博客作者:凌逆战
论文地址:https://ieeexplore.ieee.org/document/8682215
博客地址:https://www.cnblogs.com/LXP-Never/p/10874993.html
论文作者:Sefik Emre Eskimez , Kazuhito Koishida
摘要
语音超分辨率(SSR)或语音带宽扩展的目标是由给定的低分辨率语音信号生成缺失的高频分量。它有提高电信质量的潜力。我们提出了一种新的SSR方法,该方法利用生成对抗网络(GANs)和正则化(regularization)方法来稳定GAN训练。生成器网络是有一维卷积核的卷积自编码器,沿时间轴运行,输入低频对数功率谱产生高频对数功率谱。我们使用两种最新的基于深度神经网络(DNN)的方法与我们提出的方法进行比较,包括客观的语音质量度量和主观的感知测试。结果表明,该方法在客观评价和主观评价方面均优于基线方法。
关键字:生成对抗性网络,语音超分辨率,人工语音带宽扩展
1、引言
语音增强是语音处理领域研究的热点问题之一。语音增强的主要目的是提高输入语音信号的质量和可懂度。大部分的工作在这一领域关注消除背景噪音或混响,其中一些关注生成丢失的高频内容增加语音信号的分辨率,也就是文献中说的人工语音带宽扩展或语音超分辨率(SSR)。在本文的剩下部分中,我们将这个问题称为SSR。
SSR在许多实际场景中都有应用,并具有改善人们生活质量的潜力。一个典型的例子是公共交换电话网(PSTN),它的带宽仍然被限制在一个窄带(300-3400 Hz)。在的研究中[1]表明,与窄带相比,用户更喜欢高分辨率的语音信号。Kepler等人指出[2],窄带语音对听力受损人群在通过电话交流时具有困难性。在另一项研究中,Liu等人的表明[3],认为的将分辨率从窄带提高到宽带(高达8 kHz),可以提高人工耳蜗使用者的语音识别率。
本文介绍了一种采用对抗性训练的语音超分辨神经网络和一种正则化方法来稳定对抗性训练。我们的灵感来自于对单个图像和视频超分辨率的对抗性训练的成功。该生成器是一个以对数功率谱图(LPS)为输入,生成相应范围高频LPS的序列到序列卷积自编码器网络。这项工作是第一作者在微软研究院实习时完成的。卷积层中的滤波器是一维的,它们沿谱图的时间轴运行。采用一维核函数,降低了训练和推理的计算复杂度。该系统重量轻,在移动设备和消费者级cpu上具有实时处理能力。训练过程如下:首先,我们在几个epoch(周期)内仅仅训练reconstruction(重构)损失来初始化生成器网络。然后,在加权重构损失的基础上,利用对抗性损失对框架进行训练。在GAN训练过程中,为了稳定辨识过程,我们在鉴别器损失中加入加权梯度penalty(惩罚)。我们使用语音技术研究中心(CSTR)的语音cloning(克隆)工具包(VCTK)语料库[4]来训练我们的系统。为了确定对未知说话人和语音条件的鲁棒性,我们使用与我们的训练集完全不同的数据集(即华尔街日报语料库(WSJ0)[5])来评估我们的系统。我们将我们的方法与基线进行比较[6,7]。结果表明,该方法在客观评价和主观评价方面均优于基线方法。一组例子可以公开获得。
论文的其余部分组织如下:第2节介绍了相关工作。第三部分概述了系统概况,神经网络框架。在第四部分,我们描述了实验的细节,并给出了客观和主观的评价结果。第五部分是本文的结论。
1、相关工作
早期的工作主要是估计语音信号的频谱包络,并对窄带到宽带信号的映射进行建模。这些工作依靠高斯混合模型(GMMs)[8 10]、隐马尔可夫模型(HMMs)[11 14]、神经网络(NNs)[6,7,15 17]来学习窄带和宽带信号之间的传递函数。最近,基于深度学习的方法[6,7]优于这些方法。
Li等人提出了一种DNN来从窄带的LPS预测宽带的对数功率谱(LPS)。为了人为地创建缺失的相位信息,他们将低频频段的相位翻转为高频频段的相位,重构时域信号。他们证明了他们的方法优于基于GMM的方法。Kuleshov等人提出直接使用原始波形,并引入端到端网络。他们使用了一个具有均方误差(MSE)目标函数的卷积自编码网络。与基于信号处理的方法相比,由于没有预处理,该方法的实现更加直观。但是,它的计算开销很大,可能不适合在边缘设备上运行。
生成对抗网络(GANs)[18]在图像、视频和语音生成任务中表现出强大的功能。GANs本质上是一个零和博弈,包含多个神经网络,通常是一个生成器和一个鉴别器。生成器试图通过生成虚假但真实的数据来欺骗鉴别器,而鉴别器则试图区分真实数据和虚假数据。虽然GANs取得了令人印象深刻和现实的结果,但它们在训练[19]时存在不稳定性。研究人员通过引入正则化来稳定GAN框架[19 23]。其中一些正则化方法对梯度的范数进行了惩罚,以稳定训练[19,21,23]。
GANs已成功应用于图像和视频的超分辨率[24,25]。由于谱图类似于图像或视频帧,这些研究激励我们研究语音超分辨率背景下的对抗性网络。
Li等人最近提出了一种基于对抗性训练的语音带宽扩展方法。他们的神经网络(NN)通过线谱频率(LSF)、delta LSF和低频段信号的语音能量来预测高频段的线谱频率(LSF)和语音能量(HB)。生成器和鉴频器是四层完全连接的神经网络。利用预测的语音参数,采用EVRC-WB框架[27]和合成滤波器组 合成高分辨率语音信号。我们的方法和[26]都使用了GAN框架进行SSR。然而,我们的方法直接生成语音谱图,并使用正则化方法来稳定GAN训练,而[26]使用估计LSF和能量参数的合成框架来合成语音。
3、提出的方法
下面,我们将描述我们的系统在推理过程中是如何工作的。设x为窄带语音的时域波形。首先对x进行短时傅里叶变换(STFT),然后由x计算对数功率谱图(LPS)$X^{NB}$和相位谱图$X_P$。将原始窄带和预测的高频LPSs连接(concatenated)起来,得到估计的宽带LPS $X^{SR}$。我们还预测了窄带谱图的最高C频率bins,其中C为offset(偏移)参数。在级联过程中,将小于C频率bin的窄带谱图与预测的高频范围进行级联。这样,我们就避免了连接处的不连续[6]。我们跟随Li等人的[6],通过翻转窄带相位并还原信号来创建一个人工相位。对于2x超分辨率版本,我们将这个翻转相位与窄带相位连接起来,得到整个宽带信号的人工相位$\hat{X}_P$。对于4x超分辨率版本,我们重复翻转相位三次。最后,利用估计宽带LPS $X^{SR}$和人工相位$\hat{X}_P$的逆STFT,采用overlap-add(叠加叠加法)对时域信号进行重构。系统概述如图1所示

图1:测试期间提出的语音超分辨(SSR)系统概述。将短时傅里叶变换(STFT)应用于时域信号x,得到了对数功率谱(LPS) $X^{NB}$和相位谱$X_P$。将窄带(NB) LPS $X^{NB}$fed to(馈入)SSR-GAN,得到估计高频(HF)范围LPS,并将其连接到NB LPS上,得到宽带(WB) LPS $\hat{X}^{SR}$。通过翻转和重复NB相位$X_P$,加上一个负号,人为地产生HF范围的相位。最后,利用估计的WB LPS和人工相位,通过逆STFT (ISTFT)和叠加重建时域信号$\hat{y}$。
3.1 网络体系结构
该生成器是一个(序列到序列)sequence-to-sequence的模型,它接受T个时间步长的窄带LPS,输出带T个时间步长的高频范围LPS。我们使用[7]中描述的常见瓶颈自动编码器架构。卷积核是一维的,它在LPSs的时间轴上运行。与2D内核相比,计算成本要低得多,允许在cpu和移动设备上实时处理网络。我们在卷积层之后使用batch normalization(批标准化(BN))层,然后是斜率为0.2的LeakyReLU激活函数,输出层除外,在输出层中我们使用线性激活,而不使用BN层。我们使用[28]中引入的sup-pixel(亚像素)(或pixel shufle(像素洗牌))层进行向上采样,这对于图像和视频的超分辨率非常有用。
该鉴别器包括三个卷积层,然后是两个全连接层(FC)。我们使用LeakyReLU激活,除输出层外,所有层的斜率为0.2,在输出层中我们使用线性激活函数。由于BN层在鉴别器网络训练过程中会导致训练的不稳定性,尤其是当鉴别器损失正规化时[19,23],我们不使用BN层。鉴别器网络接收连接的窄带和高频范围LPSs作为输入。高频范围LPS可以直接来自于数据分布,也可以由生成器网络产生。这两种网络架构的详细信息如表1所示。

表1:提出的网络架构的详细参数。K和N分别为沿频率轴的窄带和高频范围LPS尺寸。对于2x和4x超分辨率尺度,K分别为129和65。对于2x和4x的超分辨率尺度,N分别为141和199。
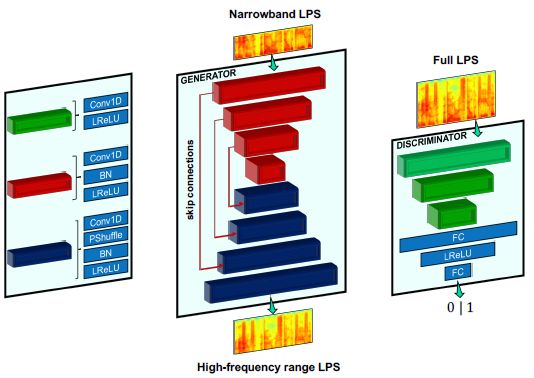
图2:提出的生成器(中)和鉴别器(右)的网络结构。每个矩形块都是一个卷积层,结构颜色编码并在左侧子图中详细显示。符号:BN :批次归一化层、FC :全连接层、LReLU:LeakyReLU激活层、PShuffle:pixel shuffle或sub-pixel层、LPS:对数功率谱。
3.2 训练目标函数
首先,我们初始化生成器,在仅有重构损失时训练几个周期。生成器通常初始化训练后生成过于平滑的结果。为了获得更清晰、更详细的LPSs,我们在重构损失的基础上改用对抗性损失(GAN损失)。我们使用对数光谱距离(LSD)(或对数光谱失真)函数作为训练目标。LSD测量两个频谱之间的距离(以分贝为单位),其数学定义如下
$$公式1:l_{LSD}=\frac{1}{L}\sum_{l=1}^{L}\sqrt{\frac{1}{K}\sum_{k=1}^{K}[X^{HR}(l,k)-X^{SR}(l,k)]^2}$$
其中K为频率bin数,$X^{HR}$和$X^{SR}$分别为ground tuth和估计LPSs。
原始的生成式对抗网络(GAN)是一个生成器和一个鉴别器之间的零和博弈(极小极大)。我们在SSR的上下文中对这个问题进行了阐述,其定义如下
$$公式2:\begin{matrix}
\min_{\theta }\max_{\psi }E_P[\log D_{\psi}(X^{HR})]+E_Q[\log (1-D_{\psi}(G_{\theta}(X^{NB})))] \\
P:X^{HR}~p(X^{HR})\\
Q:X^{NB}~p(X^{NB})
\end{matrix}$$
其中$X^{HR}$是高分辨率数据(真实数据),$X^{NB}$是窄带数据。$G_{\theta}(·)$是生成器,$G_{\psi }(·)$是鉴别器,其中$\theta$和$\psi$是可训练参数。$P$是真实数据的分布,$Q$是窄带数据的分布。发生器$(G_{\theta}(·))$处理窄带和高带频谱的串联。这个符号可以简化如下:
$$公式3:\min_{\theta }\max_{\psi }E_P[\log {\varphi}_R]+E_Q[\log (1-{\varphi}_F)]$$
其中${\varphi}_R$和${\varphi}_F$分别是真假数据的鉴别器输出。
为了稳定GAN训练,我们对[23]中描述的判别器的加权gradient-norms(梯度规范)进行了惩罚。正则化项描述为
$$公式4:\Omega =E_P[(1-\varphi_R)^2||\bigtriangledown \phi_R||^2]+E_Q[\varphi_F^2||\bigtriangledown \phi _F||^2]$$
我们将这一项加到鉴别器的目标函数中,如下:
$$公式5:l_{DIS}=E_P[\log \varphi_R]+E_Q[\log(1-\varphi _F)]-\frac{\gamma }{2}\Omega $$
其中为正则化项的权值。
生成器损失为重构损耗和GAN损失的加权和,定义如下
$$公式6:l_{GEN}=E_Q[-\log (D_\varphi(G_{\theta}(X^{NB})))]+\lambda l_{LSD}$$
其中,$l_{LSD}$为式1中描述的目标函数,为LSD损失的权重参数。
4、实验
我们使用CSTR语音cloning工具包语料库(VCTK)来训练我们的网络,它最初是为训练文本到语音(TTS)合成系统而设计的。录音为16位WAV文件,采样率为48khz,语音清晰。共有109名不同口音的英语人士,每个人说400个句子。我们使用六个随机的说话人的语音作为验证集,并使用其余的语音作为训练数据集。为了创建训练对,我们将[29]中描述的带限sinc插值方法处理高分辨率信号,以获得下采样版本。
为了评估我们的网络的泛化能力,我们使用了华尔街日报语料库(WSJ0)数据集来进行评估,它与VCTK语料库的说话者和语音条件不同。录音采样率为16khz,其中包含自然背景噪声。在我们的客观评估中,我们使用了5000个样本(大约12小时)的随机子集。
我们的网络仅使用LSD损失(式1)进行50个epoch的训练,学习率为$10^{-4}$,使用GAN + LSD损失(式6)进行另外100个epoch的训练,学习率为$10^{-5}$。我们通过实验确定了周期数。我们的输入和输出频谱的time-steps(时间步长)被设置为32。我们使用Adam 优化器来训练生成器网络,使用RMSProp优化器来训练识别器网络,其mini-batch(小批处理)大小为64。将输入输出LPSs归一化为零均值和单位方差;我们从训练数据中计算出这些统计数据,并将其应用于推理。表1所示的K变量对于2x实验为129,对于4x实验为65。频率偏移量按下式计算
$$公式7:floor(\frac{K}{10})+1$$
其中K为输入频谱中频率bin数。表1所示的N变量在2x和4x超分辨率尺度下分别设置为141和199。我们将方程5所示的变量$\gamma$设为2。
我们从第2节中描述的现有工作中采用了两种基线方法。第一个基线是基于STFT的方法[6],在本文的其余部分中我们将其命名为$BL1$。由于这项工作只考虑了2x SSR,所以我们没有实现4x SSR版本。第二个基线是基于原始波形的方法[7],在本文的其余部分中我们将其命名为$BL2$。我们采用了作者提供的代码来重现2x和4x SSR的结果。我们将提议的方法命名为SSR-GAN。
4.1 客观指标
我们采用式1中定义的LSD,分段信噪比(segmental signal to noise ratio, SegSNR) [30],和语音质量感知评价(PESQ)[31]客观指标,以评价和比较我们的方法与基线方法。这些指标广泛应用于语音增强和SSR工作。PESQ测量的是语音质量,由国际电信联盟电信标准化部门(ITU-T)标准化。分段信噪比(SegSNR)是音频样本段上的信噪比均值,定义如下
$$SegSNR=\frac{1}{L}\sum_{l=1}^{L}10\log \frac{\sum_{n=1}^{N}[x(l,n)]^2}{\sum_{n=1}^{N}[x(l,n)-\hat{x}(l,n)]^2}$$
其中L为段数,N为语音中的数据点数。对于SegSNR和PESQ,值越高越好;对于LSD,数值越低越好。
4.2 结果
客观评价结果如表2所示。我们的方法在2x和4x SSR任务中都优于基线,在所有三个客观评价指标方面都有很好的优势。与$BL1$相比,LSD值提高了约1.1 dB。对于SegSNR,改进大约是3.9 dB。PESQ略有改善,约为0.1。与$BL2$相比,我们的方法在4x设置下的改进更为明显。LSD对高频范围和全频谱的改善分别为3.3 dB和4.7 dB左右。SegSNR提高了4.7 dB左右。与2x量表相比,PESQ明显提高,约为0.5。
表2:2x和4x SSR实验的客观评价结果。我们的方法(SSR-GAN)在所有指标上都优于基线。LSD HF为仅在高频范围计算的LSD值,其中LSD Full为整个频谱计算的LSD值。

图3为示例谱图,其中第一行为ground truth高频范围语谱图,第二行为仅经过LSD损失训练的神经网络得到的高频范围语谱图,第三行分别为2x和4x的SSRGAN结果。注意,第二行上的LPSs过于平滑。经过GAN训练(第三排),效果更加清晰,细节更加精细,精力更加充沛。
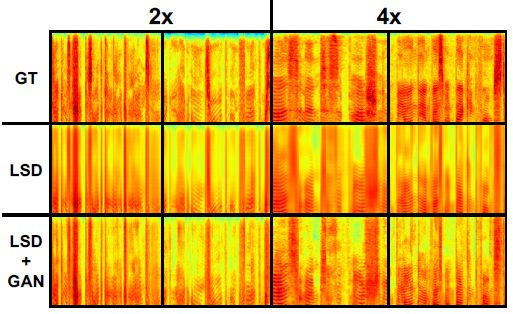
图3:给出了2x和4x的光谱图示例。这些样本是从WSJ0语料库中随机抽取的。第一行是ground truth高频范围语谱图。第二行和第三行显示了只训练LSD损耗(第二行)和同时训练LSD和GAN损耗(第三行)的提出的网络生成的高频范围语谱图。
4.3 主观的评价
我们进行了主观评估,以测试我们的方法与基线和ground truth数据在人类感知方面的比较。我们生成了两个测试集,每个测试集包含40个句子,每个句子的缩放分别为2x和4x。包括窄带信号、ground truth高分辨率信号、预测超分辨率信号和基线。我们想把每个项目的测试时间限制在30分钟之内;因此,我们对每个分辨率缩放只使用基线方法之一的样本,对2x和4x分别使用[6]和[7]。共有20名志愿者,他们每人评估了80个样本。每个志愿者都通过听5对低分辨率和ground truth高分辨率的语音。将测试样本随机呈现给志愿者,每个样本的得分在0到100之间,其中0代表低分辨率信号,100代表高分辨率信号。
2x和4x缩放实验结果如图4所示。ground truth高分辨语音的得分为80.79%,其次是我们的方法,得分为70.72%。低分辨率信号和$BL1$的得分较低,分别为21.75%和34.52%。由于SSR-GAN评分接近高分辨率信号,我们可以得出结论,在2x尺度下,SSR-GAN可以在语音质量上说服听众,并且可以优于基线方法。4x实验更具挑战性,与2x实验相比,缺失的相位信息更加明显。高分辨率分数与SSRGAN之间的差距约为32%。SSR-GAN仍然可以超过基线方法,并且有超过50%的得分。

图4:2x和4x量表的主观测试结果。
5 结论
在这项工作中,我们提出了一种新的方法,利用对抗性训练语音超分辨率任务。通过客观和主观评价,我们的方法优于基于DNN的基线方法。主观评价表明,对于2倍分辨率的尺度,我们的方法可以得到接近地面真实的高分辨率信号,对于4倍分辨率的尺度,我们的方法可以获得较好的性能。该方法计算量小,能够在边缘设备上实时运行。我们未来的工作包括利用频谱估计相位信息。
6 参考文献
[1] ITU, “Paired comparison test of wideband and narrowband telephony,” in Tech. Rep. COM 12-9-E. Mar. 1993.
[2] Laura Jennings Kepler, Mark Terry, and Richard H Sweetman, “Telephone usage in the hearing-impaired population.,” Ear and hearing,
vol. 13, no. 5, pp. 311–319, 1992.
[3] Chuping Liu, Qian-Jie Fu, and Shrikanth S Narayanan, “Effect of bandwidth extension to telephone speech recognition in cochlear implant users,” The Journal of the Acoustical Society of America, vol. 125, no.2, pp. EL77–EL83, 2009.
[4] Christophe Veaux, Junichi Yamagishi, Kirsten MacDonald, et al.,“Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit,” University of Edinburgh. The Centre for Speech Technology Research (CSTR), 2016.
[5] John Garofalo, David Graff, Doug Paul, and David Pallett, “Csr-i(wsj0) complete,” Linguistic Data Consortium, Philadelphia, 2007.
[6] Kehuang Li and Chin-Hui Lee, “A deep neural network approach to speech bandwidth expansion,” in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on. IEEE,2015, pp. 4395–4399.
[7] Volodymyr Kuleshov, S Zayd Enam, and Stefano Ermon, “Audio super resolution using neural networks,” arXiv preprint arXiv:1708.00853,2017.
[8] Kun-Youl Park, “Narrowband to wideband conversion of speech using gmm based transformation,” in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). IEEE, 2000, pp.1843–1846.
[9] Samir Chennoukh, A Gerrits, G Miet, and R Sluijter, “Speech enhancement via frequency bandwidth extension using line spectral frequencies,” in Acoustics, Speech, and Signal Processing, 2001. Proceedings.(ICASSP’01). 2001 IEEE International Conference on. IEEE,2001, vol. 1, pp. 665–668.
[10] Hyunson Seo, Hong-Goo Kang, and Frank Soong, “A maximum a posterior-based reconstruction approach to speech bandwidth expansion in noise,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2014, pp. 6087–6091.
[11] Peter Jax and Peter Vary, “Artificial bandwidth extension of speech signals using mmse estimation based on a hidden markov model,” in IEEE International Conference on Acoustics, Speech, and Signal Processing(ICASSP). IEEE, 2003, vol. 1, pp. I–I.
[12] Guo Chen and Vijay Parsa, “Hmm-based frequency bandwidth extension for speech enhancement using line spectral frequencies,” in Acoustics,Speech, and Signal Processing, 2004. Proceedings.(ICASSP’04).IEEE International Conference on. IEEE, 2004, vol. 1, pp. I–709.
[13] Patrick Bauer and Tim Fingscheidt, “An hmm-based artificial bandwidth extension evaluated by cross-language training and test,” in Acoustics, Speech and Signal Processing, 2008. ICASSP 2008. IEEE International Conference on. IEEE, 2008, pp. 4589–4592.
[14] Geun-Bae Song and Pavel Martynovich, “A study of hmm-based bandwidth extension of speech signals,” Signal Processing, vol. 89, no. 10,pp. 2036–2044, 2009.
[15] Bernd Iser and Gerhard Schmidt, “Neural networks versus codebooks in an application for bandwidth extension of speech signals,” in Eighth European Conference on Speech Communication and Technology,2003.
[16] Juho Kontio, Laura Laaksonen, and Paavo Alku, “Neural networkbased artificial bandwidth expansion of speech,” IEEE transactions on audio, speech, and language processing, vol. 15, no. 3, pp. 873–881,2007.
[17] Johannes Abel and Tim Fingscheidt, “Artificial speech bandwidth extension using deep neural networks for wideband spectral envelope estimation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 1, pp. 71–83, 2018.
[18] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio,“Generative adversarial nets,” in Advances in neural information processing systems, 2014, pp. 2672–2680.
[19] Lars Mescheder, Andreas Geiger, and Sebastian Nowozin, “Which training methods for gans do actually converge?,” in International Conference on Machine Learning, 2018, pp. 3478–3487.
[20] Martin Arjovsky, Soumith Chintala, and L´eon Bottou, “Wasserstein generative adversarial networks,” in International Conference on Machine Learning, 2017, pp. 214–223.
[21] Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin,and Aaron C Courville, “Improved training of wasserstein gans,” in Advances in Neural Information Processing Systems, 2017, pp. 5767–5777.
[22] Casper Kaae Sønderby, Jose Caballero, Lucas Theis, Wenzhe Shi, and Ferenc Husz´ar, “Amortised map inference for image super-resolution,”arXiv preprint arXiv:1610.04490, 2016.
[23] Kevin Roth, Aurelien Lucchi, Sebastian Nowozin, and Thomas Hofmann, “Stabilizing training of generative adversarial networks through regularization,” in Advances in Neural Information Processing Systems,2017, pp. 2018–2028.
[24] Christian Ledig, Lucas Theis, Ferenc Husz´ar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew P Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al., “Photo-realistic single image superresolution using a generative adversarial network.,” in CVPR, 2017,vol. 2, p. 4.
[25] Alice Lucas, Santiago Lopez Tapia, Rafael Molina, and Aggelos K Katsaggelos,“Generative adversarial networks and perceptual losses for video super-resolution,” arXiv preprint arXiv:1806.05764, 2018.
[26] Sen Li, St´ephane Villette, Pravin Ramadas, and Daniel J Sinder,“Speech bandwidth extension using generative adversarial networks,”in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 5029–5033.
[27] 3GPP2 C.S0014-C v1.0, “Enhanced variable rate codec, speech service option 3, 68 and 70 for wideband spread spectrum digital systems,” .
[28] Wenzhe Shi, Jose Caballero, Ferenc Husz´ar, Johannes Totz, Andrew PAitken, Rob Bishop, Daniel Rueckert, and Zehan Wang, “Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1874–1883.
[29] Julius O. Smith, “Digital audio resampling home page center for computer research in music and acoustics (ccrma),” .
[30] Paul Mermelstein, “Evaluation of a segmental snr measure as an indicator of the quality of adpcm coded speech,” The Journal of the Acoustical Society of America, vol. 66, no. 6, pp. 1664–1667, 1979.
[31] AWRix, J Beerends, M Hollier, and A Hekstra, “Perceptual evaluation of speech quality (pesq), an objective method for end-to-end speech quality assessment of narrowband telephone networks and speech codecs,” ITU-T Recommendation, vol. 862, 2001.