排序算法
经典排序算法:
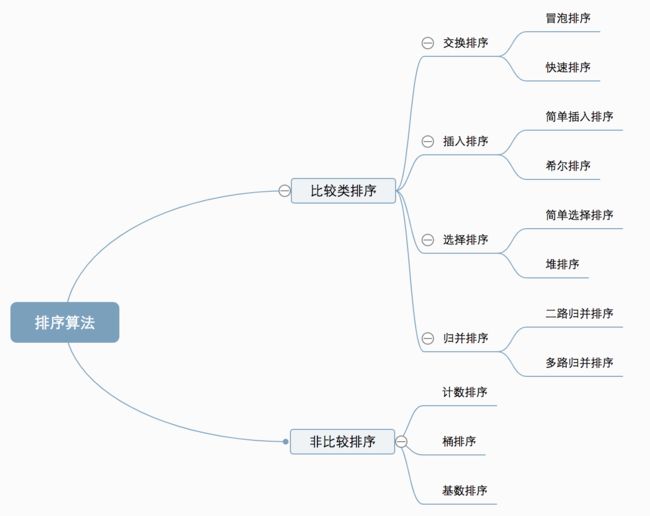
目录
一 冒泡排序(BubbleSort)
二 选择排序(SelctionSort)
三 插入排序(Insertion Sort)
四 希尔排序(Shell sort)
五 归并排序(merge sort)
六 快速排序(Quick Sort)
七 堆排序(HeapSort)
八 计数排序(Counting Sort)
九 桶排序(Bucket Sort)
十 基数排序(Radix Sort)
reference
一 冒泡排序(BubbleSort)
基本思想:两个数比较大小,较大的数下沉,较小的数冒起来。
过程:
- 比较相邻的两个数据,如果第二个数小,就交换位置。
- 从后向前两两比较,一直到比较最前两个数据。最终最小数被交换到起始的位置,这样第一个最小数的位置就排好了。
- 继续重复上述过程,依次将第2.3...n-1个最小数排好位置。

时间复杂度: \(O\left(n^{2}\right)\)
代码(c++):
for (int i = 0; i < nums.size() - 1; i++)
{
for (int j = 0; j < nums.size() - i - 1; j++)
{
if (nums[j] > nums[j + 1])
{
int temp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = temp;
}
}
}
优化:
- 针对问题:
数据的顺序排好之后,冒泡算法仍然会继续进行下一轮的比较,比如数据中有部分数据是有序的 - 方案:
设置标志位flag,如果发生了交换flag设置为true;如果没有交换就设置为false。这样当一轮比较结束后如果flag仍为false,即:这一轮没有发生交换,说明数据的顺序已经排好,没有必要继续进行下去。 - 代码:
for (int i = 0; i < nums.size() - 1; i++)
{
bool flag = false;
for (int j = 0; j < nums.size() - i - 1; j++)
{
if (nums[j] > nums[j + 1])
{
int temp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = temp;
flag = true;
}
}
if(!flag)
break;
}
二 选择排序(SelctionSort)
基本思想:
在长度为N的无序数组中,第一次遍历n-1个数,找到最小的数值与第一个元素交换;
第二次遍历n-2个数,找到最小的数值与第二个元素交换;
。。。
第n-1次遍历,找到最小的数值与第n-1个元素交换,排序完成。
过程:

时间复杂度: \(O\left(n^{2}\right)\)
代码:
for (int i = 0; i < nums.size(); i++)
{
int min = i;
for (int j = i + 1; j < nums.size(); j++)
{
if (nums[j] < nums[min])
{
min = j;
}
}
int temp = nums[i];
nums[i] = nums[min];
nums[min] = temp;
}三 插入排序(Insertion Sort)
如果数据序列基本有序,使用插入排序会更加高效。
基本思想:
在要排序的一组数中,假定前n-1个数已经排好序,现在将第n个数插到前面的有序数列中,使得这n个数也是排好顺序的。如此反复循环,直到全部排好顺序。
过程:

时间复杂度:\(O\left(n^{2}\right)\)
代码:
for (int i = 1; i < nums.size(); i++)
{
for (int j = i; j > 0; j--)
{
if (nums[j] < nums[j - 1])
{
int temp = nums[j];
nums[j] = nums[j - 1];
nums[j - 1] = temp;
}
}
}四 希尔排序(Shell sort)
基本思想:
这个算法可以看作是插入排序的优化版,因为插入排序需要一位一位比较,然后放置到正确位置。为了提升比较的跨度,希尔排序将数组按照一定步长分成几个子数组进行排序,通过逐渐减短步长来完成最终排序。
过程:
时间复杂度:
希尔排序的时间复杂度受步长的影响
代码:
// 没看懂
void shell_sort(vector &nums)
{
for (int gap = nums.size() >> 1; gap > 0; gap >>= 1)
{
for (int i = gap; i < nums.size(); i++)
{
int temp = nums[i];
int j = i - gap;
for (; j >= 0 && nums[j] > temp; j -= gap)
{
nums[j + gap] = nums[j];
}
nums[j + gap] = temp;
}
}
} 五 归并排序(merge sort)
基本思想:
首先考虑下如何将2个有序数列合并。这个非常简单,只要从比较2个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
算法描述:
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
过程:
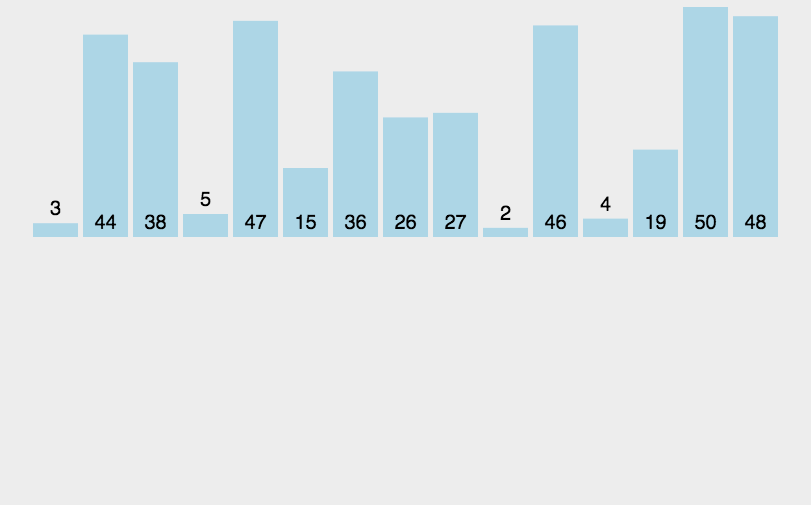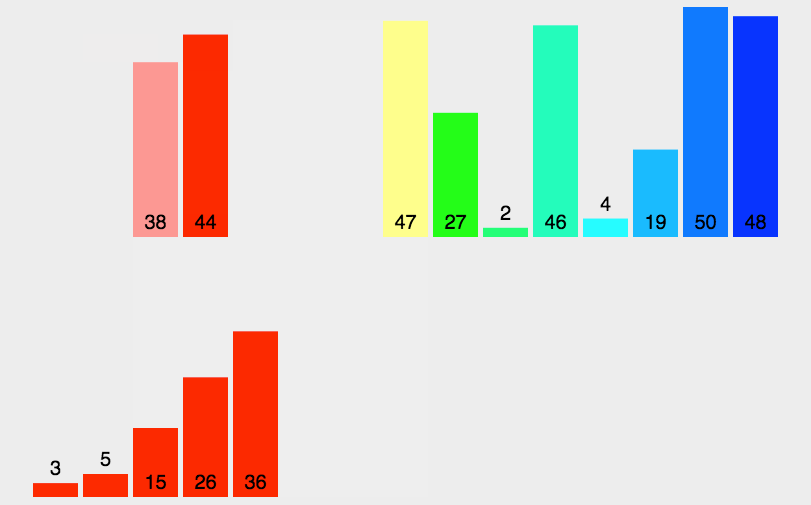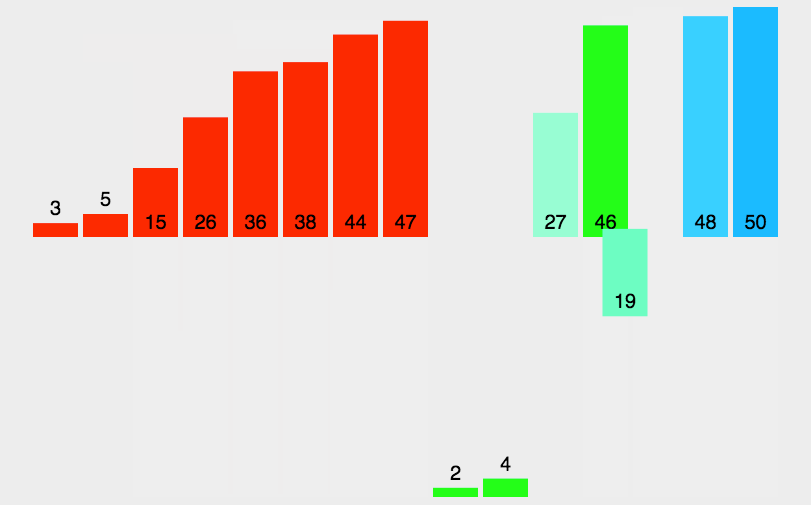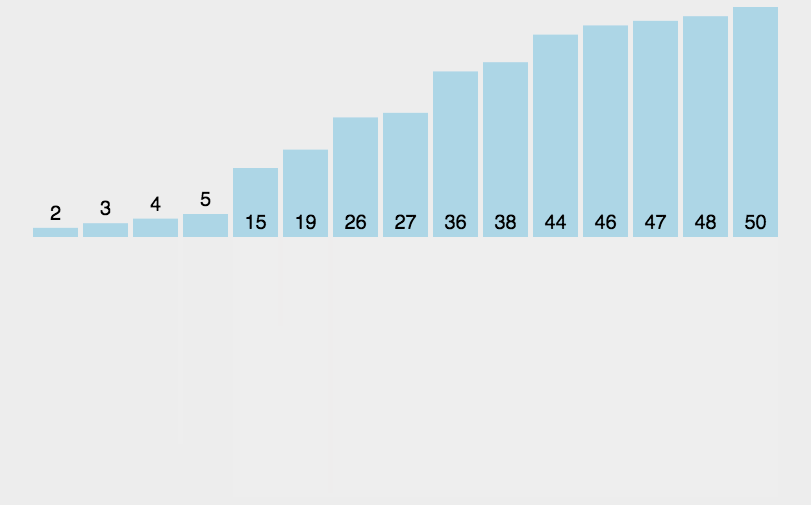
复杂度分析:
实际的操作是当前两个子数组的长度,即2m。又因为打散数组是二分的,最终循环执行数是logn。所以这个算法最终时间复杂度是O(nlogn),空间复杂度是O(n)。
代码:
// 没看懂
void merge_array(vector &nums, int b, int m, int e, vector &temp)
{
int lb = b, rb = m, tb = b;
while (lb != m && rb != e)
if (nums[lb] < nums[rb])
temp[tb++] = nums[lb++];
else
temp[tb++] = nums[rb++];
while (lb < m)
temp[tb++] = nums[lb++];
while (rb < e)
temp[tb++] = nums[rb++];
for (int i = b;i < e; i++)
nums[i] = temp[i];
}
void merge_sort(vector &nums, int b, int e, vector &temp)
{
int m = (b + e) / 2;
if (m != b)
{
merge_sort(nums, b, m, temp);
merge_sort(nums, m, e, temp);
merge_array(nums, b, m, e, temp);
}
}
六 快速排序(Quick Sort)
基本思想:
- 先从数列中取出一个数作为key值;
- 将比这个数小的数全部放在它的左边,大于或等于它的数全部放在它的右边;
- 对左右两个小数列重复第二步,直至各区间只有1个数。
过程:

代码:
void quick_sort(vector &nums, int b, int e, vector &temp)
{
int m = (b + e) / 2;
if (m != b) {
int lb = b, rb = e - 1;
for (int i = b; i < e; i++) {
if (i == m)
continue;
if (nums[i] < nums[m])
temp[lb++] = nums[i];
else
temp[rb--] = nums[i];
}
temp[lb] = nums[m];
for (int i = b; i < e; i++)
nums[i] = temp[i];
quick_sort(nums, b, lb, temp);
quick_sort(nums, lb + 1, e, temp);
}
} 七 堆排序(HeapSort)
基本思想:
因为最大堆的第一位总为当前堆中最大值,所以每次将最大值移除后,调整堆即可获得下一个最大值,通过一遍一遍执行这个过程就可以得到前k大元素,或者使堆有序。
过程:
- 构造最大堆(Build Max Heap):首先将当前元素放入最大堆下一个位置,然后将此元素依次和它的父节点比较,如果大于父节点就和父节点交换,直到比较到根节点。重复执行到最后一个元素。
- 最大堆调整(Max Heapify):调整最大堆即将根节点移除后重新整理堆。整理方法为将根节点和最后一个节点交换,然后把堆看做n-1长度,将当前根节点逐步移动到其应该在的位置。
- 堆排序(HeapSort):重复执行2,直到所有根节点都已移除。
代码:
void heap_sort(vector &nums)
{
int n = nums.size();
for (int i = n / 2 - 1; i >= 0; i--) { // build max heap
max_heapify(nums, i, nums.size() - 1);
}
for (int i = n - 1; i > 0; i--) { // heap sort
int temp = nums[i];
num[i] = nums[0];
num[0] = temp;
max_heapify(nums, 0, i);
}
}
void max_heapify(vector &nums, int beg, int end)
{
int curr = beg;
int child = curr * 2 + 1;
while (child < end) {
if (child + 1 < end && nums[child] < nums[child + 1]) {
child++;
}
if (nums[curr] < nums[child]) {
int temp = nums[curr];
nums[curr] = nums[child];
num[child] = temp;
curr = child;
child = 2 * curr + 1;
} else {
break;
}
}
} 好像和选择排序差不多,只是每次选择最大值的方式不一样。
八 计数排序(Counting Sort)
基本思想:
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
过程:
- 找出待排序的数组中最大和最小的元素;
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
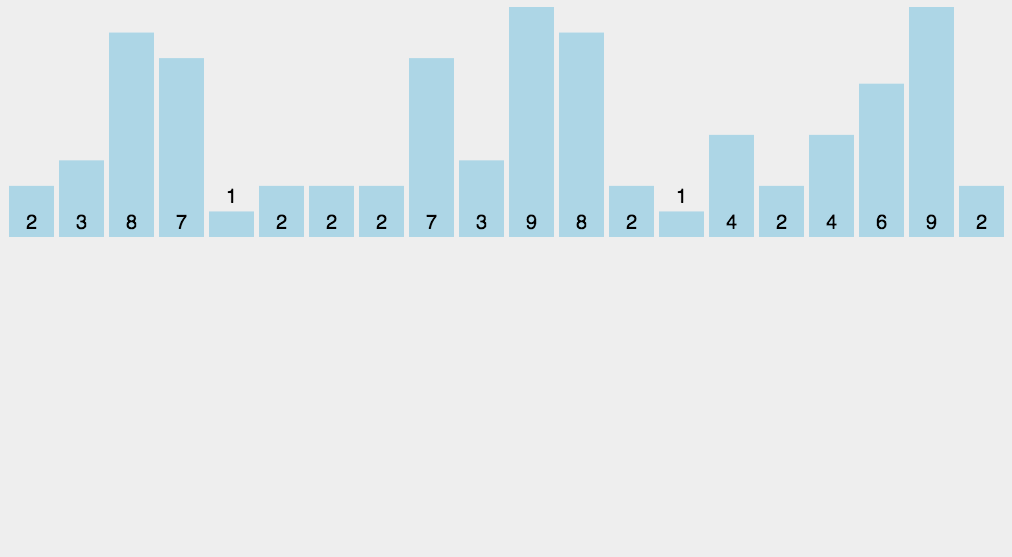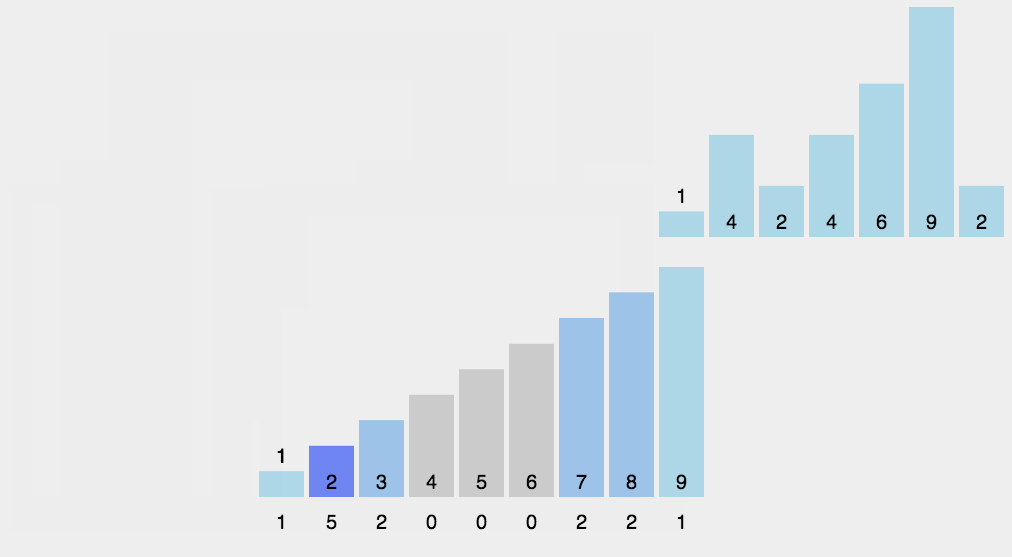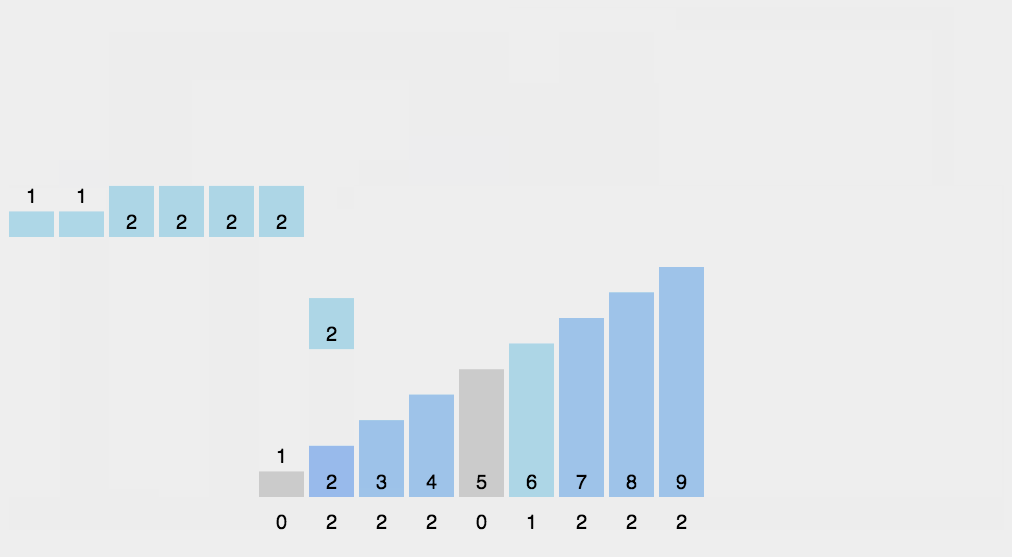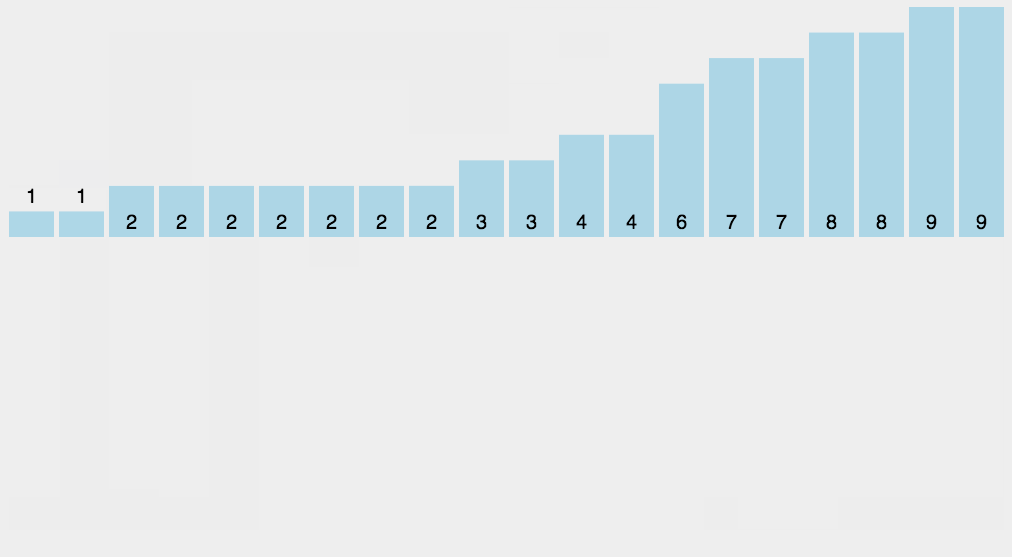
代码:
九 桶排序(Bucket Sort)
基本思想:
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。
过程:
- 设置一个定量的数组当作空桶;
- 遍历输入数据,并且把数据一个一个放到对应的桶里去;
- 对每个不是空的桶进行排序;
- 从不是空的桶里把排好序的数据拼接起来。
十 基数排序(Radix Sort)
基本思想:
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
过程:
- 取得数组中的最大数,并取得位数;
- arr为原始数组,从最低位开始取每个位组成radix数组;
- 对radix进行计数排序(利用计数排序适用于小范围数的特点);

reference
- https://www.cnblogs.com/onepixel/p/7674659.html
- https://www.runoob.com/w3cnote/sort-algorithm-summary.html
- http://yansu.org/2015/09/07/sort-algorithms.html