Spark入门,概述,部署,以及学习(Spark是一种快速、通用、可扩展的大数据分析引擎)
1:Spark的官方网址:http://spark.apache.org/
1 Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
2 Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
2:Spark特点:
1 1:特点一:快 2 与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。 3 2:特点二:易用 4 Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。 5 3:特点三:通用 6 Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。 7 4:特点四:兼容性 8 Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
3:Spark的部署安装(上传jar,过程省略,记得安装好jdk。):
下载网址:http://www.apache.org/dyn/closer.lua/spark/或者 http://spark.apache.org/downloads.html
Spark的解压缩操作,如下所示:

哈哈哈,犯了一个低级错误,千万记得加-C,解压安装包到指定位置。是大写的哦;

然后呢,进入到Spark安装目录,进入conf目录并重命名并修改spark-env.sh.template文件,操作如下所示:
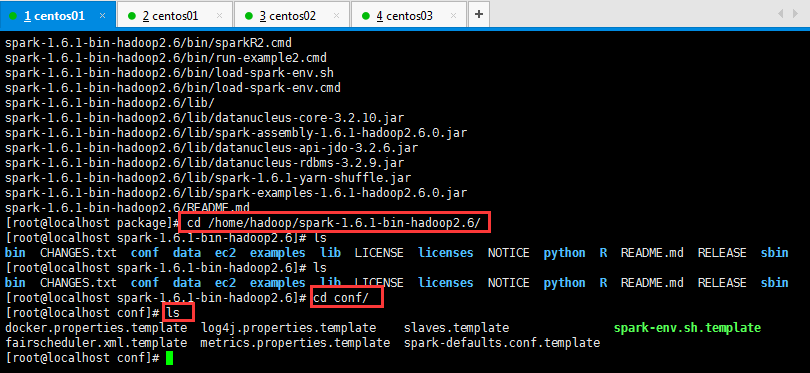
将spark-env.sh.template 名称修改为spark-env.sh,然后在该配置文件中添加如下配置,之后保存退出:
1 [root@localhost conf]# mv spark-env.sh.template spark-env.sh
具体操作如下所示:

然后呢,重命名并修改slaves.template文件,如下所示:
1 [root@localhost conf]# mv slaves.template slaves
在该文件中添加子节点所在的位置(Worker节点),操作如下所示,然后保存退出:
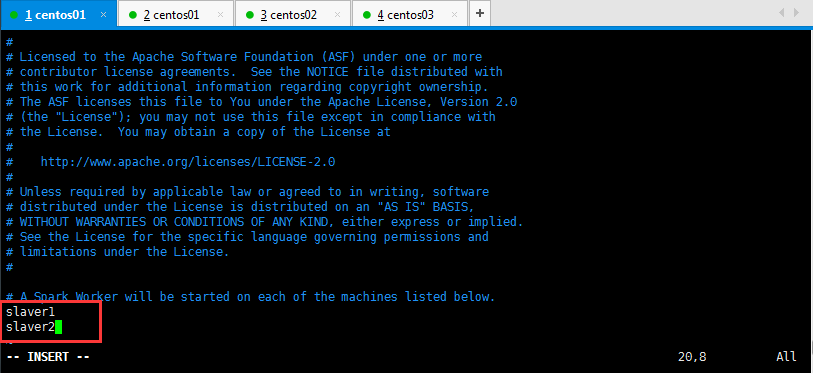
将配置好的Spark拷贝到其他节点上:
1 [root@localhost hadoop]# scp -r spark-1.6.1-bin-hadoop2.6/ slaver1:/home/hadoop/ 2 [root@localhost hadoop]# scp -r spark-1.6.1-bin-hadoop2.6/ slaver2:/home/hadoop/
Spark集群配置完毕,目前是1个Master,2个Work(可以是多个Work),在master节点上启动Spark集群:

启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://master:8080/:
可以查看一下是否启动起来,如下所示:

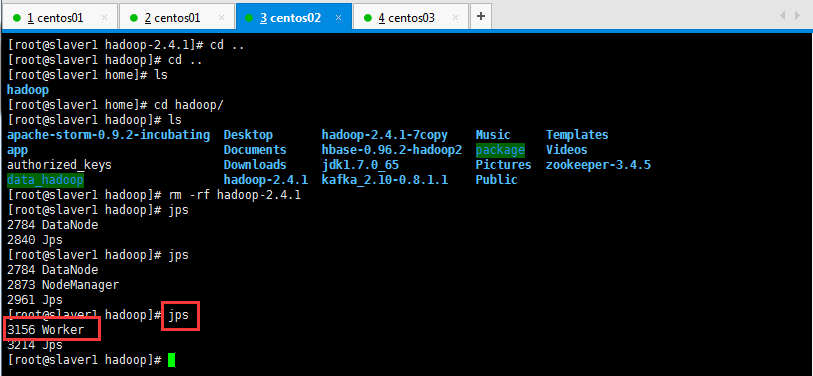
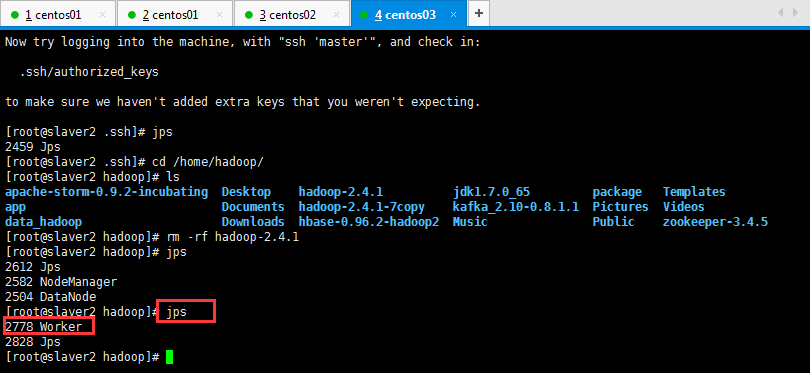
然后在页面可以查看信息,如下所示,如果浏览器一直加载不出来,可能是防火墙没关闭(service iptables stop暂时关闭,chkconfig iptables off永久关闭):
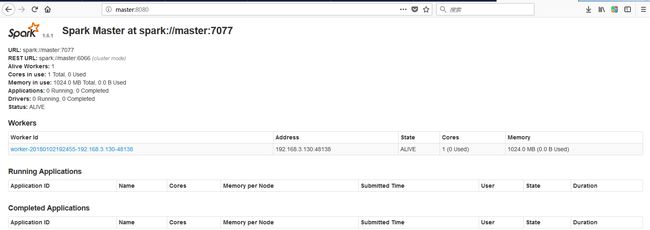
到此为止,Spark集群安装完毕。
1 但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单,如下所示: 2 Spark集群规划:node1,node2是Master;node3,node4,node5是Worker 3 安装配置zk集群,并启动zk集群,然后呢,停止spark所有服务,修改配置文件spark-env.sh, 4 在该配置文件中删掉SPARK_MASTER_IP并添加如下配置: 5 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1,zk2,zk3 -Dspark.deploy.zookeeper.dir=/spark" 6 1.在node1节点上修改slaves配置文件内容指定worker节点 7 2.在node1上执行sbin/start-all.sh脚本,然后在node2上执行sbin/start-master.sh启动第二个Master
4:执行Spark程序(执行第一个spark程序,如下所示):
执行如下所示,然后就报了一大推错误,由于错误过多就隐藏了,方便以后脑补:
1 [root@master bin]# ./spark-submit \ 2 > --class org.apache.spark.examples.SparkPi \ 3 > --master spark://master:7077 \ 4 > --executor-memory 1G \ 5 > --total-executor-cores 2 \ 6 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/l 7 lib/ licenses/ logs/ 8 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar \ 9 > 100 或者如下所示也可: [root@master spark-1.6.1-bin-hadoop2.6]# bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 --executor-memory 512M --total-executor-cores 2 /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar 10
错误如下所示,由于太长了就折叠起来了:
 View Code
View Code
由于之前学习hadoop,虚拟机内存才设置512M了,Spark是在内存中进行运算的,所以学习Spark一定要设置好内存啊,关闭虚拟机,将内存设置为1G,给Spark设置800M的内存,所以spark-env.sh配置,多添加了:
export SPARK_WORKER_MEMORY=800M
如下所示:

然后执行,如下所示命令:
1 [root@master spark-1.6.1-bin-hadoop2.6]# bin/spark-submit \ 2 > --class org.apache.spark.examples.SparkPi \ 3 > --master spark://master:7077 \ 4 > --executor-memory 512M \ 5 > --total-executor-cores 2 \ 6 > /home/hadoop/spark-1.6.1-bin-hadoop2.6/lib/spark-examples-1.6.1-hadoop2.6.0.jar \ 7 > 100
5:启动Spark Shell:
spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
启动spark shell,如下所示:
1 [root@master spark-1.6.1-bin-hadoop2.6]# bin/spark-shell \ 2 > --master spark://master:7077 \ 3 > --executor-memory 512M \ 4 > --total-executor-cores 2 5 6 参数说明: 7 --master spark://master:7077 指定Master的地址 8 --executor-memory 512M 指定每个worker可用内存为512M 9 --total-executor-cores 2 指定整个集群使用的cup核数为2个
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可;
操作如下所示:
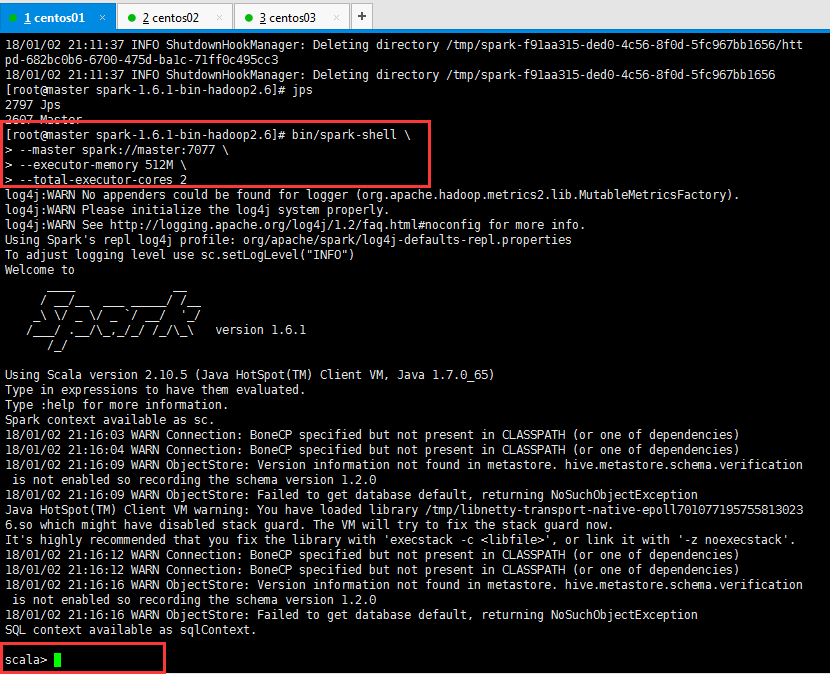
退出使用命令exit即可;
贴一下日了狗了的报错,没有接受指令超过一定时间就报错了,如下所示,按Enter又回到scala> 等待命令键入:
scala> 18/01/03 02:37:36 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] in 1 attempts org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) at scala.util.Try$.apply(Try.scala:161) at scala.util.Failure.recover(Try.scala:185) at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) at scala.concurrent.Promise$class.complete(Promise.scala:55) at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745) Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) ... 7 more 18/01/03 02:39:39 WARN NettyRpcEndpointRef: Error sending message [message = RemoveExecutor(0,Command exited with code 1)] in 2 attempts org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout at org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63) at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59) at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:33) at scala.util.Failure$$anonfun$recover$1.apply(Try.scala:185) at scala.util.Try$.apply(Try.scala:161) at scala.util.Failure.recover(Try.scala:185) at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) at scala.concurrent.Future$$anonfun$recover$1.apply(Future.scala:324) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) at org.spark-project.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293) at scala.concurrent.impl.ExecutionContextImpl$$anon$1.execute(ExecutionContextImpl.scala:133) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) at scala.concurrent.Promise$class.complete(Promise.scala:55) at scala.concurrent.impl.Promise$DefaultPromise.complete(Promise.scala:153) at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) at scala.concurrent.Future$$anonfun$map$1.apply(Future.scala:235) at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.processBatch$1(Future.scala:643) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply$mcV$sp(Future.scala:658) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) at scala.concurrent.Future$InternalCallbackExecutor$Batch$$anonfun$run$1.apply(Future.scala:635) at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72) at scala.concurrent.Future$InternalCallbackExecutor$Batch.run(Future.scala:634) at scala.concurrent.Future$InternalCallbackExecutor$.scala$concurrent$Future$InternalCallbackExecutor$$unbatchedExecute(Future.scala:694) at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:685) at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:40) at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:248) at scala.concurrent.Promise$class.tryFailure(Promise.scala:112) at scala.concurrent.impl.Promise$DefaultPromise.tryFailure(Promise.scala:153) at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:241) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) at java.util.concurrent.FutureTask.run(FutureTask.java:262) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) at java.lang.Thread.run(Thread.java:745) Caused by: java.util.concurrent.TimeoutException: Cannot receive any reply in 120 seconds at org.apache.spark.rpc.netty.NettyRpcEnv$$anon$1.run(NettyRpcEnv.scala:242) ... 7 more