pytorch版本下的yolov3训练实现火焰检测
时隔好多好多日子了,一直没写博客(小声bb,最近忙着接私活儿)。马上就要开学了,害,回去就要加油干了!!!

本次教程写个pytorch版本的yolov3检测,用的火焰检测数据集,效果如下:



这就可以做个火警预测了,yolov3是真的香呀,这次用到的是github 的一个pytorch实现版本,效果上还是不错的。

那么, 接下来,就跟我一起来实操起来吧!!!
一、环境要求
老规矩,工欲善其事必先利其器,搭建环境!!

- Python: 3.7.4
- Tensorflow-GPU 1.14.0
- Keras: 2.2.4
- numpy:1.17.4
这里建议用anaconda来快速搭建一个虚拟环境,速度很快的!!!
二、数据集准备
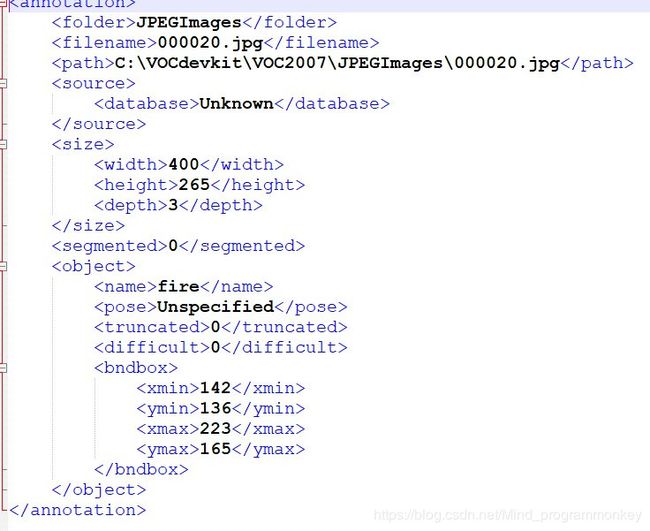
从互联网上收集火焰图片,并用labelimg进行标注,得到标注图片以及标注的位置信息。
如下:

万事俱备,开始coding!!!!

三、Pytorch版本的YoloV3
Pytorch_Yolov3
1.安装模块
在requirements.txt中含有本次所需的python模块.
- numpy
- torch==1.2.0
- torchvision==0.4.0
- matplotlib
- tensorflow==1.13.2
- tensorboardX==2.0
- terminaltables
- pillow
- tqdm
可用pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt来安装所需的模块。
2.下载所需的权重文件
Linux平台下,cd weights/,之后运行bash download_weights.sh文件,即可下载所需的权重信息。
Windows平台下,可直接编辑download_weigths.sh文件,复制其中的模型链接,在游览器中打开下载。

下载完毕后,在weights文件的内容如下:
3.修改配置文件
Linux平台下,运行cd config/目录,之后运行 bash create_custom_model.sh 其中 为类别参数,根据你的需要修改,这里我修改为1.
Windows平台下,配置git的bin目录下的变量之后,运行sh.exe文件。之后cd config目录之后,运行sh create_custom_model.sh 即可

执行完毕之后,修改custom.data,修改其配置信息即可。

4.配置本次yolov3的数据格式
重点来了,重点来了,重点来了!!!

在该github下,对自定义的数据,并未阐述,只是一笔带过。但该yolov3的版本所需的数据格式跟voc格式和coco格式都不大一样。每张图片对应一个txt标注信息。其第一列为类别信息,之后的四列为标准化的标注信息。其中 label 是类别在 data/custom/classes.names 的索引, <> 代表缩放后的比例系数
- <1>*w = (xmax-xmin)/2 + xmin
- <2>*h = (ymax-ymin)/2 + ymin
- <3> = (xmax-xmin)/w
- <4> = (ymax-ymin)/h
这里github未提供数据转换,这里先新建两个Annotations和JPEGImages的文件夹,将准备好的图片和xml标记信息放于其中。
然后运行voc2yolov3文件,生成train.txt和valid.txt文件信息,将数据集划分,即将图片路径保存在两个txt文件中。
之后运行voc_annotation.py对xml标记信息进行处理,处理成下列的txt文件形式

并记得修改classes.names的类别名,以及将图片复制到images文件中。即
好了,数据格式制作完成了!!!
下面可以开始训练了.

5.运行train.py
# 训练命令
python train.py --model_def config/yolov3-custom.cfg --data_config config/custom.data --pretrained_weights weights/darknet53.conv.74
# 添加其他参数请见 train.py 文件
# 从中断的地方开始训练
python train.py --model_def config/yolov3-custom.cfg --data_config config/custom.data --pretrained_weights checkpoints/yolov3_ckpt_99.pth --epoch
若出现警告解决方案UserWarning: indexing with dtype torch.uint8 is now deprecated, please use a dtype torch.bool instead.
在 model.py计算损失的位置 大概在 192 行左右添加以下两句:
obj_mask=obj_mask.bool() # convert int8 to bool
noobj_mask=noobj_mask.bool() #convert int8 to bool

运行过程如图所示:
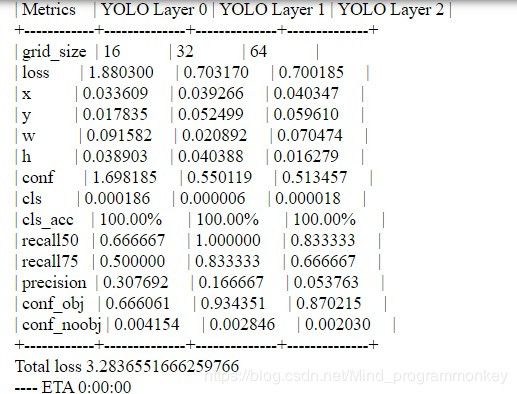

可通过tensorboard来查看运行过程中的变化。tensorboard --logdir='logs\'
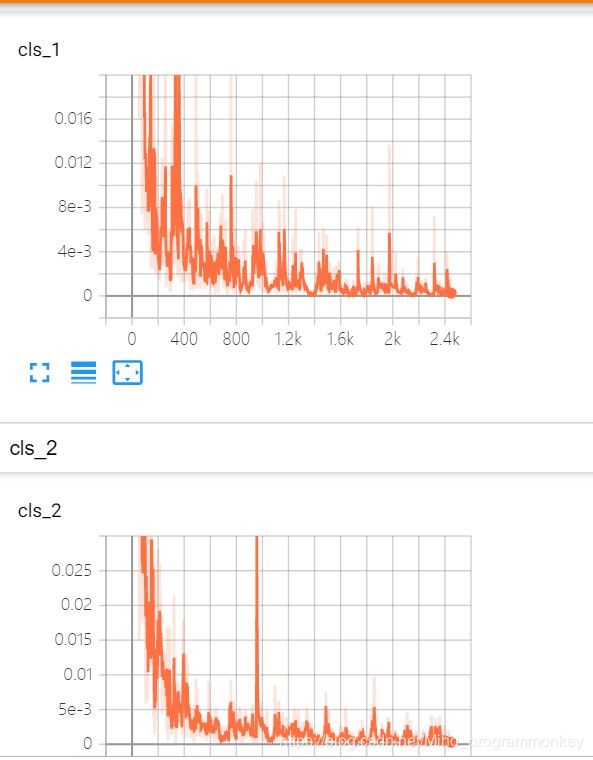
6.测试结果
叮咚,叮咚,马上大功告成了!!!
python detect.py --image_folder data/imgs/ --weights_path checkpoints/yolov3_ckpt_99.pth --model_def config/yolov3-custom.cfg --class_path data/custom/classes.names
运行上述,其会对data/imgs 文件下的图片进行预测,并将预测结果保存到output/imgs文件下
若是在 GPU 的电脑上训练,在 CPU 的电脑上预测,则需要修改 model.load_state_dict(torch.load(opt.weights_path, map_location='cpu'))


好了,大功告成了!!! 立下flag!!! 明天再更一个!!!
