在Google Colab上面进行深度学习的模型训练
在Google Colab上面进行深度学习的模型训练
- 1.使用步骤
- 1.1准备工作
- 1.2修改笔记本属性,并挂载谷歌硬盘。
- 2.在colab上面训练mnist数据集
先简单介绍介绍一下,google colab为我们提供了免费的GPU,感觉类似于服务器之类的,对于学生党来说还是不错的选择的。
步入正题,在我们使用colab之前,得先能够“科学上网”才行,毕竟国内是没办法直接访问google的。
1.使用步骤
1.1准备工作
(1)登录账号进入谷歌云盘,点击新建文件夹,文件夹名称随便去一个都可以,这里我就用的colab。
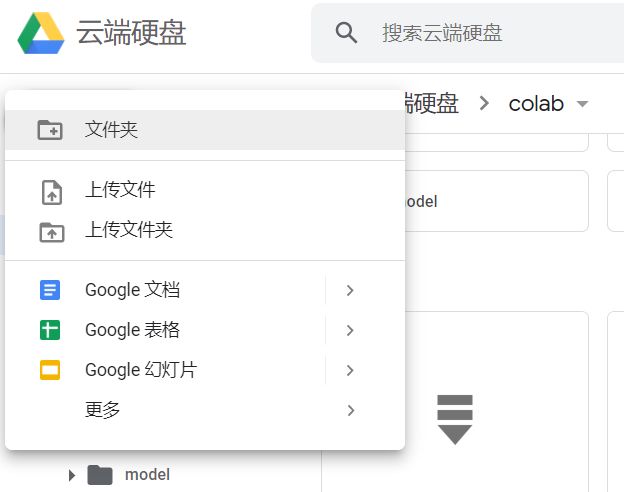
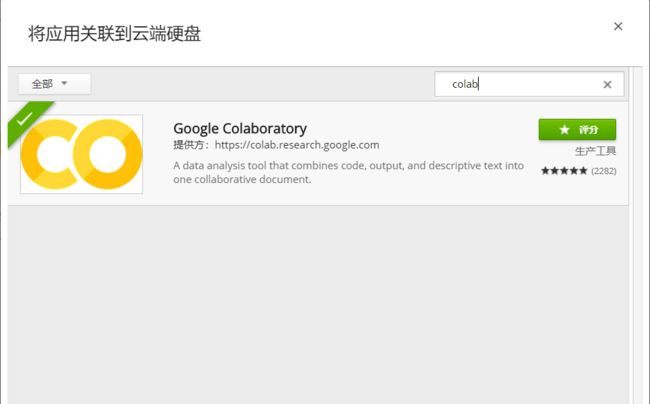
(2)进入到我们新建的文件夹colab中,这里由于我们是第一次进入,我们需要先关联colaboratory,在空白处点击鼠标右键—>点击更多—>点击关联更多应用,然后在搜索框中搜索colab,并进行关联。
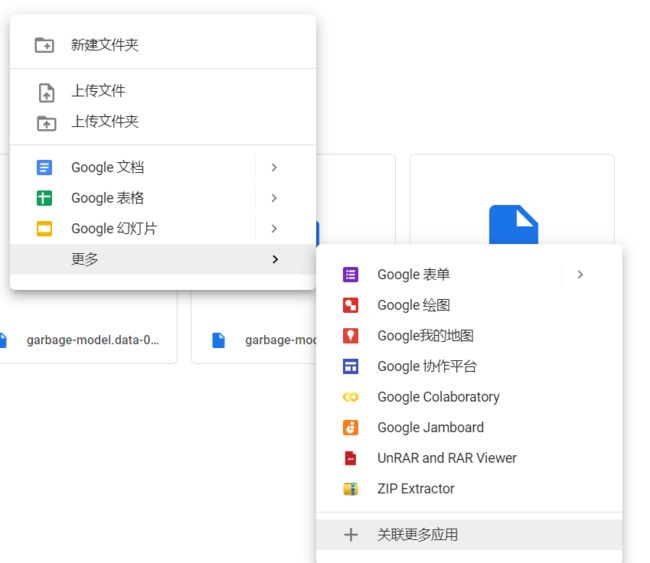
(3)关联完成之后,在空白处点击鼠标右键,点击更多创建Google Colaboratory,创建完成后,会自动生成一个jupyter笔记本。点击左上角即可修改笔记本的名称。

1.2修改笔记本属性,并挂载谷歌硬盘。
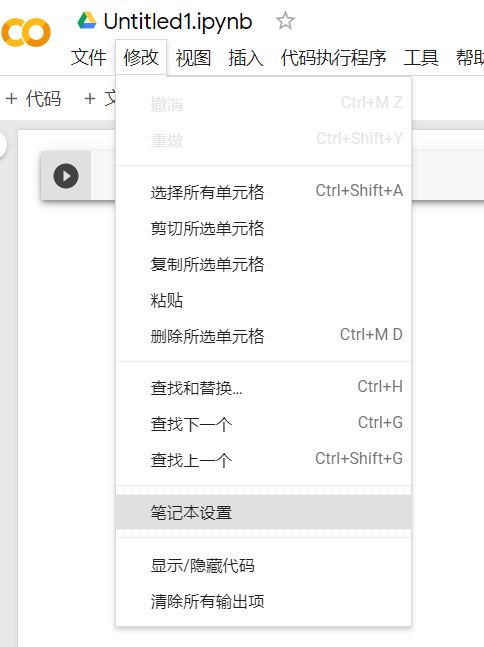
(1)首先我们点击左上角的修改,点击笔记本设置,选择硬件加速器为GPU。
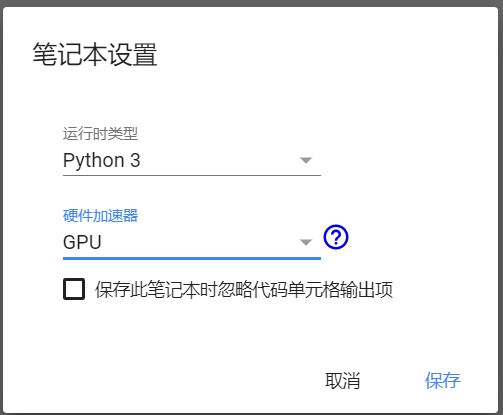
(2)当我们第一次进入到colab中的时候,它会为我们随机分配一个GPU,并且只有12小时的使用时间,也就是12小时后就会重新分配,如果我们不结合谷歌硬盘一起使用的话,那么可能我们的代码数据就很容易丢失。
首先在刚创建的笔记本的代码块中输入以下内容,用于挂载谷歌硬盘,并且指定云端硬盘为我们的根目录,这段代码可以就保存在我们的笔记本中,每次重新连接的时候的时候直接运行即可。
# 授权绑定Google Drive
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
# 指定Google Drive云端硬盘的根目录,名为drive
!mkdir -p drive
!google-drive-ocamlfuse drive
运行上面代码后,我们需要进行授权,会出现以下链接,点击并授权即可。下面就是授权成功。

然后我们可以用如下命令,进入我们开始新建的colab文件下面
# 指定当前的工作目录
import os
os.chdir("drive/colab")
接着我们可以新开一个代码块,可以通过命令!ls查看当前文件目录,判断是否成功挂载云端硬盘和是否进入到了我们的colab文件夹下面。

colab已经安装有了tensorflow等,我们还需要安装一下keras(需要的话)。
!pip install -q keras
2.在colab上面训练mnist数据集
这里就用手写数字体识别为例。
#基于keras的手写数字体识别
from keras.models import Sequential, load_model
import matplotlib.pyplot as plt
import numpy as np
import keras
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np
from keras.layers import Dense, Activation, Dropout, Flatten,Input,Conv2D,MaxPooling2D
from sklearn.model_selection import train_test_split
import cv2
from keras.models import Model
def convert_to_one_hot(Y, C):
Y = np.eye(C)[Y.reshape(-1)]
return Y
def my_model(input_shape=(28,28,1),num_classes = 10):
X_input = Input(input_shape)
X = Conv2D(filters=6, kernel_size=(5,5), strides=(1,1), padding="valid")(X_input)
X = Activation("relu")(X)
X = MaxPooling2D(pool_size=(2,2), strides=(2,2), padding="same")(X)
X = Conv2D(filters=16, kernel_size=(5,5), strides=(1,1), padding="valid")(X)
X = Activation("relu")(X)
X = MaxPooling2D(pool_size=(2,2), strides=(2,2), padding="same")(X)
X = Flatten()(X)
X = Dense(120, activation="relu")(X)
X = Dense(84, activation="relu")(X)
X = Dense(num_classes, activation="softmax")(X)
model = Model(inputs=X_input, outputs=X)
return model
#加载数据集
from keras.datasets import mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
train_x = train_x.reshape(train_x.shape[0],train_x.shape[1],train_x.shape[2], 1)
test_x = test_x.reshape(test_x.shape[0], test_x.shape[1], test_x.shape[2], 1)
train_y = train_y.reshape(len(train_y),1).astype(int)
test_y = test_y.reshape(len(test_y),1).astype(int)
train_y = convert_to_one_hot(train_y,10)
test_y = convert_to_one_hot(test_y, 10)
print("训练集x:", train_x.shape)
print("训练集y:", train_y.shape)
print("测试机x:", test_x.shape)
print("测试机y:", test_y.shape)
#训练模型
model = my_model(num_classes=10)
model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['accuracy'])
model.fit(train_x, train_y, epochs=20, batch_size=64)
score = model.evaluate(test_x, test_y, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
输出结果:
训练集x: (60000, 28, 28, 1)
训练集y: (60000, 10)
测试机x: (10000, 28, 28, 1)
测试机y: (10000, 10)
Epoch 1/20
60000/60000 [==============================] - 6s 96us/step - loss: 1.0586 - acc: 0.8733
Epoch 2/20
60000/60000 [==============================] - 5s 89us/step - loss: 0.1065 - acc: 0.9684
Epoch 3/20
60000/60000 [==============================] - 5s 91us/step - loss: 0.0706 - acc: 0.9786
Epoch 4/20
60000/60000 [==============================] - 5s 90us/step - loss: 0.0605 - acc: 0.9817
Epoch 5/20
60000/60000 [==============================] - 6s 92us/step - loss: 0.0521 - acc: 0.9838
Epoch 6/20
60000/60000 [==============================] - 5s 89us/step - loss: 0.0458 - acc: 0.9856
Epoch 7/20
60000/60000 [==============================] - 5s 89us/step - loss: 0.0399 - acc: 0.9874
Epoch 8/20
60000/60000 [==============================] - 5s 90us/step - loss: 0.0366 - acc: 0.9887
Epoch 9/20
60000/60000 [==============================] - 5s 89us/step - loss: 0.0320 - acc: 0.9896
Epoch 10/20
60000/60000 [==============================] - 5s 88us/step - loss: 0.0291 - acc: 0.9907
Epoch 11/20
60000/60000 [==============================] - 5s 91us/step - loss: 0.0292 - acc: 0.9916
Epoch 12/20
60000/60000 [==============================] - 5s 89us/step - loss: 0.0259 - acc: 0.9922
Epoch 13/20
60000/60000 [==============================] - 5s 89us/step - loss: 0.0244 - acc: 0.9924
Epoch 14/20
60000/60000 [==============================] - 5s 90us/step - loss: 0.0264 - acc: 0.9923
Epoch 15/20
60000/60000 [==============================] - 5s 90us/step - loss: 0.0225 - acc: 0.9933
Epoch 16/20
60000/60000 [==============================] - 5s 89us/step - loss: 0.0175 - acc: 0.9947
Epoch 17/20
60000/60000 [==============================] - 5s 89us/step - loss: 0.0213 - acc: 0.9940
Epoch 18/20
60000/60000 [==============================] - 5s 89us/step - loss: 0.0204 - acc: 0.9939
Epoch 19/20
60000/60000 [==============================] - 5s 88us/step - loss: 0.0189 - acc: 0.9949
Epoch 20/20
60000/60000 [==============================] - 5s 90us/step - loss: 0.0184 - acc: 0.9947
Test loss: 0.07412357944927885
Test accuracy: 0.9844
需要注意的是:在colab上面如果我们想用自己的数据集,就需要先把数据上传到谷歌硬盘上面。不过colab上读取谷歌硬盘上面的图片貌似很慢,但是如果直接用keras提供的训练集下载又是很快的,相比于本机上面。不过总体上用GPU加速的训练速度还是要比本机上要快好几倍。