和SDS分配空间)。
int与embstr什么时候转化为raw?
当int数据不再是整数,或者大小超过了long的范围时,自动转换成embstr。 只要对embstr类型的数据进行修改都会转化为raw,无论是否超过44个字节。因为embstr是只读,只会对它分配一次内存。
String的应用场景
缓存、分布式Session、实现分布式锁、incr 全局ID、计数器、限流、位操作
3.2 Hash哈希类型
存储类型:包含键值对的无序散列表,value只能是字符串,不能嵌套其他的类型
hash 与 String的主要区别?
将所有的相关的值聚集到一个key中,节省空间,减少key冲突,获取值时只需要使用一个命令,减少内存、IO、CPU的消耗。
但是不能单独设置过期时间,不能进行位操作,需要考虑数据量分布的问题。
hash的存储结构
1、ziplist压缩列表:OBJ_ENCODING_ZIPLIST
2、hash哈希表:OBJ_ENCODING_HT
ziplist 是一个经过特殊编码的双向链表,不存储指向上一个链表节点和下一个链表节点的指针,而是存储上一个节点和当前节点的长度,牺牲了部分的读写性能,来换取高效的内存空间利用率,是一种时间 欢空间的思想。只用在字段个数少,字段值小的场景。
hashtable被称为数据字段dictionary,是一个数组+链表的结构。
从最高层到最底层分别为:
OBJ_ENCODING_HT--->dict--->dictht--->dictEntry
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
什么时候使用ziplist存储?
当所有的键值对的键和值的字符串长度都小于或等于64byte;哈希 对象保存的键值对数量小于512个。
何时触发扩容?
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5;
dict_force_resize_ratio = used/size 已经使用的节点/字典大小,当比例大小超过5并且dict_can_resize = 1 的时候就会触发扩容操作。
扩容判断:
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
扩容操作:
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
应用场景:
存储对象类型或者表数据,例如收藏夹,购物车,
3.3 List列表
存储类型:有序的字符串,可以重复,从左到右,左边是列表头;
3.2版本之后 就使用quicklist来存储(链表+ziplist),是一个双向的链表,每个节点都是一个ziplist。
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
使用场景
用来存储有序可重复的数据,例如用户的消息请求
3.4 set无序集合
存储结构:intset、hashtable存储无序,不可重复的String类型数据集合,如果元素都是整数类型的就使用inset类型存储,否则 使用hashtable类型数组+链表的存储结构。
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
应用场景:用户关注,推荐模型,点赞,商品标签
3.5 zset有序集合
存储结构:ziplist、 skiplist+dict
ziplist使用条件:元素的数量小于128个,所有的元素的长度都小于64个字节
否则就是:skiplist+dict来存储
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
应用的场景:排序---排行榜
redis新加的数据类型
保存地理位置的信息:经度和纬度 geo的数据信息
geospatial
hyperloglogs :用于奇数统计
4、redis的发布订阅
1、传统的List类型的数据队列可以使用rpush和lpop来实现消息队列,但是不支持一对多的消息分发。
2、redis中提供了发布订阅模式,实现消息的发送接收。
A、消息订阅者可以订阅多个频道(channel)
subscribe channel_name_1 channel_name_2 channel_name_3
消息发布者一次只能向一个频道发送消息
publish channel_name_1 message
与rabbitMQ中的routing路由模式相似,但是rabbitMQ可以一次向多个队列发送消息
B、同时也提供使用占位符规则来订阅频道
?代表一个字符,*代表0个字符或多个字符
与rabbiyMQ中的topic模式类似。
5、redis的事务
redis中的命令是原子性的,涉及到多个命令的时候,需要将多个命令作为一个处理序列来执行,就需要使用事务;
redis中有两种方式执行事务
A、使用setnx实现分布式 锁,先set设置数据,指定过期时间,防止del发生的时候不会释放锁,业务完成后再del数据。
B、使用multi(开启事务),exec(执行事务),discard(取消事务),watch(监事)来执行事务。
set key value ----> watch key---->multi---->相关的业务操作---->exec
watch命令为事务提供了CAS(Check and Set / Compare and Swap)乐观锁,多个线程在更新变量的时候,会与原值做比较,只有其他线程没有修改该变量的时候,才更新数据。可以同时监视多个key,开启事务之后,如果有一个key在exec执行之前被 修改了,整个事务都会被取消。可以使用unwatch来取消。
事务可能会遇到两种问题
A、在执行exec之前发生错误,队列中的所有的命令都得不到执行。
B、在执行exec之后发生错误,只有错误的命令得不到执行,其他的命令不受影响,并且该事务是不能进行回滚操作的。
6、使用Lua脚本调用redis命令
2.6版本之后就可以使用lua脚本中执行redis命令
1、一次发送多个命令,减少网络的开销
2、原子性
3、组合的复杂命令可以使用file存储,重复使用
执行命令:eval "脚本名称" 参数与参数值 (eval "test" "value")
lua脚本中执行redis命令
redis.call(command,key[param1\param2.....])
command:命令包括:set get del登
key:是被操作的键
param 代表给key的参数
eval "returm redis.call('set', key[1],ARGV[1])"
7、Redis为什么会这么快?
A、KV结构的内存数据库,时间复杂度为O(1)
B、单线程:没有创建线程,销毁线程带来的消耗;避免了上下线文本切换带来的CPU消耗;避免了线程之间带来的竞争问题(加锁,释放锁,死锁);
C、异步非阻塞I/O,多路复用处理并发连接
8、内存回收策略
redis中的所有数据都是存储在内存中的,需要对占用的内存空间进行回收。
有两种情况需要对内存进行回收:
A、key过期进行内存淘汰
B、内存达到上限触发内存淘汰
8.1、过期策略(针对Key值过期)
定时过期(主动淘汰),惰性过期(被动淘汰),定期过期
定时过期:设置了过期时间的key,到了过期的时间就会立即清除,对内存友好,但是会占用大量的CPU资源清除过期的数据,影响缓存的响应时间和吞吐量。
惰性过期:当访问一个key的时候才会判断这个key是否过期,对内存不友好,但是可以大量节省CPU的资源。
定期过期:每个一段时间,会扫描一定数量的expires中的key,并清除过期的key,是以上两种策略的折中方案。
8.2 淘汰策略(针对达到内存上限)
在redis.conf中进行参数配置:maxmemory bytes,也可以进行动态的修改:config set maxmemory 4GB
# volatile-lru -> Evict using approximated LRU among the keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key among the ones with an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
LRU(Least Recently Used)最近最少使用,
volatile-lru:删除设置了超时属性的键,直到腾出了足够的内存;
allkeys-lru:不管有没有设置了超时属性,直到腾出足够的内存为止。
LFU(Least Frequently Used)最近最不常用
volatile-lfu:在带有过期时间的键中选择最不常用的;
allkeys-lfu:在所有的键中删除最不常用的,不管有没有设置超时属性。
random 随机
volatile-random:随机删除设置了超时属性的键;
allkeys-random:随机删除所有的键,直到腾出足够的内存为止;
volatile-ttl:删除最近将要过期的数据
noeviction:不会删除任何的数据,当进行写操作的时候返回一个错误提示。
9、持久化机制
由于reids的数据是存储在内存中的,如果宕机或者断点,内存中的数据就会丢失;
reids中有两种持久话的方案:RDB(默认)、AOF
9.1 RDB
RDB可以手动触发(执行save,bgsave)和自动触发(需要配置触发方案;showdown服务),将内存中的数据写入磁盘,生成一个快照文件dump.rdb。redis在重启的时候就会加载dump.rdb文件进行数据的恢复。
#以下配置不冲突,只需要满足一个就会触发
save 900 1 #900秒内至少有一个key被修改(包括添加)
save 300 10 #300秒内至少有10个key被修改
save 60 10000 #60秒内至少有10000个key被修改
# Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
#是否是LZF压缩rdb文件
rdbcompression yes
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
#开启数据校验
rdbchecksum yes
# The filename where to dump the DB
dbfilename dump.rdb
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir ./
手动触发中save与bgsave的区别:
save:在生成快照的时候会阻塞当前redis服务器,redis不能处理其他的命令。如果内存中的数据比较多的时候,就会造成redis长期的阻塞。
bgsave:reids会在后台进行异步快照操作,同时还可以响应客户端的请求。进程会fork操作,创建子进程,rdb的持久化操作就交给了子进程进行。阻塞只发生在fork阶段,一般时间都比较的短。
优点:数据紧凑,保存了在某个时间点上的数据;在生成rdb文件的时候,交给了子进程,主进程不需要进行任何的磁盘IO操作;在有大量的数据时,恢复速度快;
劣势:不是实时持久化,需要间隔一段时间进行备份(期间数据可能会丢失),因为每次bgsave保存数据时,都会fork创建子进程,频繁的执行,成本太高。
9.2 AOF
开启AOF方式之后,在执行redis数据更改的时候,就会把命令写入到AOF文件中,重启redis的时候,会执行所有的操作来完成数据的恢复。
#默认不开启
appendonly no
# The name of the append only file (default: "appendonly.aof")
#存储的文件名称
appendfilename "appendonly.aof"
由于操作系统是缓存机制的,AOF数据并没有真正的写入到硬盘,而是进入到了系统的硬盘缓存。
#no 表示不执行 fsync,由操作系统保证数据同步到磁盘,速度最快,但是不安全
#always 表示每次写入都执行fsync,以保证数据同步到磁盘,效率很低
#everysec 表示每秒执行一次fsync,可能导致丢失这一秒的数据,通常选择everysec,兼顾安全性和效率
# appendfsync always
appendfsync everysec
# appendfsync no
当AOF文件的大小超过了设定的阀值时,就会启动AOF文件的内容压缩,只保留恢复数据的最小指令集。
# Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
可以使用bgrewriteaof命令来重写,AOF重写并不是对原文的重新整理,而是拂去服务器中的键值对,然后用一条命令代替之前记录这个键值对的多条命令,生成一个新的文件去替换原来的AOF文件。
优点:AOF中提供了多种的同步频率,即使使用的是同步的频率每秒同步一次,redis最多也只丢失1秒的数据。
缺点:AOF文件就会比较大;在高并发的情况下,RDB比AOF具有更好的性能保障。