CVPR2020 3D目标检测文章汇总
前言
今年CVPR20-paper-list前几天已经出了,所以这里做一点大致的综述介绍在CVPR20上在3D目标检测的一些文章。如下图所示,3D目标检测按照大方向可以分为室外和室内的目标检测,室内场景数据集一般有ScanNet等,该领域研究比较少,笔者注意到的第一篇文章是来自FAIR的voteNet,采用霍夫投票机制生成了靠近对象中心的点,利用这些点进行分组和聚合,以生成box proposals。今年在CVPR20上也至少有两篇该文章的后续工作,分别是来自pointnet之父的Imvotenet,地址是:https://arxiv.org/pdf/2001.10692.pdf;另外一篇MLCVNet来自南京大学和卡迪夫大学的联合工作 ,文章地址:https://arxiv.org/pdf/2004.05679,该文章在vote的基础上利用自注意力机制融合Multi-scale的特征。
此外,在室外场景的目标检测中,可以大致按照输入分为lidar-input,image-input和multi-sensors-fusion的研究工作。
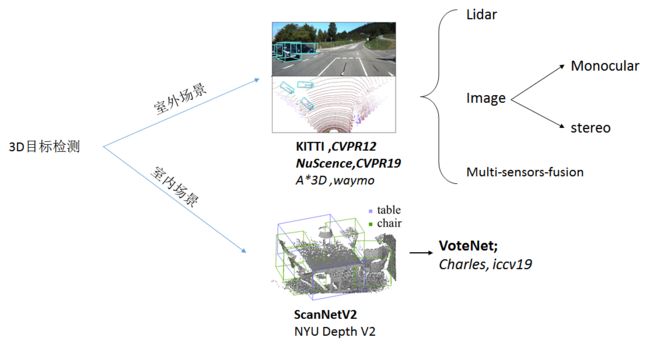
1. CVPR20 室内目标检测文章
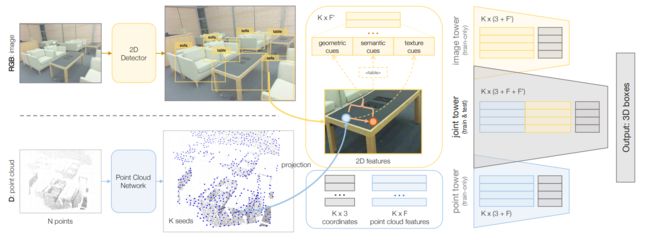
ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes
文章地址: https://arxiv.org/pdf/2001.10692.pdf
类似该作者的另外一篇文章F-Pointnet,同样通过将二维目标检测结果融合到三维中做目标检测任务。作者挖掘了几何结构和语义特征两方面的信息,并将这些信息通过相机参数和雷达几何变换融合在三维信息中,最终实验显示比之前的SOTA高出5.7 map。
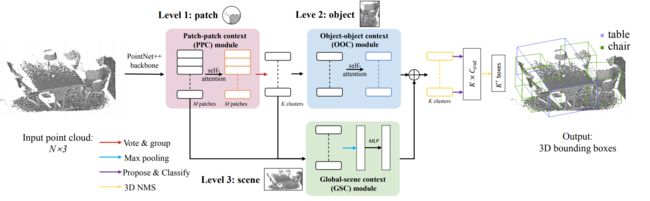
MLCVNet: Multi-Level Context VoteNet for 3D Object Detection
文章地址为 https://arxiv.org/pdf/2004.05679
代码地址: https://github.com/NUAAXQ/MLCVNet
来自南京大学和卡迪夫大学的合作工作。
本文利用自注意机制和多尺度特征融合,捕获multi-scale的上下文信息来做目标检测。作者首先使用一个Patch-to-Patch Context (PPC)模块来获取点patch之间的上下文信息,然后投票选择对应的目标质心点。随后,一个对象到对象上下文(OOC)模块在提议和分类阶段之前被合并,以捕获候选对象之间的上下文信息。最后,设计了一个全局场景上下文(GSC)模块来学习全局场景上下文。作者的方法达到了目前最高的检测性能。
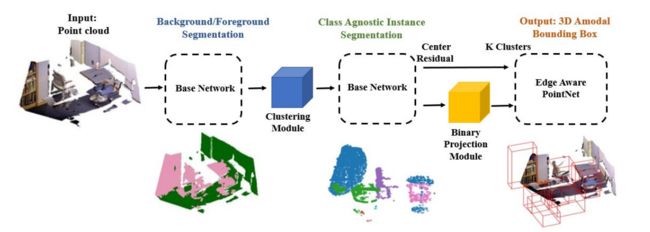
Density Based Clustering for 3D Object Detection in Point Clouds
文章地址 http://openaccess.thecvf.com/content_CVPR_2020/papers/Ahmed_Density-Based_Clustering_for_3D_Object_Detection_in_Point_Clouds_CVPR_2020_paper.pdf
在这一篇文章中,作者的新模块主要在两个方面。第一点是一个级联模块化方法,将每个模块的感受野集中在特定点上,改进特征学习。第二个模块是使用无监督聚类的实例分割模块。级联模块有序的减少进入网络的特定点。而三个不同的模块通过单独训练的基于点的网络来完成背景前景分割、无监督聚类的实例分割和对象检测的任务。在SUN RGB-D数据集上取得了比sota高的效果。
A Hierarchical Graph Network for 3D Object Detection on Point Clouds
文章链接 :http://openaccess.thecvf.com/content_CVPR_2020/papers/Chen_A_Hierarchical_Graph_Network_for_3D_Object_Detection_on_Point_CVPR_2020_paper.pdf
作者团队:浙江大学
本文提出了一种新的基于图卷积(GConv)的层次图网络(HGNet)用于三维目标检测,直接处理原始点云来预测三维bbox。
HGNet能有效地捕获点之间的关系,并利用多级语义进行目标检测。作者提出了新的关注形状的GConv (SA-GConv),通过建模点的相对几何位置来描述物体的形状,以捕获局部形状特征。基于SA-GConv的u形网络捕获多层次的特征,通过改进的投票模块将这些特征映射到相同的特征空间中,进而生成proposals。然后,基于GConv的方案推理模块基于全局场景语义对方案进行推理,并对Bbox进行预测。在SUN RGB-D上的平均平均精度(mAP)高于4%,在ScanNet-V2上的平均精度高于3%。
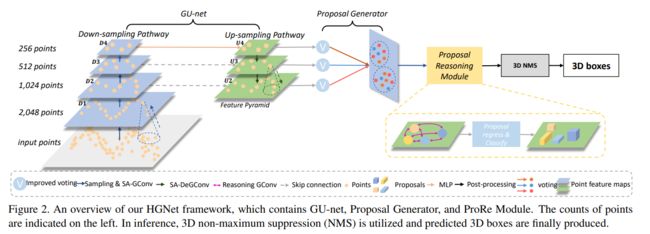
SESS: Self-Ensembling Semi-Supervised 3D Object Detection
作者团队: 新国大
文章链接: http://openaccess.thecvf.com/content_CVPR_2020/papers/Zhao_SESS_Self-Ensembling_Semi-Supervised_3D_Object_Detection_CVPR_2020_paper.pdf
代码地址: https:// github.com/Na-Z/ sess
现有的基于点云的三维物体检测方法的性能很大程度上依赖于大规模高质量的三维标注。但是,这样的注释收集起来通常很繁琐,而且成本很高。受自集成技术在半监督图像分类任务中的成功启发,作者提出了SESS,一个自集成的半监督三维物体检测框架。特别的,作者设计了一个完整的扰动方案来增强网络在未标记和新的不可见数据上的泛化性能。此外,作者提出了三种一致性损失来加强两组预测的3D-proposals之间的一致性,以促进对象的结构和语义不变性的学习.
2. 室外自动驾驶场景3D目标检测
2.1 LIDAR-input
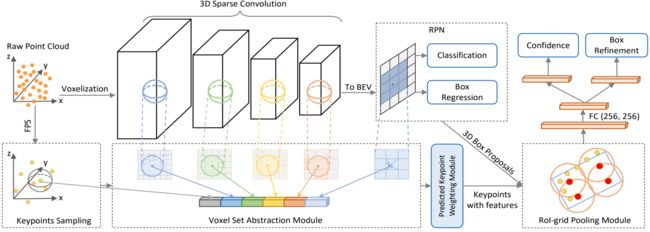
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
作者团队:MMLAB
文章地址:https://arxiv.org/pdf/1912.13192.pdf
代码地址:https://github.com/sshaoshuai/PCDet
本文的主体结构是voxel-based的两阶段方法,作者第一阶段首先对整个场景采用voxel的方法进行特征提取,同时采取一支分支对场景采用point的FPS采样,然后检索得到多尺度的voxel的特征,如下的表示。这样实际上仅仅是采用了voxel的特征,但是表示在key-point身上。第二阶段则是refine阶段,通过从voxeled feature中抽取到的特征表达在采样的point上,采用这种点的多尺度特征对proposals进行精细的回归。
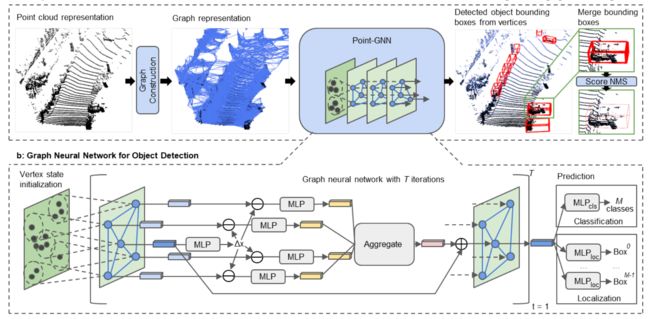
Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud
作者团队:卡内基梅隆大学
文章地址 https://arxiv.org/pdf/2003.01251v1.pdf
代码地址 https://github.com/WeijingShi/Point-GNN
这篇文章则是研究了如何采用GCN进行3D检测任务,作者首先对场景中的点采用KNN进行建图,然后设计了GCN网络结构,经过多次迭代,得到了每个节点的特征,最后采用了MLP层做回归和分类。
Structure Aware Single-stage 3D Object Detection from Point Cloud
作者团队: 港理工、达摩院
文章地址: http://www4.comp.polyu.edu.hk/~cslzhang/paper/SA-SSD.pdf
代码地址: https://github.com/skyhehe123/SA-SSD
本文核心创新是想要将二阶段方法独有精细回归运用在一阶段的的检测方法上,为此作者采用了SECOND作为backbone,添加了两项附加任务,使得backbone具有structure aware的能力,定位更加准确;此外在一阶段中存在预测框和cls maps之间不匹配的问题,本文也设计了一种Part-sensitive warping的策略解决这个问题。
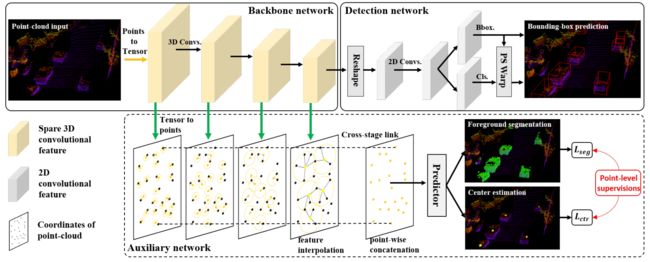
3DSSD: Point-based 3D Single Stage Object Detector
作者团队: 港中文、港科大
文章地址:https://arxiv.org/pdf/2002.10187.pdf
代码地址:https://github.com/tomztyang/3DSSD
本文主要从point-based的研究入手,考虑如何解决掉以前的point-based的方法的瓶颈,即时间和内存占有远远大于voxel-based的方法,从而作者设计了新的SA模块和丢弃了FP模块到达时间上可达25FPS,此外本文采用一个anchor free Head,进一步减少时间和GPU显存,提出了3D center-ness label的表示,进一步提高的精度。
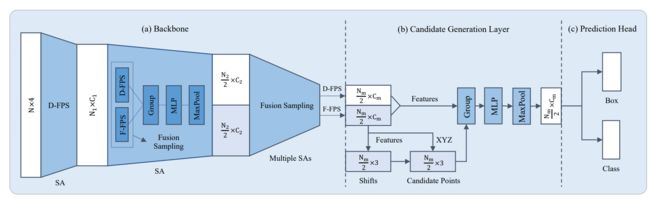
LiDAR-based Online 3D Video Object Detection with Graph-based Message Passing and Spatiotemporal Transformer Attention
作者团队: 中科院、百度
文章地址:https://arxiv.org/pdf/2004.01389.pdf
代码地址:https://github.com/yinjunbo/3DVID
本文提出的模型由空间特征编码模块和时空特征融合模块两部分组成。这里的空间特征编码模块——PMPNet(Pillar Message Passing Network)用于编码独立的每一帧的点云特征,该模块通过迭代消息传递,自适应地从相邻节点处为该pillar node收集节点信息,有效地扩大了该pillar node 的感受野。时空特征融合模块则是采用的时空注意力结合GRU的设计(AST-GRU)来整合时空信息,该模块通过一个attentive memory gate来加强传统的ConvGRU。其中AST-GRU模块又包含了一个空间注意力模块(STA)和TTA模块(Temporal Transformer Attention ),使得AST-GRU可以注意到前景物体和配准动态物体。
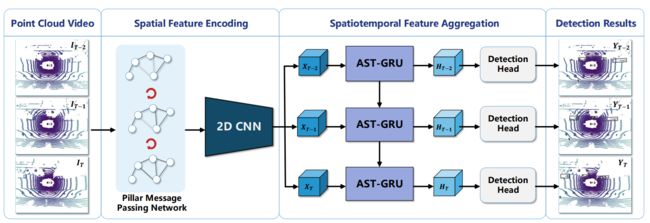
What You See is What You Get: Exploiting Visibility for 3D Object Detection(oral)
文章地址: https://arxiv.org/pdf/1912.04986.pdf
本文主要上面所述的这样一个观察,认为free -space 和unknown的信息是可以当做信息加入到深度学习网络中去的,因为目前的深度学习网络在BEV条件下并无法区分unkown和free-space信息,作者据此观察构建了visiblity map,并采用pointpillars 为baseline,采用了多种融合策略及数据增广方式,最终实验表面在Nuscenes上的效果提升不少。证实了这种观察的有效性。
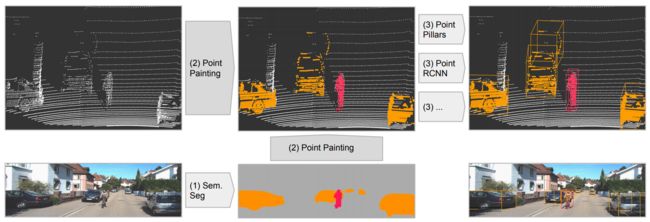
PointPainting: Sequential Fusion for 3D Object Detection
作者团队: nuTonomy
文章地址 https://arxiv.org/pdf/1911.10150.pdf
本文研究了一种新的image和lidar的fusion方式,在18年SOTA的baseline上都显示出精度的提升,同时对小物体优于大物体;本文的fusion方式是采用二维语义分割信息通过lidar信息和image信息的变换矩阵融合到点上,再采用baseline物体检测;可以理解为对于语义分割出的物体多了一些信息作为引导,得到更好的检测精度。
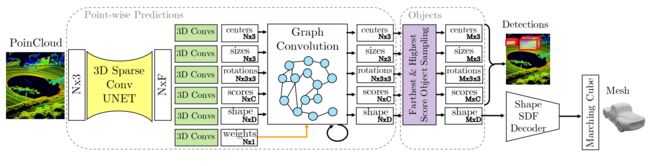
DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes
作者团队:马里兰大学、谷歌
文章地址: https://arxiv.org/pdf/2004.01170
来自马里兰大学和谷歌的合作工作,之前的研究工作都是要么对自动驾驶场景的物体进行检测,要么是针对室内物体的检测任务,本文中提出的统一架构可以对室内和室外自动驾驶场景进行检测;该方法的核心新颖之处在于其快速的一阶段体系结构,该体系结构既可以检测3D对象又可以估计其形状。每个点都会进行一次3D Bbox估算,通过图卷积进行聚合,然后送入网络的一个分支,该分支预测每个检测到的物体的形状编码表示。形状信息编码的解码是采用3D目标检测pipeline在综合数据集上进行监督学习的,所以作者表示他们的模型能够提取形状而无需访问目标数据集中的ground truth的形状信息。在实验过程中,作者提出的方法在ScanNet场景中的物体检测方面达到了约5%的最新结果,在Waymo Open Dataset中获得了3.4%的最高结果。
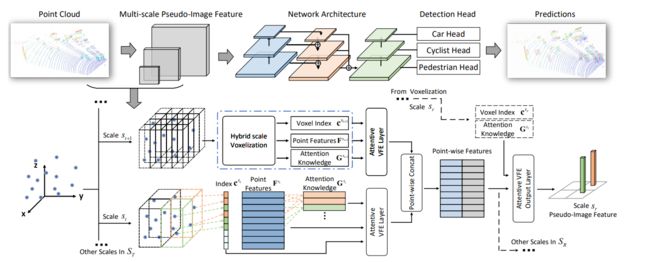
HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection
作者团队: DEEPROUTE.AI
文章地址: https://arxiv.org/pdf/2003.00186
本文作者来着DEEPROUTE.AI公司,本文主要针对的问题是voxel划分的精度和运行时间的权衡关系,作者指出如果划分的voxel单位数量过多,会得到更加丰富和原始的细节特征,但是运行时间和内存消耗都很大;但是如果划分出的体素数量过少的话,则会丢失很多细节特征。本文提出的HVNet,在point-wise level融合多尺度voxel特征,并投影到pseudo-image feature maps中来解决上诉的问题。进一步采用了注意力VFE结构来代替Voxle中的特征提取。实验表明可以达到31HZ,其中在小物体的精度上表现亮眼。
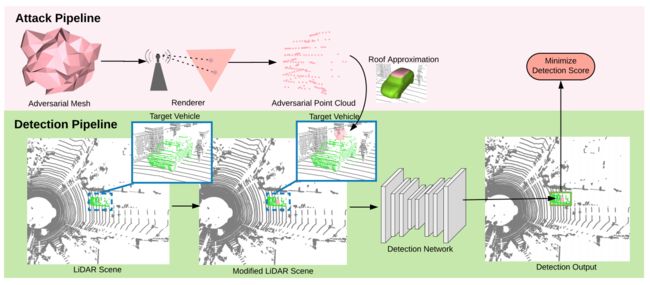
Physically Realizable Adversarial Examples for LiDAR Object Detection
作者团队: uber、多伦多大学和普林斯顿大学
文章链接: http://openaccess.thecvf.com/content_CVPR_2020/papers/Tu_Physically_Realizable_Adversarial_Examples_for_LiDAR_Object_Detection_CVPR_2020_paper.pdf
本文出发点是为了生成adversarial数据。现代自动驾驶系统严重依赖深度学习模型来处理点云感知数据。深层模型也被证明容易受到伪造数据的干扰。尽管这给自动驾驶行业带来了安全隐患,但在3D感知方面却鲜有探索,因为大多数对抗性攻击只应用于2D平面图像。本文针对这一问题,作者提出了一种生成通用三维对抗性物体生成器来欺骗激光雷达探测器。特别地,作者演示了在任何目标车辆的顶上放置一个生成的伪物体来完全隐藏车辆,不被激光雷达探测器发现的成功率为80%。作者还进行了一个试点研究对抗性防御使用数据增强。从有限的训练数据来看,这是向在看不见的情况下更安全的自动驾驶又迈进了一步。
PnPNet: End-to-End Perception and Prediction with Tracking in the Loop
作者团队:uber、多伦多大学
文章链接:http://openaccess.thecvf.com/content_CVPR_2020/papers/Liang_PnPNet_End-to-End_Perception_and_Prediction_With_Tracking_in_the_Loop_CVPR_2020_paper.pdf
这一篇文章不仅仅做目标检测,而是将自动驾驶场景中的分割和tracking任务结合。
作者考虑自动驾驶车辆在联合感知和运动预测两方面问题。作者提出了PnPNet,以连续的传感器数据作为输入,并在每个时间步长输出目标轨迹及其未来轨迹。该系统的关键部分是一个新颖的跟踪模块,该模块通过检测在线生成目标轨迹,并利用轨迹水平特征进行运动预测。具体地说,通过解决数据关联问题和轨迹估计问题,目标轨迹在每个时间步长进行更新。重要的是,整个模型是端到端可训练的,并且受益于所有任务的联合优化。作者在两个大规模的驱动数据集上验证了PnPNet,并显示出与目前最先进的闭塞恢复和更准确的未来预测相比,PnPNet有显著的改进。
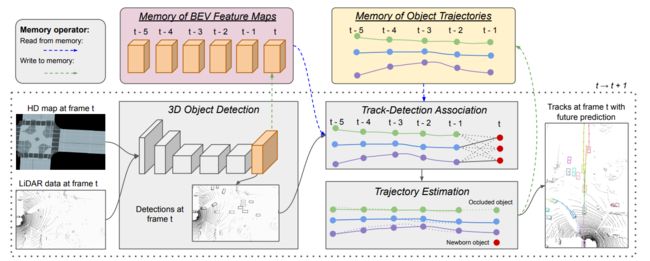
Associate-3Ddet: Perceptual-to-Conceptual Association for 3D Point Cloud Object Detection
作者团队:复旦大学、百度和中科院
文章链接: http://openaccess.thecvf.com/content_CVPR_2020/papers/Du_Associate-3Ddet_Perceptual-to-Conceptual_Association_for_3D_Point_Cloud_Object_Detection_CVPR_2020_paper.pdf
作者针对的问题是:由于严重的空间遮挡和点密度随传感器距离的内在变化,在点云数据中同一物体的外观会有很大的变化。因此作者创新性地提出了一种类似domain-adaptation的方法来增强特征表示的鲁棒性。作者的工作将来自真实场景的感知域的特征和从包含丰富细节信息的非遮挡点云的增强场景中提取特征的之间架起了桥梁。相当于在模拟脑的进化。
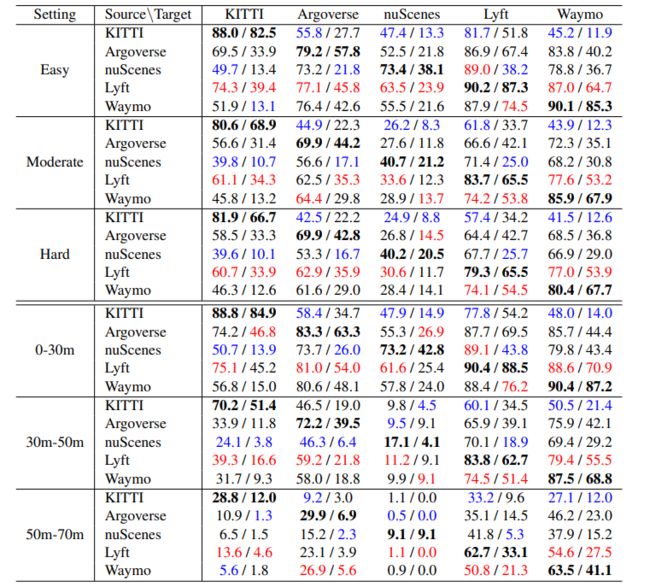
Train in Germany, Test in The USA: Making 3D Object Detectors Generalize
作者团队:康奈尔、scale AI、哥伦比亚大学
文章链接: http://openaccess.thecvf.com/content_CVPR_2020/papers/Wang_Train_in_Germany_Test_in_the_USA_Making_3D_Object_CVPR_2020_paper.pdf
代码链接:https://github.com/cxy1997/3D_adapt_auto_driving
作者指出深度学习尽管很好,但是在对数据集方法中的特性会过度适应,而目前的数据集大都在同一个地方采集,所以在实际中可能对不同国家或者区域的路面环境并不适应。这似乎是一个非常具有挑战性的任务,导致在精度水平急剧下降。作者提供了大量的实验来调查,并得出了一个惊人的结论:需要克服的主要障碍是不同地理区域的汽车大小的差异。一个基于平均汽车尺寸的简单修正,就能对适应差距进行强有力的修正。我们提出的方法是简单的,易于融入到大多数三维目标检测框架。它为适应不同国家的3D对象检测提供了第一个基线,并给人们带来了希望,即潜在的问题可能比人们希望相信的更容易解决。
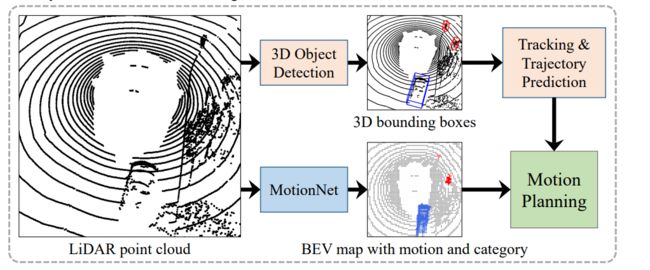
MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird’s Eye View Maps
作者团队:罗格斯大学
文章链接:http://openaccess.thecvf.com/content_CVPR_2020/papers/Wu_MotionNet_Joint_Perception_and_Motion_Prediction_for_Autonomous_Driving_Based_CVPR_2020_paper.pdf
代码地址: https://github.com/pxiangwu/MotionNet
作者提出了一个有效的深度学习模型,称为MotionNet,从三维点云中联合执行感知和运动预测。MotionNet以一系列激光雷达扫描作为输入和输出鸟瞰图(BEV),它编码每个网格单元中的目标类别和运动信息。MotionNet的主干是一种新颖的时空金字塔网络,它分层抽取深层时空特征。为了加强预测在时空上的平滑性,MotionNet的训练进一步正则化了新的时空一致性损失。大量的实验表明,提出的方法总体上优于目前的状态,包括最新的场景流和3d-object-detection-based方法。
Learning to Evaluate Perception Models Using Planner-Centric Metrics
作者团队: 英伟达、多伦多大学
这一篇文章作者的工作在于对目前的metric的方式提出一些改进。目前的衡量标准在最坏的情况下,它们会对所有不正确的检测一视同仁,而不会对任务或场景进行条件设置;在最好的情况下,需要选择启发式来确保不同的错误以不同的方式计数。针对自动驾驶任务,作者提出了一种三维目标检测的原则度量。该指标背后的核心思想是隔离目标检测任务,并度量产生的检测对下游驱动任务的影响。
2.2 单目3D目标检测
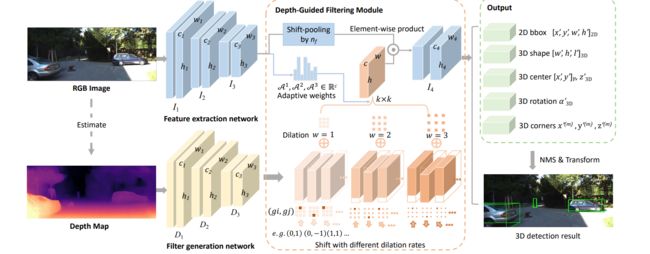
Learning Depth-Guided Convolutions for Monocular 3D Object Detection
作者团队:港大、北大深研院和商汤。
文章地址:http://openaccess.thecvf.com/content_CVPR_2020/papers/Ding_Learning_Depth-Guided_Convolutions_for_Monocular_3D_Object_Detection_CVPR_2020_paper.pdf
单目3D目标检测最大的挑战在于没法得到精确的深度信息,传统的二维卷积算法不适合这项任务,因为它不能捕获局部目标及其尺度信息,而这对三维目标检测至关重要。为了更好地表示三维结构,现有技术通常将二维图像估计的深度图转换为伪激光雷达表示,然后应用现有3D点云的物体检测算法。因此他们的结果在很大程度上取决于估计深度图的精度,从而导致性能不佳。在本文中,作者通过提出一种新的称为深度引导的局部卷积网络(LCN),更改了二维全卷积Dynamic-Depthwise-Dilated LCN ,其中的filter及其感受野可以从基于图像的深度图中自动学习,使不同图像的不同像素具有不同的filter。D4LCN克服了传统二维卷积的局限性,缩小了图像表示与三维点云表示的差距。D4LCN相对于最先进的KITTI的相对改进是9.1%,取得了monocular的第一名。
End-to-End Pseudo-LiDAR for Image-Based 3D Object Detection
作者团队:康奈尔大学、俄亥俄州立大学
文章地址: http://openaccess.thecvf.com/content_CVPR_2020/papers/Qian_End-to-End_Pseudo-LiDAR_for_Image-Based_3D_Object_Detection_CVPR_2020_paper.pdf
代码地址: https://github.com/mileyan/pseudo-LiDAR_e2e
作者设计了一个pseudo-LiDAR模块,PL将用于3D深度估计,将2D深度图输出转换为3D点云输入。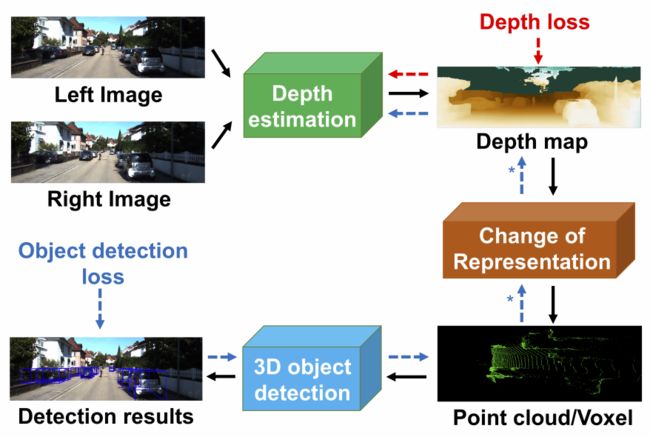
2.3 双目3D目标检测
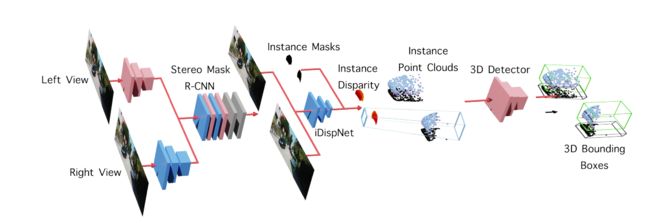
Disp R-CNN: Stereo 3D Object Detection via Shape Prior Guided Instance Disparity Estimation
作者团队: 浙大、商汤和南科大
文章链接: http://openaccess.thecvf.com/content_CVPR_2020/papers/Sun_Disp_R-CNN_Stereo_3D_Object_Detection_via_Shape_Prior_Guided_CVPR_2020_paper.pdf
代码地址: https://github.com/zju3dv/disprcnn
最近很多做双目3D目标检测的都是通过视差估计恢复点云,然后应用3D检测器来解决这个问题。对整个图像计算视差图,这是昂贵的,并且也是没有利用特定类别的先验。因此作者设计了一个实例视差估计网络(iDispNet),它仅对感兴趣的物体上的像素预测视差,并事先学习一个特定类别的形状,以便更准确地估计视差。同时针对训练中视差标注不足的问题,提出利用统计形状模型生成密集视差伪地真,而不需要激光雷达点云,使系统具有更广泛的适用性。在KITTI数据集上进行的实验表明,即使在训练时不能使用LiDAR的地面数据,Disp R-CNN也能取得具有竞争力的性能,在平均精度方面比以前的最先进的方法高出20%。
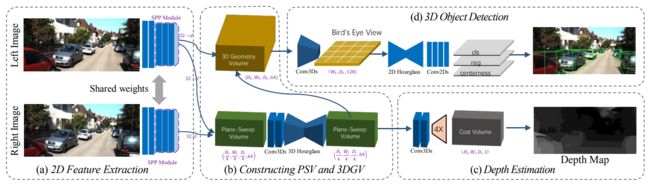
DSGN: Deep Stereo Geometry Network for 3D Object Detection
作者团队:港中文、samrtMore
文章地址:http://openaccess.thecvf.com/content_CVPR_2020/papers/Chen_DSGN_Deep_Stereo_Geometry_Network_for_3D_Object_Detection_CVPR_2020_paper.pdf
代码地址:https://github.com/chenyilun95/DSGN
作者指出大多数最先进的3D物体探测器严重依赖于激光雷达传感器,因为在基于图像和基于激光的方法之间有很大的性能差距。作者提出DSGN,通过在differentiable-voxels表示,有效地减少了和当前lidar输入的差距。通过这种表征,我们可以同时学习深度信息和语义信息。作者首次提供了一个简单有效的单阶段立体检测管道,以端到端学习的方式共同估计深度和检测三维物体。作者的方法优于以前的基于立体声的3D检测器(AP大约高出10个),甚至在KITTI 3D对象检测排行榜上与几种基于激光的方法取得了相当的性能。
总结
以上就是笔者近段时间看到的一些做3D目标检测的文章,欢迎补充~
参考了 http://openaccess.thecvf.com/CVPR2020.py