小白自总结【情感分析】时、空、事件+情感
参考赞赞的一文:https://mp.weixin.qq.com/s?__biz=MzA3MDg0MjgxNQ==&mid=2652389938&idx=1&sn=26438273f915418735fccd6342b2f5cb&scene=4&key=ff97d989c700b3d8541e1e192aacbd6af8f1e8808c0330e21d83561bdc2a81f3379c4f98829b0bc2969b952f7230a5e41d9155c3081b5db03cd90cae33a73499f2f9dea22317a7c16aa16b1780e4b451&ascene=7&uin=NTc5Mzc1Njk1&devicetype=Windows+7&version=6203005d&pass_ticket=ky6wFvsdxcavpYU6VpXfgY%2B3VBtT1ewdeLr9ZPQdRxnFpXr7cQ6roESCXqkWBV6q&winzoom=1
心得体会
零碎记录
构建基础情感词典
关于综合两词典去重:直接将知网和NTSUSD的放excel的一列,去数据重复项不就OK(实际上重复项很少)
关于原词典去停用词:按原文“根据哈工大的停用词表”进行积极/消极词典去停用词——无变化呀!(而且,个人觉得这步不是必需的)
去停用词的代码有报错(还是编码问题T T):(1)“UnicodeDecodeError: 'utf8' codec can't decode”可能是当前文件所用的编码是默认的ANSI,而不是utf-8 (参考http://blog.csdn.net/u011528082/article/details/19123289)(2)"UnicodeEncodeError: 'gbk' codec can't encode character "在windows下面,新文件的默认编码是gbk,这样python解释器会用gbk编码去解析我们的网络数据流txt,然而txt此时已经是decode过的unicode编码,故改变目标文件的编码f = open("out.html","w",encoding='utf-8') (参考http://www.jb51.net/article/64816.htm)
自定义textprocess库(预先处理)
参考:http://blog.csdn.net/bcj296050240/article/details/46686797
词频统计“图悦”
分析出图后可导出表至本地
报错与修改
①Python3的“reload(sys)”无法直接用,而是:import importlib,sys importlib.reload(sys)
②jieba分词里“IndexError: list index out of range”,python 读取 多行txt 如果不加line.strip() 会报这个错——然后参照jieba文件夹以前的词典dict,将pos/neg词典的换行符都替换成空格了,get√
③“AttributeError: 'str' object has no attribute 'decode'”——编写的textprocess库的文件要以二进制形式打开
④报错 'bytes' object has no attribute 'readlines'——readlines()读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素
⑤jieba.load_userdict('dict.txt')时报错找不到dict.txt——直接改成绝对路径行啦!这还不简单~(文件夹上方双击即可复制路径!)
主要是混乱编码问题,大致思路总结:
以posdict = open("基础积极情感词典.txt","rb").read().decode('utf-8')形式读取各词典文件了,其他编码报错处简单修改了
前辈建议(上述处理存在不足)
实验流程
Python处理篇
情感分析,得分值
(情感分析前的预处理,根据实际修改词典,如“干涸”为消极词,“喷”为积极词等)

Kmeans聚类
(聚类前的预处理,去停用词、分词等)

excel处理篇
excel是神器啊,深刻地体会到了<( ̄︶ ̄)> 用excel挺多的,就不按流程顺序记了,简单总结一下:
(1)基本操作
①情感分值结果.txt→.xlsx:通过“分列”将分值与文本分开
②时间格式的统一:借助“分列”、“替换”(还包括粘到word里便于替换)等
(2)图表
①修改系列名称——右击图表,“选择数据”,编辑系列名称
②设置横轴内容——可通过右击图表,“选择数据”
③事件+情感 不同坐标轴——主/次坐标轴(单击系列-图上右击系列一内容-设置,再右击系列二内容-设置)
(3)函数
①excel去首空格——trim函数,如=TRIM(A1)
②合并不同列单元格内容——&,如=A1&B1
③时间+情感 一开始误以为是分条计数,只保留等差数列行

④地名归属到省份(数据准备:全国城市省市县区行政级别对照表——注意去“市”“区”“县”等字眼以实现VLOOKUP匹配原数据)
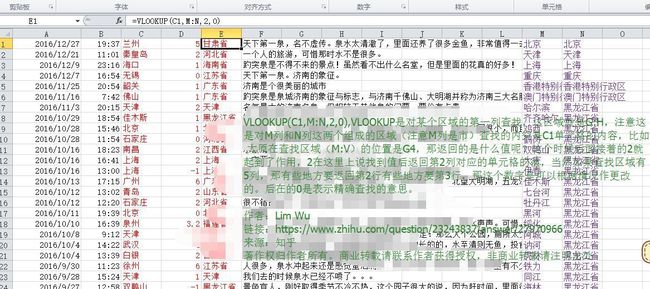
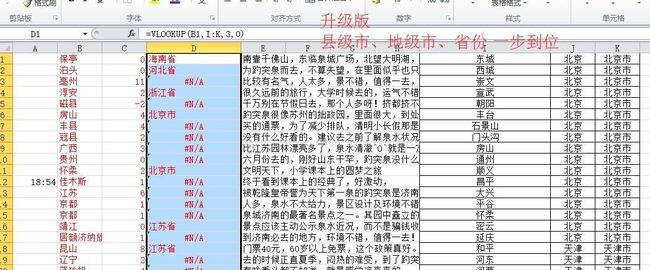
时空事+情感分别处理篇
1.时间+情感
涉及到每五天取一次平均值——这里我主要是借助excel的筛选等工具,进行人工取了(不是很麻烦)
再出图——如面积图

2.空间+情感
原以为是将excel经纬度坐标导入到arcgis(具体操作百度吧,注意:直接操作会提示“缺少Object-ID字段”——确定后打开生成的.shp点的属性表,将属性表导出.dbf,再开此.dbf表进行“显示X、Y坐标”操作——我好像是这么做的,反正最后显示出啦(≧▽≦))(注意:本来纳闷,为啥只显示了一个坐标点——中国的经纬度范围大约为:纬度3.86~53.55,经度73.66~135.05,原来弄错经纬度了!)
附一张根据微博数据经纬度做的情感图(属性-符号系统-设置字段“情感分”的显示方式√)(然而本意并非如此)
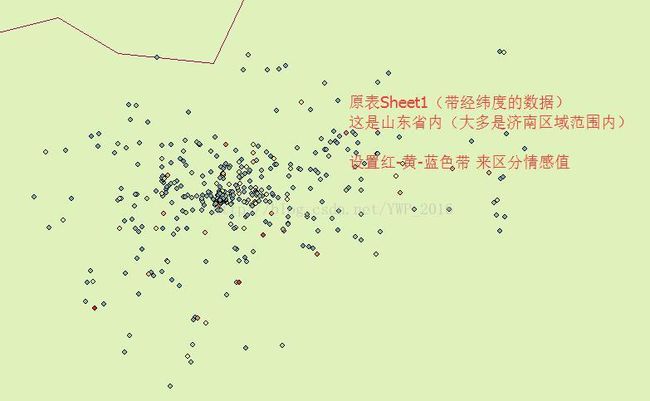
而师哥的意思是:不用管经纬度,而是按所属省份,最后看每个省份的情感状况√——“在arcgis里,用测量距离的工具,大概拉一下
,根据省份做情感值就可以 ”(本来还纳闷,因为给的数据中只有微博数据有经纬度,携程和百度的都木有)————再进行可视化 √
先将各地名分别归属到省份,以下是各省的情感分均值(去除了位置“未知”的评论数据)——“ 云南湖北样本少,偶然性大;还有可能是受来访时间的影响,西安游客,大部分都是九月份之后来的:

3.事件+情感
Kmeans聚类后的结果,加以总结类名等人工整理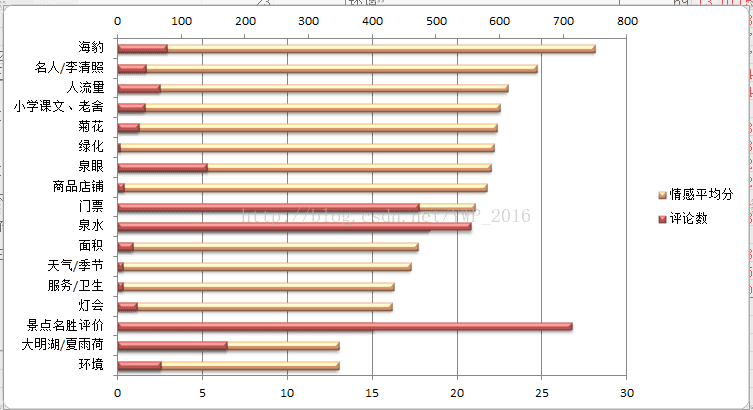
后续:词云图等
词频处理:如“李清照纪念馆”分词出“李清照”、“纪念馆”了——鉴于本实验中该类词很少,直接一替换OK了~(算算数啥的)
而[词 词频] 可以直接粘贴到词云工具生成词云图
9个优秀网上免费标签云生成工具:http://www.cnblogs.com/chu888chu888/archive/2012/01/02/2310248.html
注意:①其中Tagxedo做中文词云时,设置参数使其字、词不分离——http://www.360doc.com/content/14/0819/10/21412_403006725.shtml
②尝试多种词云生成工具,选用Tagul(https://wordart.com/create)——未将英文词组割分

