人体行为识别数据库
视频行为数据集
传统的通用的数据集:
1、KTH数据集:2004年发布,包含 6 类人体行为:行走、慢跑、奔跑、拳击、挥手和鼓掌,每类行为由 25 个人在四种不同的场景(室外、伴有尺度变化的室外、伴有衣着变化的 室外、室内)执行多次,相机固定。该数据库总共有 2391个视频样本。视频帧率为 25 fps,分 辨率为 160×120,平均长度为 4 秒。

2、The Weizmann Dataset:2005年发布,数据库包含了 10个动作(bend, jack, jump, pjump, run,side, skip, walk, wave1,wave2),每个动作有 9 个不同的样本。视频的视角是固定的,背景相对简单,每一帧中只有 1 个人做动作。数据库中标定数据除了类别标记外还包括:前景的行为人剪影和用于背景抽取的背景序列。

真实场景数据集
Hollywood系列
3、Hollywood(HOHA)数据集来自32部电影,从中抽取由不同的演员在不同的环境下执行的相同动作,该数据集包括8中行为类别,接电话、下车、握手、拥抱、亲吻、坐下、端坐、起立,并具有一个或多个标签.该数据集被划分成两部分:从12部电影获得的2个训练集和从其余的20部电影获得的测试集.其中, 2个训练集包括一个自动训练集和一个干净训练集.自动训练集使用自动脚本进行行为标注, 包含233个视频样本, 并具有超过60 %的正确标签; 而干净训练集则包含219个视频样本, 具有手动验证标签.测试集包含211个视频样本, 均具有手动验证标签。
4、Hollywood2数据集是Hollywood的扩展,Hollywood 2[29]数据集是Hollywood[27]的扩展, 来自69部电影, 包含12种行为类别和10类场景, 共有3 669个视频.该数据集包含两个子集:行为数据集(2 517个视频, 现实际有2 442个视频)和场景数据集(1 152个视频).行为数据集(Actions)在Hollywood[27]的基础上增加了4种行为类别:开车(DriveCar)、吃饭(Eat)、打架、跑。

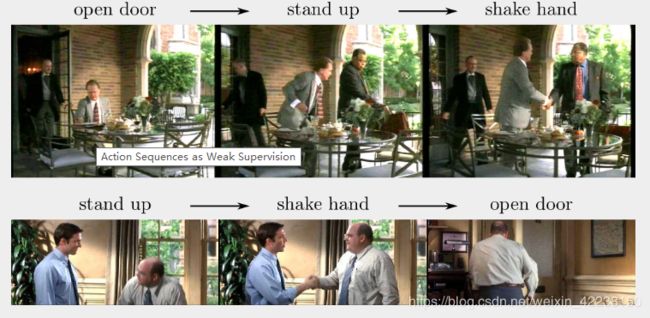
5、Hollywood extended数据集是前面数据集的扩充,有937个视频,16个行为类,来自69个电影,每个视频都带有一个有序的动作序列,例如从走动到坐着然后到应答电话,在时间上定位每个动作,并给其表签,视频注释和动作标签出现的顺序一致。
UCF系列数据库
美国University of central Florida(UCF)自2007年以来发布的一系列数据库:UCF sports action dataset(2008),UCF Youtube(2008),UCF50,UCF101等,引起了广泛关注。
这些数据库样本来自从 BBC/ESPN的广播电视频道收集的各类运动样本、以及从互联网尤其是视频网站YouTube上下载而来的样本。
6、ucf sports:包含10类人体行为:跳水、打高尔夫球,踢、举重、骑马、奔跑、滑板、鞍马、高低杠、行走。该数据库来源于广播电视频道:如bbc和espn,该数据库共包含150个分辨率为720*480的视频序列,帧率10fps,没个视频平均6.39s,数据库包含了大量行为视频、场景和视角的变化。

7、ucf youtube(ucf 11):包含11个行为类:投篮、骑自行车、跳水、打高尔夫球、骑马、足球杂耍、荡秋千、打网球、跳床、打排球、遛狗。由于相机运动,物体外观和姿态,物体比例,视点,杂乱的背景,照明条件等的巨大差异,此数据集非常具有挑战性。对于每个类别,视频都分为25组,其中包含4个以上的动作剪辑。 同一组中的视频片段具有一些共同的特征,例如相同的演员,相似的背景,相似的视点等等。

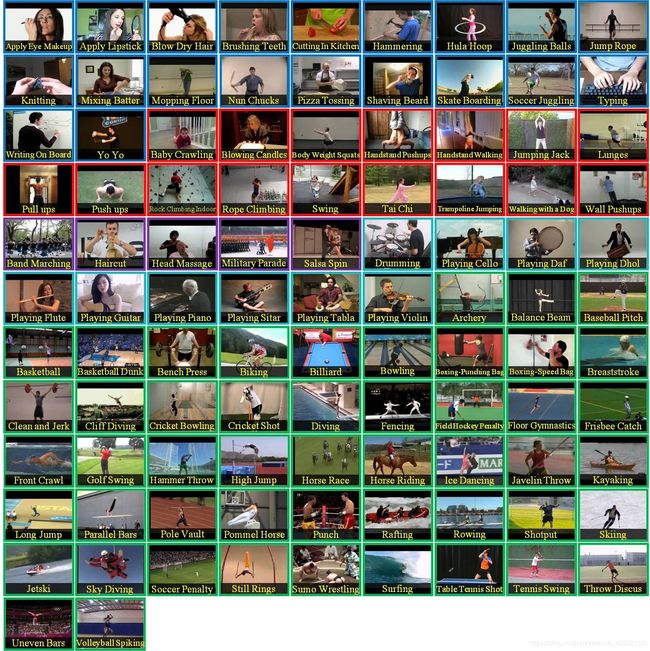
8、ucf 101:该数据集时ucf50数据集的扩充,包含101个行为,13320个时频,101个动作类别的视频分为25个组,每个组可以包含4-7个动作的视频动作类别可以分为五种类型:1)人与物体的互动2)仅身体动作3)人与人的互动4)演奏乐器5)运动。 来自同一组的视频可能具有一些共同的特征,例如相似的背景,相似的观点等。在动作方面具有最大的多样性,并且在摄像机运动,物体外观和姿势,物体比例,视点,杂乱的背景,照明条件等方面存在很大的差异。是目前为止类别较多,挑战度较大的数据集。
9、Olympic Sports数据集【Juan Carlos Niebles, Chih-Wei Chen and Li Fei-Fei. Modeling Temporal Structure of Decomposable Motion Segments for Activity Classification. 11th European Conference on Computer Vision (ECCV), 2010.】来自于YouTube, 包含运动员练习的783个视频.该数据集包含16种运动类别:跳高(high-jump)、跳远(long-jump)、三级跳远(triple-jump)、撑杆跳(pole-vault)、单手上篮(basketball lay-up)、打保龄球(bowling)、网球发球(tennis-serve)、10米跳台(platform)、铁饼(discus)、链球(hammer)、标枪(javelin)、铅球(shot put)、3米跳板(springboard)、举重抓举(snatch)、举重挺举(clean-jerk)和跳马(vault),.该数据集在亚马逊土耳其机器人的帮助下注释其类标签, 包含复杂运动、严重遮挡、相机运动等因素影响。

10、HMDB51数据集主要来源于电影, 只有一小部分来自公共数据库, 如Prelinger存档、YouTube和Google视频.该数据集包含6 849个视频, 分为51种行为类别, 每种行为包含至少101个视频.该数据集的行为类别可以归纳为5种类型: 1)普通面部动作:微笑、大笑、咀嚼、说话; 2)操纵对象的面部动作:抽烟、吃、喝; 3)普通身体运动:侧手翻、拍手、攀登、爬楼梯、俯冲、落地、反手空翻、倒立、跳、引体向上、俯卧撑、跑、坐下、仰卧起坐、翻筋斗、站起来、转身、走、挥手; 4)与对象交互的身体运动:梳头、抓球、拔剑、运球、打高尔夫、打东西、踢足球、捡东西、倒东西、推东西、骑自行车、骑马、投篮、射箭、射枪、打球棒、练剑、扔东西; 5)与人交互的身体运动:击剑、拥抱、踢人、亲吻、拳击、握手、斗剑,因为该数据集来源不同, 并伴有遮挡、相机移动、复杂背景、光照条件变化等诸多因素影响, 导致其识别准确率较低, 极具有挑战性。

11、Sports-1M[35]数据集是Google公布的一个大型视频数据集, 来自于公开的YouTube视频.该数据集包含487种体育运动项目, 共计1 133 158个视频.该数据集中每种行为类别包含1 000 ∼∼ 3 000个视频, 其中有大约5 %的视频带有多个标注.该数据集包含的体育运动项目可以分为6大类:水上运动、团队运动、冬季运动、球类运动、对抗运动、与动物运动.而且各类别在叶级层次差异很小, 如包含6个不同类型的保龄球和23个不同类型台球等.自数据集创建以来, 约有7 %的视频已经被用户删除.由于该数据集来自公开视频, 所以相机运动不受限制, 导致光流参数在视频间变化较大, 给视频的识别带来一定的困难。
12、Kinetics700
Kinetics-700是一个大规模,高质量的YouTube视频网址数据集,其中包含各种人的动作。 还有Kinetics-600、Kinetics-400。
该数据集由大约650000个视频组成,涵盖700个人类动作,每个动作至少有600个视频。 每个视频持续大约10秒钟,并标有一个类。 这些动作涵盖了广泛的范围,包括人 - 物体交互,如演奏乐器,以及人与人之间的互动,如握手和拥抱。
13、Google的AVA数据集
Google发布AVA:一个用于理解人类动作的精细标记视频数据集,是一个全新的数据集,为扩展视频序列中的每个人提供多个动作标签。AVA 由 YouTube 中公开视频的网址组成,注解了一组 80 种时空局部化的原子动作(如“走”、“踢(物体)”、“握手”等),产生了 5.76 万个视频片段、9.6 万个标记动作执行人以及总共 21 万个动作标签。见,每个示例只显示一个边界框)
与其他动作数据集相比,AVA 具有以下重要特征:
(1)以人为中心的注解。每个动作标签与人相关,而不是与视频或剪辑相关。因此,我们可以将不同标签分配到同一场景中执行不同动作的多个人(这种情况很常见)。
(2)原子视觉动作。我们将动作标签限于很小的时间尺度(3 秒),在此范围内,动作的性质是身体活动,具有清晰的视觉特征。
(3)现实视频材料。我们使用电影作为 AVA 的来源,从很多不同的流派和原产国取材。因此,数据中包含广泛的人类行为。

14、ActivityNet数据集旨在涵盖人们日常生活中感兴趣的各种复杂的人类活动,当前版本中包含203个行为类,每个类平均137个未修正的视频,每个视频平均有1.41个活动实例,共847小时。

15、NTU RGB+D 120:有120个类,114480个视频,每个实例都有RGB、深度、红外、3D骨骼4个版本的视频,通过三台Kinect V2 相机拍摄,RGB视频的分辨率为1920x1080,深度图和红外视频的分辨率均为512x424,并且3D骨骼数据包含每帧25个人体关节的3D坐标。
跨光谱数据集
16、InfAR红外数据集包括600各由红外热成像相机采集的视频序列,包含12个类,每个行为50个视频,每个视频平均4s,帧率25fps,分辨率293*256.各个视频由一个或多个人执行的单类或者多类行为,有一部分还包含多人交互。
跨视角数据库
17、IXMAS IXMAS 数据库[114]包含 1650 个视频样本,共有 11 类行为,分别是:看表、叉 手、起来、踢、捡起、推、挠头、坐下、转向、行走和挥手。每类视频均包含 5 个 相机视角,其中 4 个侧视视角,1 个俯视视角。图 1.6 展示了 IXMAS 数据库中叉手 和挥手两个动作,可以看出,不同视角下,人体行为的外观差异很大。

18、NUMA 数据库[115]包含 1509 个视频样本,共有 10 类行为,分别是:单手捡起、 双手捡起、扔垃圾、四周走动、坐下、站起、穿衣服、脱衣服、扔和搬运。每类视 频分别由 3 个不同视角的 Kinect 相机在 5 种环境下采集,每类行为由 10 个人执行。 图 1.7 展示了 NUMA 数据库中搬运、单手拾起、坐下和扔四个动作。

19、WVU 数据库[116]包含 6240 个视频样本,共 12 类行为,分别是:站立、点头、 鼓掌、单手挥动、双手挥动、推、慢跑、跳跃、踢、拾起、扔和打保龄球。每类行为包含 65 个视频样本,8 个相机视角,和 IXMAS 和 NUMA 数据库相比, WVU 属于 规模较大、相机视角较多、难度较高的跨视角行为识别数据库。图 1.8 展示了 WVU 数据库中拾起和挥动双手两个动作。

20、MuHAVi 数据库[117]包含 8 个相机视角,共有 17 类行为,分别是:步行返回、跑 步停止、推、踢、突然跌倒、拉重物、拾起并扔掉物体、走路跌倒、往车内看、靠 膝盖爬行、挥动双臂、涂鸦、翻越栅栏、醉酒走路、爬楼梯、砸物体、跳跃沟壑。 每类行为同时由 7 个人执行,8 个相机分别部署在矩阵平面的 4 个侧边和 4 个角。图 1.9 展示了 MuHAVi 数据库中涂鸦和挥动手臂两个动作。
