房价租金预测竞赛总结1:数据探索性分析
房价租金预测竞赛总结1:数据探索性分析
- 任务要求
- 数据概况
- 数据集字段说明
- 评分指标
- 数据分析
- 总体情况
- 类别特征和数值特征
- 缺失值分析
- 单调特征列分析
- 特征unique分析
- 统计特征值频次大于100的特征
- label分布
- 编码问题
任务要求
比赛要求参赛选手根据给定的数据集,建立模型,预测房屋租金。
赛题连接:房价租金预测
数据概况
数据集中的数据类别包括租赁房源、小区、二手房、配套、新房、土地、人口、客户、真实租金等。
数据集字段说明
对于小区信息中,关于city、region、plate三者的关系:city>region>plate。
土地数据中,土地楼板面积是指在土地上建筑的房屋总面积。
评分指标
回归结果评价标准采用R-Square。
score = 1 − ∑ i = 1 m ( y ^ i − y i ) 2 ∑ i = 1 m ( y i − y ˉ ) 2 \text { score }=1-\frac{\sum_{i=1}^{m}\left(\widehat{y}_{i}-y_{i}\right)^{2}}{\sum_{i=1}^{m}\left(y_{i}-\bar{y}\right)^{2}} score =1−∑i=1m(yi−yˉ)2∑i=1m(y i−yi)2
其中, y i y_{i} yi表示真实值, y ^ i \widehat{y}_{i} y i表示预测值, y ˉ \bar{y} yˉ表示样本均值。得分越高拟合效果越好。
R 2 R^{2} R2用于度量因变量的变异中可由自变量解释部分所占的比例,取值范围是 0~1, R 2 R^{2} R2越接近1,表明回归平方和占总平方和的比例越大,回归线与各观测点越接近,用x的变化来解释y值变化的部分就越多,回归的拟合程度就越好。所以 R 2 R^{2} R2也称为拟合优度(Goodness of Fit)的统计量。
数据分析
导入数据分析所用的包
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
总体情况
导入数据
# 载入数据
data_train = pd.read_csv('../data/train_data.csv')
data_train['Type'] = 'Train'
data_test = pd.read_csv('../data/test_a.csv')
data_test['Type'] = 'Test'
data_all = pd.concat([data_train, data_test], ignore_index=True)
# 总体情况一览
print(data_train.info())
print(data_train.describe())
print(data_train.head())
结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 41440 entries, 0 to 41439
Data columns (total 52 columns):
ID 41440 non-null int64
area 41440 non-null float64
rentType 41440 non-null object
houseType 41440 non-null object
houseFloor 41440 non-null object
totalFloor 41440 non-null int64
houseToward 41440 non-null object
houseDecoration 41440 non-null object
communityName 41440 non-null object
city 41440 non-null object
region 41440 non-null object
plate 41440 non-null object
buildYear 41440 non-null object
saleSecHouseNum 41440 non-null int64
subwayStationNum 41440 non-null int64
busStationNum 41440 non-null int64
interSchoolNum 41440 non-null int64
schoolNum 41440 non-null int64
privateSchoolNum 41440 non-null int64
hospitalNum 41440 non-null int64
drugStoreNum 41440 non-null int64
gymNum 41440 non-null int64
bankNum 41440 non-null int64
shopNum 41440 non-null int64
parkNum 41440 non-null int64
mallNum 41440 non-null int64
superMarketNum 41440 non-null int64
totalTradeMoney 41440 non-null int64
totalTradeArea 41440 non-null float64
tradeMeanPrice 41440 non-null float64
tradeSecNum 41440 non-null int64
totalNewTradeMoney 41440 non-null int64
totalNewTradeArea 41440 non-null int64
tradeNewMeanPrice 41440 non-null float64
tradeNewNum 41440 non-null int64
remainNewNum 41440 non-null int64
supplyNewNum 41440 non-null int64
supplyLandNum 41440 non-null int64
supplyLandArea 41440 non-null float64
tradeLandNum 41440 non-null int64
tradeLandArea 41440 non-null float64
landTotalPrice 41440 non-null int64
landMeanPrice 41440 non-null float64
totalWorkers 41440 non-null int64
newWorkers 41440 non-null int64
residentPopulation 41440 non-null int64
pv 41422 non-null float64
uv 41422 non-null float64
lookNum 41440 non-null int64
tradeTime 41440 non-null object
tradeMoney 41440 non-null float64
Type 41440 non-null object
dtypes: float64(10), int64(30), object(12)
memory usage: 16.4+ MB
None
ID area ... lookNum tradeMoney
count 4.144000e+04 41440.000000 ... 41440.000000 4.144000e+04
mean 1.001221e+08 70.959409 ... 0.396260 8.837074e+03
std 9.376566e+04 88.119569 ... 1.653932 5.514287e+05
min 1.000000e+08 1.000000 ... 0.000000 0.000000e+00
25% 1.000470e+08 42.607500 ... 0.000000 2.800000e+03
50% 1.000960e+08 65.000000 ... 0.000000 4.000000e+03
75% 1.001902e+08 90.000000 ... 0.000000 5.500000e+03
max 1.003218e+08 15055.000000 ... 37.000000 1.000000e+08
[8 rows x 40 columns]
ID area rentType houseType ... lookNum tradeTime tradeMoney Type
0 100309852 68.06 未知方式 2室1厅1卫 ... 0 2018/11/28 2000.0 Train
1 100307942 125.55 未知方式 3室2厅2卫 ... 1 2018/12/16 2000.0 Train
2 100307764 132.00 未知方式 3室2厅2卫 ... 1 2018/12/22 16000.0 Train
3 100306518 57.00 未知方式 1室1厅1卫 ... 9 2018/12/21 1600.0 Train
4 100305262 129.00 未知方式 3室2厅3卫 ... 0 2018/11/18 2900.0 Train
[5 rows x 52 columns]
该数据集一共包括41400个样本,共有51个特征,其中50个特征是自变量变量,因变量是tradeMoeny。该问题属于典型的回归问题。
目标变量(因变量)是float型数据,自变量大多数数据都是int或float型;有部分字段是object型,即文本型中文或英文的,如rentType字段。
类别特征和数值特征
通过数据信息能够看出类别型特征一共有11个
categorical_feas = ['rentType','houseType','houseFloor','region','plate',
'houseToward','houseDecoration','communityName','city',
'buildYear','tradeTime']
连续型特征(包括因变量)一共有40个
numerical_feas=['ID','area','totalFloor','saleSecHouseNum','subwayStationNum',
'busStationNum','interSchoolNum','schoolNum','privateSchoolNum','hospitalNum',
'drugStoreNum','gymNum','bankNum','shopNum','parkNum','mallNum','superMarketNum',
'totalTradeMoney','totalTradeArea','tradeMeanPrice','tradeSecNum','totalNewTradeMoney',
'totalNewTradeArea','tradeNewMeanPrice','tradeNewNum','remainNewNum','supplyNewNum',
'supplyLandNum','supplyLandArea','tradeLandNum','tradeLandArea','landTotalPrice',
'landMeanPrice','totalWorkers','newWorkers','residentPopulation','pv','uv',
'tradeMoney','lookNum']
缺失值分析
# 缺失值分析
def missing_values(df):
alldata_na = pd.DataFrame(df.isnull().sum(),columns={'missingNum'})
alldata_na['existNum'] = len(df) - alldata_na['missingNum']
alldata_na['sum'] = len(df)
alldata_na['missingRatio'] = alldata_na['missingNum']/len(df)
alldata_na['dtype'] = df.dtypes
# ascending:默认True升序排列,False降序排列
alldata_na = alldata_na[alldata_na['missingNum']>0].reset_index().sort_values(by=['missingNum','index'],ascending=[False,True])
alldata_na.set_index('index',inplace=True)
return alldata_na
alldata_na = missing_values(data_train)
结果
missingNum existNum sum missingRatio dtype
index
pv 18 41422 41440 0.000434 float64
uv 18 41422 41440 0.000434 float64
通过编写函数确定训练集中的那些特征存在缺失值,分别缺失了多少数据,缺失的比例有多大,以及这些缺失数据是否是随机缺失还是存在某种联系。
简要分析,在该训练集中,只有两个特征存在缺失值分别是’pv’和’uv’,并且分别缺失了18个数据,分别占总数据的0.043%,通过查看原始数据得知缺失的数据来自同一个小区。该后续的分析中可以考虑先剔除这两个特征或者剔除这18个样本,先进行分析。
单调特征列分析
# 单调特征列分析
def increasing(vals):
cnt = 0
len_ = len(vals)
for i in range(len_-1):
if vals[i+1] > vals[i]:
cnt += 1
return cnt
fea_cols = [col for col in data_train.columns]
for col in fea_cols:
cnt = increasing(data_train[col].values)
if cnt / data_train.shape[0] >= 0.55:
print('单调特征:', col)
print('单调特征值个数:', cnt)
print('单调特征值比例:', cnt/data_train.shape[0])
结果
单调特征: tradeTime
单调特征值个数: 24085
单调特征值比例: 0.5812017374517374
通过编写函数确定存在单调递增的特征,即是否存在一列数据单调递增。
单调特征为什么采用这种判断方法,如果入局之间被随机打乱,那这种方式不就失败了吗?
结果显示,存在一个单调递增的特征:tradeTime,为时间列。
时间列在特征工程的时候,不同的情况下能有很多的变种形式,比如按年月日分箱,或者按不同的维度在时间上聚合分组,等等
特征unique分析
# 特征unique分布
print('特征unique分布')
for feature in categorical_feas:
print(feature + "的特征分布如下:")
print(data_train[feature].value_counts())
结果
rentType的特征分布如下:
未知方式 30759
整租 5472
合租 5204
-- 5
Name: rentType, dtype: int64
houseType的特征分布如下:
1室1厅1卫 9805
2室1厅1卫 8512
2室2厅1卫 6783
3室1厅1卫 3992
3室2厅2卫 2737
4室1厅1卫 1957
9室2厅5卫 1
3室2厅5卫 1
5室4厅5卫 1
7室1厅3卫 1
Name: houseType, Length: 104, dtype: int64
houseFloor的特征分布如下:
中 15458
高 14066
低 11916
Name: houseFloor, dtype: int64
region的特征分布如下:
RG00002 11437
RG00005 5739
RG00003 4186
RG00010 3640
RG00012 3368
RG00004 3333
RG00006 1961
RG00007 1610
RG00008 1250
RG00013 1215
RG00001 1157
RG00014 1069
RG00011 793
RG00009 681
RG00015 1
Name: region, dtype: int64
plate的特征分布如下:
BK00031 1958
BK00033 1837
BK00045 1816
BK00055 1566
BK00056 1516
BK00044 98
BK00016 40
BK00036 33
BK00058 15
BK00032 3
BK00001 1
Name: plate, Length: 66, dtype: int64
houseToward的特征分布如下:
南 34377
南北 2254
北 2043
暂无数据 963
东南 655
东 552
西 264
西南 250
西北 58
东西 24
Name: houseToward, dtype: int64
houseDecoration的特征分布如下:
其他 29040
精装 10918
简装 1171
毛坯 311
Name: houseDecoration, dtype: int64
communityName的特征分布如下:
XQ01834 358
XQ01274 192
XQ02273 188
XQ03110 185
XQ02337 173
XQ01389 166
XQ03838 1
XQ04064 1
XQ00112 1
XQ01385 1
XQ03573 1
XQ01911 1
Name: communityName, Length: 4236, dtype: int64
city的特征分布如下:
SH 41440
Name: city, dtype: int64
buildYear的特征分布如下:
1994 2851
暂无信息 2808
2006 2007
2007 1851
2008 1849
2005 1814
2010 1774
1961 2
1926 2
1951 1
1962 1
1950 1
Name: buildYear, Length: 80, dtype: int64
tradeTime的特征分布如下:
2018/3/3 543
2018/3/4 487
2018/3/11 410
2018/3/10 400
2018/3/24 341
2018/3/18 339
2018/1/4 14
2018/1/18 14
2018/1/2 5
2018/2/13 4
2018/2/20 2
2018/2/19 1
2018/2/17 1
Name: tradeTime, Length: 361, dtype: int64
用自带函数value_counts() 来得到每个类别型变量的 种类 分布;并且简单画出柱状图直观地显示各变量的种类分布。
通过统计数字和柱状图,可以发现:
rentType:4种,且绝大多数是无用的未知方式;
houseType:104种,绝大多数在3室及以下;
houseFloor:3种,分布较为均匀;
region: 15种;
plate: 66种;
houseToward: 10种;
houseDecoration: 4种,一大半是其他;
buildYear: 80种;
communityName: 4236种,且分布较为稀疏;
此步骤是为之后数据处理和特征工程做准备,先理解每个字段的含义以及分布,之后需要根据实际含义对分类变量做不同的处理。
统计特征值频次大于100的特征
# 统计特征值频次大于100的特征
print('统计特征值频次大于100的特征')
for feature in categorical_feas:
df_value_counts = pd.DataFrame(data_train[feature].value_counts())
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = [feature,'counts'] # 改变列名
print(df_value_counts[df_value_counts['counts']>=100])
结果
rentType counts
0 未知方式 30759
1 整租 5472
2 合租 5204
houseType counts
0 1室1厅1卫 9805
1 2室1厅1卫 8512
2 2室2厅1卫 6783
3 3室1厅1卫 3992
4 3室2厅2卫 2737
5 4室1厅1卫 1957
6 3室2厅1卫 1920
7 1室0厅1卫 1286
8 1室2厅1卫 933
9 2室2厅2卫 881
10 4室2厅2卫 435
11 2室0厅1卫 419
12 4室2厅3卫 273
13 5室1厅1卫 197
14 2室1厅2卫 155
15 3室2厅3卫 149
16 3室1厅2卫 135
houseFloor counts
0 中 15458
1 高 14066
2 低 11916
region counts
0 RG00002 11437
1 RG00005 5739
2 RG00003 4186
3 RG00010 3640
4 RG00012 3368
5 RG00004 3333
6 RG00006 1961
7 RG00007 1610
8 RG00008 1250
9 RG00013 1215
10 RG00001 1157
11 RG00014 1069
12 RG00011 793
13 RG00009 681
plate counts
0 BK00031 1958
1 BK00033 1837
2 BK00045 1816
3 BK00055 1566
4 BK00056 1516
5 BK00052 1375
6 BK00017 1305
7 BK00041 1266
8 BK00054 1256
9 BK00051 1253
10 BK00046 1227
11 BK00035 1156
12 BK00042 1137
13 BK00009 1016
14 BK00050 979
15 BK00043 930
16 BK00026 906
17 BK00047 880
18 BK00034 849
19 BK00013 834
20 BK00053 819
21 BK00028 745
22 BK00040 679
23 BK00060 671
24 BK00010 651
25 BK00029 646
26 BK00062 618
27 BK00022 614
28 BK00018 613
29 BK00064 590
30 BK00005 549
31 BK00003 523
32 BK00014 500
33 BK00019 498
34 BK00061 477
35 BK00011 455
36 BK00037 444
37 BK00012 412
38 BK00038 398
39 BK00024 397
40 BK00020 384
41 BK00002 357
42 BK00065 348
43 BK00027 344
44 BK00039 343
45 BK00063 281
46 BK00057 278
47 BK00015 253
48 BK00006 231
49 BK00021 226
50 BK00007 225
51 BK00066 219
52 BK00030 219
53 BK00049 211
54 BK00008 210
55 BK00004 189
56 BK00048 165
57 BK00025 157
58 BK00023 127
59 BK00059 122
houseToward counts
0 南 34377
1 南北 2254
2 北 2043
3 暂无数据 963
4 东南 655
5 东 552
6 西 264
7 西南 250
houseDecoration counts
0 其他 29040
1 精装 10918
2 简装 1171
3 毛坯 311
communityName counts
0 XQ01834 358
1 XQ01274 192
2 XQ02273 188
3 XQ03110 185
4 XQ02337 173
5 XQ01389 166
6 XQ01658 163
7 XQ02789 152
8 XQ01561 151
9 XQ00530 151
10 XQ01339 132
11 XQ00826 122
12 XQ01873 122
13 XQ02296 121
14 XQ01232 119
15 XQ01401 118
16 XQ02441 117
17 XQ00196 115
18 XQ01207 109
19 XQ02365 109
20 XQ01410 108
21 XQ00852 105
22 XQ01672 103
23 XQ02072 103
city counts
0 SH 41440
buildYear counts
0 1994 2851
1 暂无信息 2808
2 2006 2007
3 2007 1851
4 2008 1849
5 2005 1814
6 2010 1774
7 1995 1685
8 1993 1543
9 2011 1498
10 2004 1431
11 2009 1271
12 2014 1238
13 2003 1156
14 1997 1125
15 2002 1120
16 2012 1049
17 1996 991
18 2000 925
19 2001 898
20 2015 840
21 1999 822
22 1998 733
23 2013 714
24 1987 632
25 1983 612
26 1991 545
27 1984 493
28 1980 452
29 1990 431
30 1988 423
31 1989 419
32 1985 359
33 1982 344
34 1986 320
35 1992 308
36 1976 251
37 1957 227
38 1981 221
39 1956 153
40 1977 153
41 2016 140
42 1978 133
43 1958 122
44 1979 116
45 1954 101
tradeTime counts
0 2018/3/3 543
1 2018/3/4 487
2 2018/3/11 410
3 2018/3/10 400
4 2018/3/24 341
5 2018/3/18 339
6 2018/3/1 332
7 2018/3/17 328
8 2018/3/5 296
9 2018/2/25 292
10 2018/3/8 291
11 2018/3/25 283
12 2018/3/2 276
13 2018/3/9 272
14 2018/3/12 260
15 2018/3/31 258
16 2018/3/7 252
17 2018/6/10 250
18 2018/8/19 234
19 2018/3/6 229
20 2018/7/29 225
21 2018/2/28 223
22 2018/7/1 221
23 2018/8/26 220
24 2018/3/15 218
25 2018/5/20 218
26 2018/5/27 217
27 2018/7/14 210
28 2018/4/22 210
29 2018/6/23 209
.. ... ...
154 2018/6/1 106
155 2018/11/24 106
156 2018/8/16 106
157 2018/6/29 106
158 2018/12/1 105
159 2018/8/29 105
160 2018/8/2 105
161 2018/6/7 105
162 2018/4/24 104
163 2018/6/13 104
164 2018/5/18 104
165 2018/11/11 104
166 2018/6/15 104
167 2018/4/12 103
168 2018/4/23 103
169 2018/9/24 103
170 2018/5/4 102
171 2018/5/2 102
172 2018/5/7 102
173 2018/4/11 102
174 2018/4/20 102
175 2018/7/10 102
176 2018/9/13 101
177 2018/4/28 101
178 2018/8/27 101
179 2018/7/4 100
180 2018/5/25 100
181 2018/11/25 100
182 2018/9/6 100
183 2018/9/3 100
[184 rows x 2 columns]
此步骤和特征nunique分布结合步骤结合起来看,有一些小于100的是可以直接统一归类为其他的
label分布
# label分布
print('label分布')
fig,axes = plt.subplots(2,3,figsize=(20,5))
fig.set_size_inches(20,12)
sns.distplot(data_train['tradeMoney'],ax=axes[0][0])
sns.distplot(data_train[(data_train['tradeMoney']<20000)]['tradeMoney'],ax=axes[0][1])
sns.distplot(data_train[(data_train['tradeMoney']>=20000) &
(data_train['tradeMoney']<50000)]['tradeMoney'],ax=axes[0][2])
sns.distplot(data_train[(data_train['tradeMoney']>=50000) &
(data_train['tradeMoney']<100000)]['tradeMoney'],ax=axes[1][0])
sns.distplot(data_train[(data_train['tradeMoney']>=100000)]['tradeMoney'],ax=axes[1][1])
print("money<=10000",len(data_train[(data_train['tradeMoney']<=10000)]['tradeMoney']))
print("10000,len(data_train[(data_train['tradeMoney']>10000)&(data_train['tradeMoney']<=20000)]['tradeMoney']))
print("20000,len(data_train[(data_train['tradeMoney']>20000)&(data_train['tradeMoney']<=50000)]['tradeMoney']))
print("50000,len(data_train[(data_train['tradeMoney']>50000)&(data_train['tradeMoney']<=100000)]['tradeMoney']))
print("100000,len(data_train[(data_train['tradeMoney']>100000)]['tradeMoney']))
结果
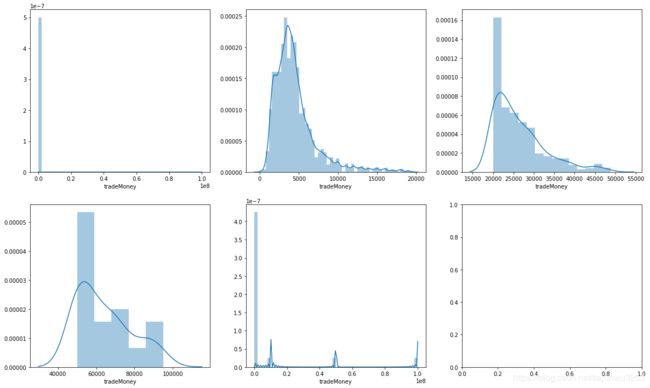
money<=10000 38964
10000<money<=20000 1985
20000<money<=50000 433
50000<money<=100000 39
100000<money 19
将目标变量tradeMoney分组,并查看每组间的分布;
可以看出绝大多数都是集中在10000元以内的,并且从图中可以看到该分布是右偏的。
编码问题
对11种类别型变量分别考虑进行编码,
rentType:对出租方式来讲,除了“未知方式”、“整租”、“合租”,还有一种"–",只有5个,样本量较少,而且在测试集数据中也没有该种类型的出租方式,因此可以将其作为异常值处理。
‘houseType’:房屋类型,用于说明几室几厅几卫,具有大小关系,因此采用分别给室厅卫赋予权重,进行加权。
‘houseFloor’: 房屋楼层只有高中低三种,而且具有大小关系,可以设为3,2,1。
‘houseToward’:房屋朝向有10种类型,其中有一种是“未知类型”,类型之间没有大小关系,因此可以采用onehat编码。
‘houseDecoration’:房屋装修有四种类型:“其它”、“精装”、“简装”、“毛坯”,之间有等级关系,但存在其它,可以默认为“其它”应该介于“毛坯”和“简装”之间,因此四者关系设为2,4,3,1。
‘communityName’, 小区名称,一共4236个,认为小区名称与ID类似,因此这个特征不参与训练。
‘city’:与ID类似。
‘region’:与ID 类似。
‘plate’:与ID类似。
‘buildYear’:建筑年份,转换为数值型,需要归一化处理。
’tradeTime’:交易时间,建议转换为年月日。