Spark Streaming整合kafka实战
kafka作为一个实时的分布式消息队列,实时的生产和消费消息,这里我们可以利用SparkStreaming实时计算框架实时地读取kafka中的数据然后进行计算。在spark1.3版本后,kafkaUtils里面提供了两个创建dstream的方法,一种为KafkaUtils.createDstream,另一种为KafkaUtils.createDirectStream。
1.KafkaUtils.createDstream方式
构造函数为KafkaUtils.createDstream(ssc,[zk], [consumer group id], [per-topic,partitions] ) 使用了receivers来接收数据,利用的是Kafka高层次的消费者api,对于所有的receivers接收到的数据将会保存在Spark executors中,然后通过Spark Streaming启动job来处理这些数据,默认会丢失,可启用WAL日志,它同步将接受到数据保存到分布式文件系统上比如HDFS。 所以数据在出错的情况下可以恢复出来 。
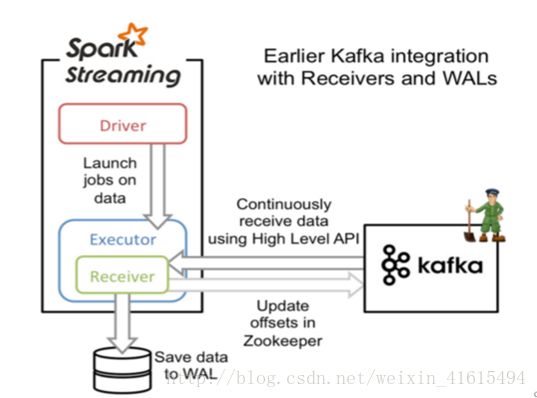
A、创建一个receiver来对kafka进行定时拉取数据,ssc的rdd分区和kafka的topic分区不是一个概念,故如果增加特定主消费的线程数仅仅是增加一个receiver中消费topic的线程数,并不增加spark的并行处理数据数量。
B、对于不同的group和topic可以使用多个receivers创建不同的DStream
C、如果启用了WAL(spark.streaming.receiver.writeAheadLog.enable=true)
同时需要设置存储级别(默认StorageLevel.MEMORY_AND_DISK_SER_2),
即KafkaUtils.createStream(….,StorageLevel.MEMORY_AND_DISK_SER)
1.1KafkaUtils.createDstream实战
(1)添加kafka的pom依赖
|
(2)启动zookeeper集群
zkServer.sh start
(3)启动kafka集群
kafka-server-start.sh /export/servers/kafka/config/server.properties
(4)创建topic
kafka-topics.sh --create --zookeeper node-1:2181 --replication-factor 1 --partitions 3 --topic kafka_spark
(5)向topic中生产数据
通过shell命令向topic发送消息
kafka-console-producer.sh --broker-list node-1:9092--topic kafka_spark
(6)编写SparkStreaming应用程序
KafkaUtils.createDstream方式(基于kafka高级Api-----偏移量由zk保存)
package cn.testdemo.dstream.kafka
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import scala.collection.immutable
//todo:利用sparkStreaming对接kafka实现单词计数----采用receiver(高级API)
object SparkStreamingKafka_Receiver {
def main(args: Array[String]): Unit = {
//1、创建sparkConf
val sparkConf: SparkConf = new SparkConf()
.setAppName("SparkStreamingKafka_Receiver")
.setMaster("local[2]")
.set("spark.streaming.receiver.writeAheadLog.enable","true") //开启wal预写日志,保存数据源的可靠性
//2、创建sparkContext
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//3、创建StreamingContext
val ssc = new StreamingContext(sc,Seconds(5))
//设置checkpoint
ssc.checkpoint("./Kafka_Receiver")
//4、定义zk地址
val zkQuorum="node-1:2181,node-2:2181,node-3:2181"
//5、定义消费者组
val groupId="spark_receiver"
//6、定义topic相关信息 Map[String, Int]
// 这里的value并不是topic分区数,它表示的topic中每一个分区被N个线程消费
val topics=Map("kafka_spark" -> 2)
//7、通过KafkaUtils.createStream对接kafka
//这个时候相当于同时开启3个receiver接受数据
val receiverDstream: immutable.IndexedSeq[ReceiverInputDStream[(String, String)]] = (1 to 3).map(x => {
val stream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)
stream
}
)
//使用ssc.union方法合并所有的receiver中的数据
val unionDStream: DStream[(String, String)] = ssc.union(receiverDstream)
//8、获取topic中的数据
val topicData: DStream[String] = unionDStream.map(_._2)
//9、切分每一行,每个单词计为1
val wordAndOne: DStream[(String, Int)] = topicData.flatMap(_.split(" ")).map((_,1))
//10、相同单词出现的次数累加
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_)
//11、打印输出
result.print()
//开启计算
ssc.start()
ssc.awaitTermination()
}
}
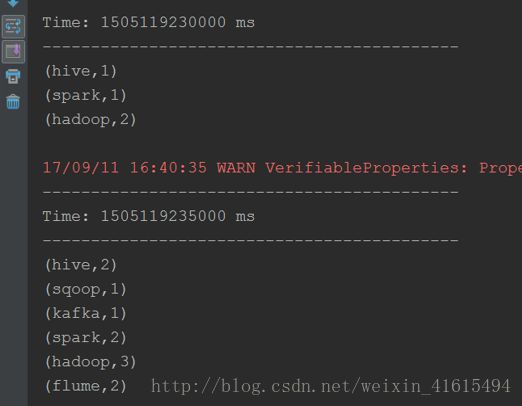
(7)运行代码,查看控制台结果数据
总结:
通过这种方式实现,刚开始的时候系统正常运行,没有发现问题,但是如果系统异常重新启动sparkstreaming程序后,发现程序会重复处理已经处理过的数据,这种基于receiver的方式,是使用Kafka的高阶API来在ZooKeeper中保存消费过的offset的。这是消费Kafka数据的传统方式。这种方式配合着WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和ZooKeeper之间可能是不同步的。官方现在也已经不推荐这种整合方式,官网相关地址下面我们使用官网推荐的第二种方式kafkaUtils的createDirectStream()方式。
2.KafkaUtils.createDirectStream方式
不同于Receiver接收数据,这种方式定期地从kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围在每个batch里面处理数据,Spark通过调用kafka简单的消费者Api读取一定范围的数据。
相比基于Receiver方式有几个优点:
A、简化并行
不需要创建多个kafka输入流,然后union它们,sparkStreaming将会创建和kafka分区一种的rdd的分区数,而且会从kafka中并行读取数据,spark中RDD的分区数和kafka中的分区数据是一一对应的关系。
B、高效
第一种实现数据的零丢失是将数据预先保存在WAL中,会复制一遍数据,会导致数据被拷贝两次,第一次是被kafka复制,另一次是写到WAL中。而没有receiver的这种方式消除了这个问题。
C、恰好一次语义(Exactly-once-semantics)
Receiver读取kafka数据是通过kafka高层次api把偏移量写入zookeeper中,虽然这种方法可以通过数据保存在WAL中保证数据不丢失,但是可能会因为sparkStreaming和ZK中保存的偏移量不一致而导致数据被消费了多次。EOS通过实现kafka低层次api,偏移量仅仅被ssc保存在checkpoint中,消除了zk和ssc偏移量不一致的问题。缺点是无法使用基于zookeeper的kafka监控工具
2.1KafkaUtils.createDirectStream实战
(1)前面的步骤跟KafkaUtils.createDstream方式一样,接下来开始执行代码。
KafkaUtils.createDirectStream方式(基于kafka低级Api-----偏移量由客户端程序保存)
package cn.itcast.dstream.kafka
import kafka.serializer.StringDecoder
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
//todo:利用sparkStreaming对接kafka实现单词计数----采用Direct(低级API)
object SparkStreamingKafka_Direct {
def main(args: Array[String]): Unit = {
//1、创建sparkConf
val sparkConf: SparkConf = new SparkConf()
.setAppName("SparkStreamingKafka_Direct")
.setMaster("local[2]")
//2、创建sparkContext
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
//3、创建StreamingContext
val ssc = new StreamingContext(sc,Seconds(5))
//4、配置kafka相关参数
val kafkaParams=Map("metadata.broker.list"->"node-1:9092,node-2:9092,node-3:9092","group.id"->"Kafka_Direct")
//5、定义topic
val topics=Set("kafka_spark")
//6、通过 KafkaUtils.createDirectStream接受kafka数据,这里采用是kafka低级api偏移量不受zk管理
val dstream: InputDStream[(String, String)] =
KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics)
//7、获取kafka中topic中的数据val topicData: DStream[String] = dstream.map(_._2)
//8、切分每一行,每个单词计为1
val wordAndOne: DStream[(String, Int)] = topicData.flatMap(_.split(" ")).map((_,1))
//9、相同单词出现的次数累加
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_+_)
//10、打印输出
result.print()
//开启计算
ssc.start()
ssc.awaitTermination()
}
}
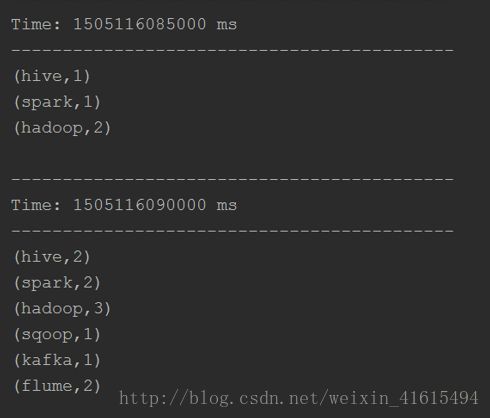
查看控制台的输出: