使用mmdetection运行自己的VOC格式数据(AI studio下的ubuntu系统)
使用mmdetection运行自己的VOC格式数据(AI studio下的ubuntu系统)
- 配置mmdetection环境
- 组织VOC数据集
- 更改配置文件,运行程序
参考:
mmdetection使用tensorboard可视化训练集与验证集指标参数
mmdetection
mmdetection使用指南
配置mmdetection环境
mmdetection的github主页.
官方支持Python3.5+,Pytorch1.1+,CUDA9.0+。
这里我配置环境采用mmdetection1.2,Python3.7,Pytorch1.2,CUDA9.2。
本文的环境配置采用conda。
#安装python3.7
conda create -n open-mmlab python=3.7
由于AI studio默认安装的CUDA9.2,因此我从 pytorch官网查找的基于CUDA9.2的安装指令。这里需要注意如果你更改的conda的源,例如清华源,请务必删掉指令后面的-c pytorch,这样才会从清华源进行下载。
#安装pytorch1.2
conda install pytorch==1.2.0 torchvision==0.4.0 cudatoolkit=9.2 -c pytorch
接下来从github上把mmdetection的代码拉下来。目前mmdetection最新的是V2版本,V2版本只支持torch1.3+,本文用的是V1版本。
#下载mmdetetion
git clone https://github.com/open-mmlab/mmdetection.git
如果从终端下载速度慢,可以将下载地址复制到迅雷上进行下载,然后上传到linux系统中。
然后安装mmdetection。这里要注意的是官方给出的pycocotools下载地址安装后会报错,这里用的是git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI这个地址。
#安装mmdetetion
pip install -r requirements/build.txt
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
python setup.py develop
在执行 python setup.py develop这一步时,有些包下载的很慢,可以先安装好pip install mmcv等,还可以在安装过程对于遇到一些速度慢的包,复制终端中显示的下载连接到迅雷下载器中,然后再使用pip install filename.whl安装下好的whl文件。
在之后的运行过程中还可能会有关于pillow的报错,如果报错是关于pillow7.0,这是重新安装低版本的pillow6.1即可。
#更改低版本pillow
pip install pillow==6.1
至此mmdetetion的运行环境配置完成
组织VOC数据集
请务必使用官方给出的标准文件结构。
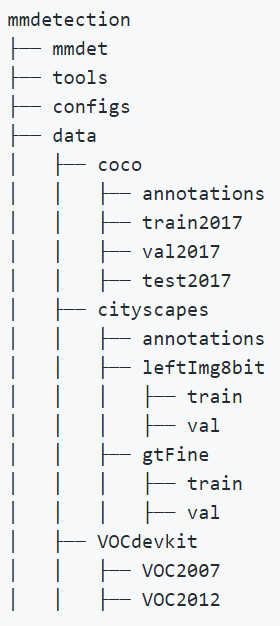
在mmdetection文件下创建data文件下,然后将标准的VOCdevkit文件夹放入其中。
如果只采用VOC数据集的话,只需在data文件下建立VOCdevkit文件夹及VOC2007文件夹即可。其中VOC2007中包含Annotations文件夹,ImageSets文件夹和JPEGImages文件夹。Annotations文件夹中放图片的XML文件,JPEGImages中放图片文件,具体内容可搜索如何制作VOC数据集。
更改配置文件,运行程序
1.修改mmdetection/mmdet/core/evaluation/class_names.py文件。修改voc_classes()中的类别名,如果只有一个类别,一定要在后面加上逗号“,”。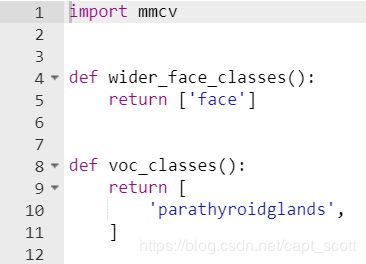
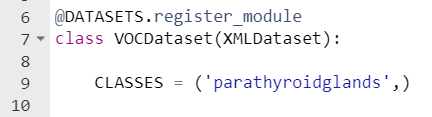
2.修改mmdetection/mmdet/datasets/voc.py文件。修改VOCDataset()类中的类别名,如果只有一个类别,一定要在后面加上逗号“,”。
3.修改mmdetection/configs下的配置文件,找到你所要用的模型的配置文件进行修改。
我这里以faster_rcnn_r101_fpn_1x.py为例。
更改num_classes数为类别数加1,不同的配置文件num_classes位置可能不一样,可以全局搜索进行更改。
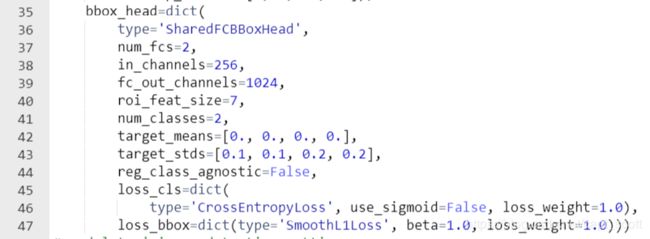
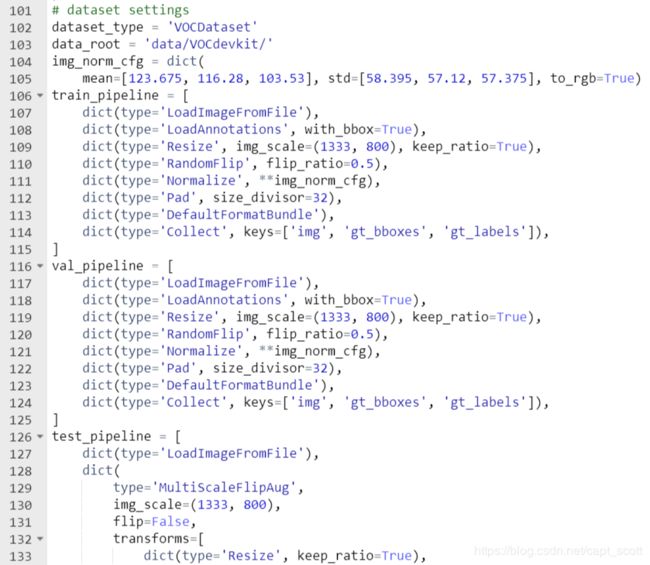
更改dataset settigns中的dataset_type和data_root如图所示。要注意的是,该配置文件原本是没有val_pipeline这一项的,如果想要在训练中加入val验证集,需要手动复制train_pipeline这一项并改成val_pipeline,最终结果如下图。同时,还需要在该配置文件的最后一行,将workflow = [('train', 1)]改为workflow = [('train', 1),('val', 1)]。
最后修改ann_file和img_prefix两项如下图所示。

值得注意的是,上图中的imgs_per_gpu的默认值为2,我的的设备运行程序出错,如下图所示
我用的时AI studio的云设备,只有一张V100显卡,因此我将这里改为1后便解决了这个错误。
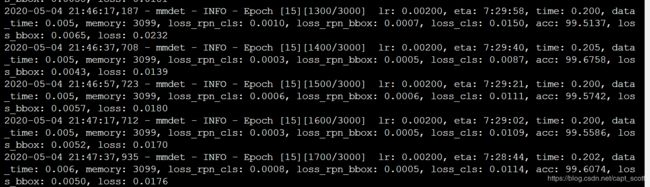
最终,运行python train.py path/to/faster_rcnn_r101_fpn_1x.py,成功开始炼丹。