【华为云技术分享】物体检测yolo3算法 学习笔记2
先来看一下yolo3的结构图:
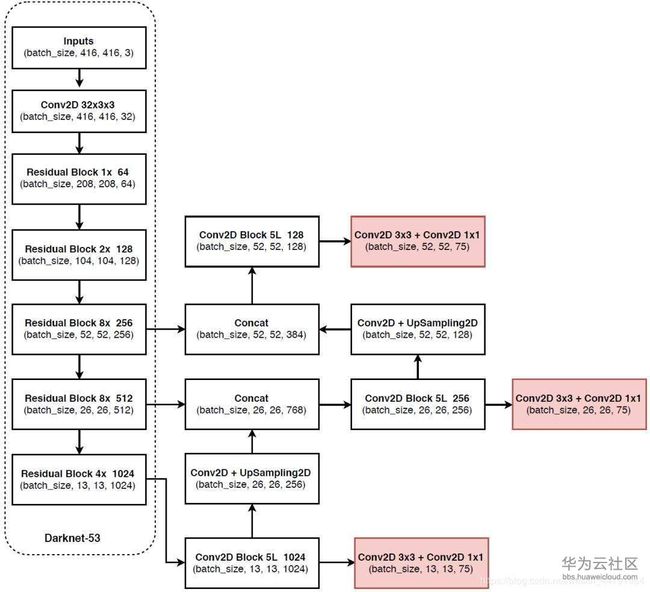
1、主体网络darknet53
最左边的这一部分叫做Darknet-53,
(1)它最重要特点是使用了残差网络Residual,darknet53中的残差卷积就是进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果, 残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
(2)darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行l2正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU。普通的ReLU是将所有的负值都设为零,Leaky ReLU则是给所有负值赋予一个非零斜率。以数学的方式我们可以表示为:
2、从特征获取预测结果
(1)在特征利用部分,yolo3提取多特征层进行目标检测,一共提取三个特征层,三个特征层位于主干部分darknet53的不同位置,分别位于中间层,中下层,底层,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024)。
(2)三个特征层进行5次卷积处理,处理完后一部分用于输出该特征层对应的预测结果,一部分用于进行反卷积UmSampling2d后与其它特征层进行结合。
(3)图中输出层的shape分别为(13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为该图是基于voc数据集的,它的类为20种,
我们代码中实际使用的是coco训练集,类则为80种,yolo3针对每一个特征层存在3个先验框,所以最后的维度为255 = 3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)
其实际情况就是,输入N张416x416的图片,在经过多层的运算后,会输出三个shape分别为(N,13,13,255),(N,26,26,255),(N,52,52,255)的数据,对应每个图分为13x13、26x26、52x52的网格上3个先验框的位置。
3、预测结果的解码
yolo3的3个特征层分别将整幅图分为13x13、26x26、52x52的网格,每个网络点负责一个区域的检测。
我们知道特征层的预测结果对应着三个预测框的位置,我们先将其reshape一下,其结果为(N,13,13,3,85),(N,26,26,3,85),(N,52,52,3,85)。
最后一个维度中的85包含了4+1+80,分别代表x_offset、y_offset、h和w、置信度、分类结果。
yolo3的解码过程就是将每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了,当然得到最终的预测结构后还要进行得分排序与非极大抑制筛选。
下面我们继续对ModelArts实战营 mission 4 物体检测 1的代码进行解析,在上一篇中,我们在初始化session部分介绍了如何创建模型,下面我们重点分析一下它的逻辑
重要的参数有:
-
input_shape:输入图片的尺寸,默认是(416,416):
-
anchors:默认的9种anchor box,shape是(9,2);
-
num_classes:类别数,类别按0~n排列,输入类别也是索引;
-
weights_path:预训练的权重路径;
代码逻辑如下:
首先将参数进行处理:
h, w = input_shape # 拆分图片尺寸的宽h和高w;
image_input = Input(shape=(None, None, 3)) # 创建图片的输入格式image_input,隐式如(None,None,3),显示如(416,416,3);
num_anchors = len(anchors) # 计算anchor的数量#根据anchor的数量,创建真值y_true的输入格式,真值y_true即Groud Truth:
y_true = [Input(shape=(h // {0: 32, 1: 16, 2: 8}[l], w // {0: 32, 1: 16, 2: 8}[l], num_anchors // 3, num_classes + 5)) for l in range(3)]
# 输入格式如下:YOLO的三种尺度(13*13,26*26,52*52),每个尺度的anchor数(=9/3),类别数(80)+边框4个+置信度1
“//”是Python语法中的整除符号,通过循环创建3个Input层,组成列表,作为y_true,格式如下:

其中,第一位是样本数,第2-3位是特征图的尺寸,共有3种尺度(13x13,26x26,52x52),第4位是每个图的anchor数(3),第5为是:类别数(80)+4个边框值(x,y,w,h)+框的置信度(是否含有物体)
通过图片输入Input层image_input、每个尺度的anchor数num_anchors//3、类别数num_classes,创建YOLO v3的网络结构,即:
model_body = yolo_body(image_input, num_anchors // 3, num_classes)
接着,加载预训练模型,如果希望不加载预训练权重,从头开始训练的话,可以将这条语句删掉:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
根据预训练模型的地址weights_path,加载模型,按名称对应by_name,略过不匹配skip_mismatch;
定义yolo 损失函数:
-
Lambda是Keras的自定义层,输入为(*model_body.output , *y_true),输出为output_shape=(1,);
-
层的名字name为yolo_loss;
-
参数为anchors锚框、类别数num_classes,ignore_thresh是物体置信度损失(object confidence loss)的IoU(Intersection over Union,重叠度)阈值;
-
yolo_loss是核心的损失函数。
最后构建模型,为训练做准备
model = Model([model_body.input],*y_true], model_loss)
其中,model_body.input是任意(?)个(416,416,3)的图片,即:
Tensor("input_1:0", shape=(?, 416, 416, 3), dtype=float32)
y_true是已标注数据转换的真值结构。
作者:hellfire