第三周:我的Python学习笔记
文章目录
- (零)实践题目
- (一)Excel的读写
- (二)字典数据学习
- 字典 很多语言都有;作用:根据某一个唯一的特定的key找东西
- 1.创建字典
- 2.字典的增删改查
- 3.遍历字典 循环的不是值 而是key
- 4.长度
- 5.相等:比较每个key是否相同;对应的值是否相等
- 6.in操作:查找是否有某个key
- 7.字典的方法
- 8.借助字典实现 switch 的功能
- (三)List数据的学习
- 1、List的一些基础操作
- 1.创建列表
- 2.访问列表元素
- 3.通用操作
- 4.比较运算
- 2、List一些专有的操作
- 1.list一些简单操作
- 2.推导式 独有
(零)实践题目
具体要求,用list保存多个字典,实现一个类似电话簿的应用
字典格式{“Name”:XXX “Sex”:XXX “PhoneNumber”:XXX}
- 要求从中查找姓名为XXX的电话
- 修改姓名为XXX的性别
- 查找电话为XXX的名字
- 新添加一条记录【该记录可写死,不用键盘输入】
点击查看实现题目完整代码
(一)Excel的读写
师兄推荐使用xlrd模块和xlwt模块,以下是学弟推荐的两个资源:
python里面的xlrd模块详解(一)
python读写Excel文件–使用xlrd模块读取,xlwt模块写入
我这周学习的是openpyxl模块,学习链接:用Python处理Excel数据,中文全基础系列教程
听了第一节和第三节的前面部分,以下是学习的代码:
import openpyxl # 操作Excel文件的第三方模块
from openpyxl.utils import get_column_letter
#工作簿workbook、表单worksheet、列column、行row、单元格cell
############读
wb = openpyxl.load_workbook('example.xlsx') # 读已经有了的Excel文件 这个文件路径在这个Project里面 放到一个工作簿对象里面
print(wb.sheetnames) # 把工作簿中的每一个表单打出来
for sheet in wb: # 把工作簿中所有表单的名字通过循环打印出来
print(sheet.title)
mySheet = wb.create_sheet('mySheet') # 在工作簿中添加一个新的表单
print(wb.sheetnames) # 把工作簿中的每一个表单打出来
ws = wb.active
print(ws)
print(ws['A1'])
print(ws['A1'].value)
# 获取3行2列的数据
print(ws['B3'].value) #直接打出来
c = ws['B3'] # 通过坐标引用单元格
print('方法1:Row {} Column {} is {}'.format(c.row, c.column, c.value)) #printf("方法1:Row %d Column %d is %c", c.row, c.column, c.value);
print('方法2:Cell {} is {}'.format(c.coordinate, c.value))
print('方法3:', ws.cell(row=3, column=2)) #行列都是从1开始
print('方法3.1', ws.cell(row=3, column=2).value)
#目的 求第二列基数的内容
for i in range(1, 8, 2): #i=1-8 间隔为2
print(i, ws.cell(row=i, column=2).value)
###########写
#创建工作簿
wb = openpyxl.Workbook()
sheet = wb.active
print(sheet.title)
#创建表单
wb.create_sheet(title='ThirdSheet') #生成新的表单 默认在刚刚生成的表单后面
wb.create_sheet(index=0, title='ZeroSheet') #指定新生成表单的位置
print(wb.sheetnames)
#删除表单
del wb['ThirdSheet']
print(wb.sheetnames)
# 第一列按照1---20填写
sheet.append(range(1, 21)) #第一行
ws = wb.create_sheet('HomeWork')
for row in range(1, 21):
ws.cell(column=1, row=row, value=row)
wb.save('Wright.xlsx')
#在单元格里写内容 有些类似与往字典里面写东西;座标类似于键值
wb = openpyxl.Workbook()
sheet = wb.active
#一个一个写
sheet['A1'] = 'Esther' # 键值的赋值:d['height'] = 190 # 直接往里“扔”
print(sheet['A1'].value)
#利用循环写
ws1 = wb.create_sheet('range names')
for row in range(1, 40): #range产生自然数序列
ws1.append(range(17))
#利用列表写
ws2 = wb.create_sheet('List')
rows = [
['Number', 'Batch1', 'Batch2'],
[2, 40, 30],
[3, 12, 34],
[4, 23, 45],
[5, 23, 23],
[6, 23, 45],
]
for row in rows:
ws2.append(row)
#通过二重循环
ws3 = wb.create_sheet(title='Data')
for row in range(5, 30):
for col in range(15, 54):
ws3.cell(column=col, row=row, value=get_column_letter(col))
print(ws3['AA10'].value)
wb.save(filename='Practice.xlsx')
#注意
wb = openpyxl.load_workbook('example.xlsx') #打开一个已经存在的文件之后
wb.save('ChangedExample.xlsx') #不要直接写回原文件 要“另存为” 防止出错
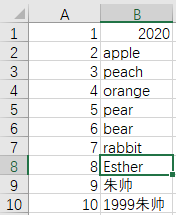
代码实现的条件是在程序所在文件夹中已存在一个example.xlsx的Excel文件,文件中的内容如下:
(二)字典数据学习
字典 很多语言都有;作用:根据某一个唯一的特定的key找东西
字典用于存储"键值对",用于快速获取、添加、删除、修改某个值;跟C++的map是一样的
“键”:必须是唯一的:电话号;用户名;身份证
“值”:用唯一的键来查找对应值的信息
所有语言中的字典,都是基于Hash、二叉树或其他类似结构的一类无序数据结构,目的就是为了增加数据访问的速度
没有人会对字典进行排序,没有意义
价值:为了增加查询速度
1.创建字典
#方法1:直接写
d={
"name":"张三",
"name":"李四", #错误示范 说明唯一性
"age":35,
"gender":"男"
}
print(d)
print(d['age'])
#方法2:构造器/构造函数
d2=dict([
['name', '张三'],
['age', 35],
['gender', '男']
])
print(d2)
print(d2['age'])
{'name': '李四', 'age': 35, 'gender': '男'}
35
{'name': '张三', 'age': 35, 'gender': '男'}
35
2.字典的增删改查
获取元素也用[];也可以用get(key)
#添加
d={
"name":"张三",
"age":35,
"gender":"男"
}
print(d)
d['height'] = 190 # 直接往里“扔”
print(d)
{'name': '张三', 'age': 35, 'gender': '男'}
{'name': '张三', 'age': 35, 'gender': '男', 'height': 190}
#删除 也可以用pop(key)
del d['gender']
print(d)
{'name': '张三', 'age': 35, 'height': 190}
#修改
d['age'] = 25
print(d)
d['age'] -= 10
print(d)
{'name': '张三', 'age': 25, 'height': 190}
{'name': '张三', 'age': 15, 'height': 190}
3.遍历字典 循环的不是值 而是key
l = [1, 2, 3]
for item in l:
print(item)
d={
"name":"张三",
"age":35,
"gender":"男"
}
for item in d: # 循环打出来的是key
print(item)
for key in d:
print(key+":"+str(d[key]))
1
2
3
name
age
gender
name:张三
age:35
gender:男
4.长度
d={
"name":"张三",
"age":35,
"gender":"男"
}
print(len(d))
3
5.相等:比较每个key是否相同;对应的值是否相等
顺序对字典的比较是没有意义的
d1 = {"a":15,"b":56}
d2 = {"b":56,"a":15}
print(d1==d2)
True
6.in操作:查找是否有某个key
d={
"name":"张三",
"age":35,
"gender":"男"
}
print("name" in d)
print("height" in d)
print("name" not in d)
True
False
False
7.字典的方法
| 方法 | 说明 |
|---|---|
| clear() | 清空字典 |
| keys() | 返回所有key |
| values() | 返回所有value |
| get(key) | 索引,类似于[] |
| pop(key) | 删除,类似于del |
#clear()
d={
"name":"张三",
"age":35,
"gender":"男"
}
print(d)
d.clear()
print(d)
{'name': '张三', 'age': 35, 'gender': '男'}
{}
#keys();values()
d={
"name":"张三",
"age":35,
"gender":"男"
}
print(d.keys())
print(d.values())
dict_keys(['name', 'age', 'gender'])
dict_values(['张三', 35, '男'])
#get() pop()
d={
"name":"张三",
"age":35,
"gender":"男"
}
print(d["name"]) #用[]查询
print(d.get("name")) #用get查询
d.pop("name")
print(d)
del d["age"]
print(d)
张三
张三
{'age': 35, 'gender': '男'}
{'gender': '男'}
8.借助字典实现 switch 的功能
def case1():
print("This is case1")
def case2():
print("This is case2")
def case3(somearg):
print("This is case3")
switch = {
1:case1,
2:case2,
3:case3
}
choice = 1
switch.get(choice)()
This is case1
(三)List数据的学习
1、List的一些基础操作
1.创建列表
两种方法:
#方法1:直接写
l1 = [1, 2, 3]
#l2 = l1 #类似指针
l2 = list(l1) #解决方法
l2[1] = 4
print("1:", l1)
print("1:", l2)
#方法2:构造器
l = list([1, 2, 3])
print("2:", l)
也可以通过其他序列构造列表
#字符串也是一种序列
s = 'asdfghjkl'
l = list(s)
print("3:", l)
l = list('2345678')
print("4:", l)
2.访问列表元素
和访问字符串一样
l = [1, 2, 3, 4, 5] #列表
print(l[0])
sh = '12345' # 字符串
print(sh[0])
不止访问一个 可以连着访问很多个
l = [0, 1, 2, 3, 4, 5]
print(l[3:6])
print(l[:6])
print(l[3:])
3.通用操作
max min函数 求最大最小
l = [3, 2, 45, 23] #列表
print(min(l))
sh = '12345' # 字符串
print(max(sh))
求和
l = [12, 234, 12]
print(sum(l))
sh = 'ascsa'
print(sum(sh))
4.比较运算
逻辑上和字符串一样,从第0个开始往后一个一个比较
l1=[12, 5, 9]
l2=[8, 37, 6]
print(l1 > l2) #比较的是第一个 第一个相同往后比较
print([1, 2, 3] > [])
2、List一些专有的操作
字符串没有的
1.list一些简单操作
| append(x) | 末尾添加 |
|---|---|
| insert(index, x) | 插入 |
| pop(i) | 删除第i个 |
| remove(x) | 删除某一元素 |
| count(x) | 计数 |
| index(x) | 查找 |
| reverse() | 反转 |
| sort() | 排序 |
l = [1, 2, 3]
l.append(5) # 末尾添加
print(l)
[1, 2, 3, 5]
l.insert(0, 8) # 插入
print(l)
[8, 1, 2, 3, 5]
#l.pop() # 删除元素
l.pop(0)
print(l)
[1, 2, 3, 5]
l.remove(7) # 删除元素 注意与pop()的区别
print(l)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in
----> 1 l.remove(7) # 删除元素 注意与pop()的区别
2 print(l)
ValueError: list.remove(x): x not in list
l = [12, 3, 3, 5, 34, 12, 12, 87]
print(l.count(12)) # 计数
3
print(l.index(3)) # 查找
# print(l.index(90))
1
l = [1, 2, 3, 4]
print(l)
print(l.reverse()) # 无法在终端输出 因为reverse是对list进行修改然后生成新list的函数 所以需要翻转再打出
l.reverse() # 翻转
print(l)
[1, 2, 3, 4]
None
[1, 2, 3, 4]
l = [12, 98, 2, 87, 1]
l.sort() # 排序
print(l)
[1, 2, 12, 87, 98]
2.推导式 独有
- 从一个序列生成另一个序列 例:从成绩列表 变成及格/不及格的列表~
- 跟循环很像
- [结果 for x in 序列 if 条件]
l = [1, 2, 3, 4]
l2 = [item+5 for item in l]
print(l)
print(l2)
[1, 2, 3, 4]
[6, 7, 8, 9]
"结果"可以是任何东西
l3 = [1 for item in l] # 灵活
print(l3)
[1, 1, 1, 1]
可以加入条件if
l = [1, 2, 3, 4, 5, 6, 7, 8, 9]
l2 = [item*2 for item in l if item%3 == 0] # 增加if条件进行筛选
print(l)
print(l2)
l = [100, 80, 90, 56, 87, 44]
l2 = [item for item in l if item >= 60] #对及格成绩进行筛选
print(l)
print(l2)
[100, 80, 90, 56, 87, 44]
[100, 80, 90, 87]
推导式非常适合用来"导出"某个数据,比如:从一组xpath中导出标题