Spark Streaming场景应用|Kafka数据读取方式
Spark Streaming 支持多种实时输入源数据的读取,其中包括Kafka、flume、socket流等等。除了Kafka以外的实时输入源,由于我们的业务场景没有涉及,在此将不会讨论。本篇文章主要着眼于我们目前的业务场景,只关注Spark Streaming读取Kafka数据的方式。 Spark Streaming 官方提供了两种方式读取Kafka数据:
一是Receiver-based Approach。该种读取模式官方最先支持,并在Spark 1.2提供了数据零丢失(zero-data loss)的支持;
一是Direct Approach (No Receivers)。该种读取方式在Spark 1.3引入。
此两种读取方式存在很大的不同,当然也各有优劣。接下来就让我们具体剖解这两种数据读取方式。
一、Receiver-based Approach
如前文所述,Spark官方最先提供了基于Receiver的Kafka数据消费模式。但会存在程序失败丢失数据的可能,后在Spark 1.2时引入一个配置参数spark.streaming.receiver.writeAheadLog.enable以规避此风险。以下是官方的原话:
under default configuration, this approach can lose data under failures (see receiver reliability. To ensure zero-data loss, you have to additionally enable Write Ahead Logs in Spark Streaming (introduced in Spark 1.2). This synchronously saves all the received Kafka data into write ahead logs on a distributed file system (e.g HDFS), so that all the data can be recovered on failure.
Receiver-based 读取方式
Receiver-based的Kafka读取方式是基于Kafka高阶(high-level) api来实现对Kafka数据的消费。在提交Spark Streaming任务后,Spark集群会划出指定的Receivers来专门、持续不断、异步读取Kafka的数据,读取时间间隔以及每次读取offsets范围可以由参数来配置。读取的数据保存在Receiver中,具体StorageLevel方式由用户指定,诸如MEMORY_ONLY等。当driver 触发batch任务的时候,Receivers中的数据会转移到剩余的Executors中去执行。在执行完之后,Receivers会相应更新ZooKeeper的offsets。如要确保at least once的读取方式,可以设置spark.streaming.receiver.writeAheadLog.enable为true。具体Receiver执行流程见下图:
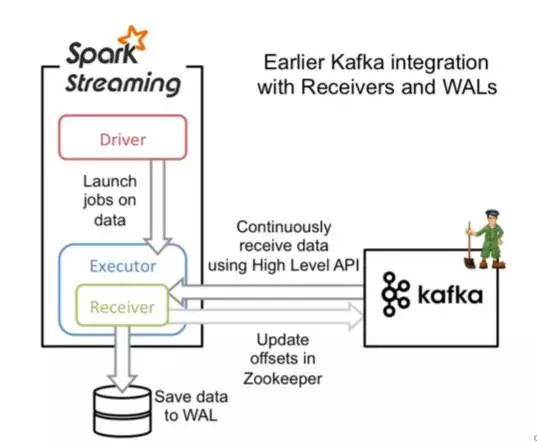
Receiver-based 读取实现
Kafka的high-level数据读取方式让用户可以专注于所读数据,而不用关注或维护consumer的offsets,这减少用户的工作量以及代码量而且相对比较简单。因此,在刚开始引入Spark Streaming计算引擎时,我们优先考虑采用此种方式来读取数据,具体的代码如下:
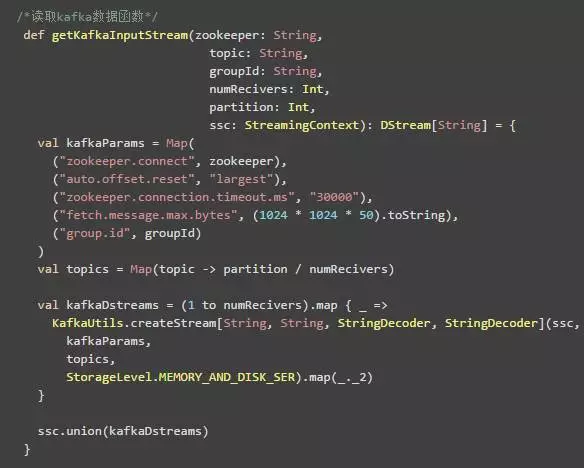
如上述代码,函数getKafkaInputStream提供了zookeeper, topic, groupId, numReceivers, partition以及ssc,其传入函数分别对应:
zookeeper: ZooKeeper连接信息
topic: Kafka中输入的topic信息
groupId: consumer信息
numReceivers: 打算开启的receiver个数, 并用来调整并发
partition: Kafka中对应topic的分区数
以上几个参数主要用来连接Kafka并读取Kafka数据。具体执行的步骤如下:
Kafka相关读取参数配置,其中 zookeeper.connect即传入进来的zookeeper参数;auto.offset.reset设置从topic的最新处开始读取数据;zookeeper.connection.timeout.ms指zookeepr连接超时时间,以防止网络不稳定的情况;fetch.message.max.bytes则是指单次读取数据的大小;group.id则是指定consumer。
指定topic的并发数,当指定receivers个数之后,但是由于receivers个数小于topic的partition个数,所以在每个receiver上面会起相应的线程来读取不同的partition。
读取Kafka数据,numReceivers的参数在此用于指定我们需要多少Executor来作为Receivers,开多个Receivers是为了提高应用吞吐量。
union用于将多个Receiver读取的数据关联起来。
Receiver-based 读取问题
采用Reveiver-based方式满足我们的一些场景需求,并基于此抽象出了一些micro-batch、内存计算模型等。在具体的应用场景中,我们也对此种的方式做了一些优化:
防数据丢失。做checkpoint操作以及配置spark.streaming.receiver.writeAheadLog.enable参数;
提高receiver数据吞吐量。采用MEMORY_AND_DISK_SER方式读取数据、提高单Receiver的内存或是调大并行度,将数据分散到多个Receiver中去。
以上处理方式在一定程度上满足了我们的应用场景,诸如micro-batch以及内存计算模型等。但是同时因为这两方面以及其他方面的一些因素,导致也会出现各种情况的问题:
配置spark.streaming.receiver.writeAheadLog.enable参数,每次处理之前需要将该batch内的日志备份到checkpoint目录中,这降低了数据处理效率,反过来又加重了Receiver端的压力;另外由于数据备份机制,会受到负载影响,负载一高就会出现延迟的风险,导致应用崩溃。
采用MEMORY_AND_DISK_SER降低对内存的要求。但是在一定程度上影响计算的速度
单Receiver内存。由于receiver也是属于Executor的一部分,那么为了提高吞吐量,提高Receiver的内存。但是在每次batch计算中,参与计算的batch并不会使用到这么多的内存,导致资源严重浪费。
提高并行度,采用多个Receiver来保存Kafka的数据。Receiver读取数据是异步的,并不参与计算。如果开较高的并行度来平衡吞吐量很不划算。
Receiver和计算的Executor的异步的,那么遇到网络等因素原因,导致计算出现延迟,计算队列一直在增加,而Receiver则在一直接收数据,这非常容易导致程序崩溃。
在程序失败恢复时,有可能出现数据部分落地,但是程序失败,未更新offsets的情况,这导致数据重复消费。
为了回辟以上问题,降低资源使用,我们后来采用Direct Approach来读取Kafka的数据,具体接下来细说。
二、Direct Approach (No Receivers)
区别于Receiver-based的数据消费方法,Spark 官方在Spark 1.3时引入了Direct方式的Kafka数据消费方式。相对于Receiver-based的方法,Direct方式具有以下方面的优势:
简化并行(Simplified Parallelism)。不现需要创建以及union多输入源,Kafka topic的partition与RDD的partition一一对应,官方描述如下:
No need to create multiple input Kafka streams and union them. With directStream, Spark Streaming will create as many RDD partitions as there are Kafka partitions to consume, which will all read data from Kafka in parallel. So there is a one-to-one mapping between Kafka and RDD partitions, which is easier to understand and tune.
高效(Efficiency)。Receiver-based保证数据零丢失(zero-data loss)需要配置spark.streaming.receiver.writeAheadLog.enable,此种方式需要保存两份数据,浪费存储空间也影响效率。而Direct方式则不存在这个问题。
Achieving zero-data loss in the first approach required the data to be stored in a Write Ahead Log, which further replicated the data. This is actually inefficient as the data effectively gets replicated twice - once by Kafka, and a second time by the Write Ahead Log. This second approach eliminates the problem as there is no receiver, and hence no need for Write Ahead Logs. As long as you have sufficient Kafka retention, messages can be recovered from Kafka.
强一致语义(Exactly-once semantics)。High-level数据由Spark Streaming消费,但是Offsets则是由Zookeeper保存。通过参数配置,可以实现at-least once消费,此种情况有重复消费数据的可能。
The first approach uses Kafka’s high level API to store consumed offsets in Zookeeper. This is traditionally the way to consume data from Kafka. While this approach (in combination with write ahead logs) can ensure zero data loss (i.e. at-least once semantics), there is a small chance some records may get consumed twice under some failures. This occurs because of inconsistencies between data reliably received by Spark Streaming and offsets tracked by Zookeeper. Hence, in this second approach, we use simple Kafka API that does not use Zookeeper. Offsets are tracked by Spark Streaming within its checkpoints. This eliminates inconsistencies between Spark Streaming and Zookeeper/Kafka, and so each record is received by Spark Streaming effectively exactly once despite failures. In order to achieve exactly-once semantics for output of your results, your output operation that saves the data to an external data store must be either idempotent, or an atomic transaction that saves results and offsets (see Semantics of output operations in the main programming guide for further information).
Direct 读取方式
Direct方式采用Kafka简单的consumer api方式来读取数据,无需经由ZooKeeper,此种方式不再需要专门Receiver来持续不断读取数据。当batch任务触发时,由Executor读取数据,并参与到其他Executor的数据计算过程中去。driver来决定读取多少offsets,并将offsets交由checkpoints来维护。将触发下次batch任务,再由Executor读取Kafka数据并计算。从此过程我们可以发现Direct方式无需Receiver读取数据,而是需要计算时再读取数据,所以Direct方式的数据消费对内存的要求不高,只需要考虑批量计算所需要的内存即可;另外batch任务堆积时,也不会影响数据堆积。其具体读取方式如下图:
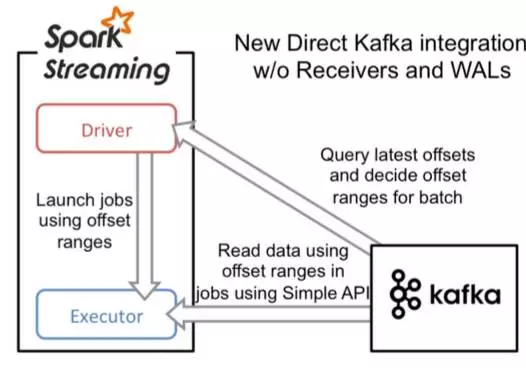
Direct 读取实现
Spark Streaming提供了一些重载读取Kafka数据的方法,本文中关注两个基于Scala的方法,这在我们的应用场景中会用到,具体的方法代码如下:
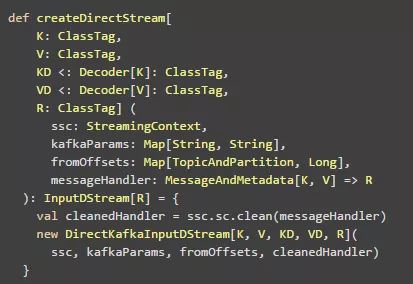
方法createDirectStream中,ssc是StreamingContext;kafkaParams的具体配置见Receiver-based之中的配置,与之一样;这里面需要指出的是fromOffsets ,其用来指定从什么offset处开始读取数据。
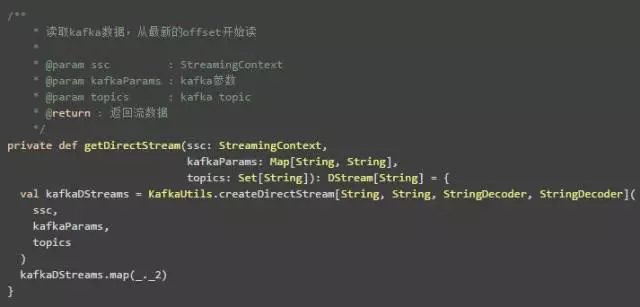
方法createDirectStream中,该方法只需要3个参数,其中kafkaParams还是一样,并未有什么变化,不过其中有个配置auto.offset.reset可以用来指定是从largest或者是smallest处开始读取数据;topic是指Kafka中的topic,可以指定多个。具体提供的方法代码如下:
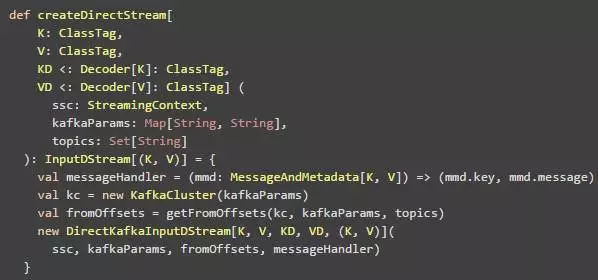
在实际的应用场景中,我们会将两种方法结合起来使用,大体的方向分为两个方面:
应用启动。当程序开发并上线,还未消费Kafka数据,此时从largest处读取数据,采用第二种方法;
应用重启。因资源、网络等其他原因导致程序失败重启时,需要保证从上次的offsets处开始读取数据,此时就需要采用第一种方法来保证我们的场景。
总体方向上,我们采用以上方法满足我们的需要,当然具体的策略我们不在本篇中讨论,后续会有专门的文章来介绍。从largest或者是smallest处读Kafka数据代码实现如下:
程序失败重启的逻辑代码如下:

代码中的fromOffsets参数从外部存储获取并需要处理转换,其代码如下:

该方法提供了从指定offsets处读取Kafka数据。如果发现读取数据异常,我们认为是offsets失败,此种情况去捕获这个异常,然后从largest处读取Kafka数据。
Direct 读取问题
在实际的应用中,Direct Approach方式很好地满足了我们的需要,与Receiver-based方式相比,有以下几方面的优势:
降低资源。Direct不需要Receivers,其申请的Executors全部参与到计算任务中;而Receiver-based则需要专门的Receivers来读取Kafka数据且不参与计算。因此相同的资源申请,Direct 能够支持更大的业务。
降低内存。Receiver-based的Receiver与其他Exectuor是异步的,并持续不断接收数据,对于小业务量的场景还好,如果遇到大业务量时,需要提高Receiver的内存,但是参与计算的Executor并无需那么多的内存。而Direct 因为没有Receiver,而是在计算时读取数据,然后直接计算,所以对内存的要求很低。实际应用中我们可以把原先的10G降至现在的2-4G左右。
鲁棒性更好。Receiver-based方法需要Receivers来异步持续不断的读取数据,因此遇到网络、存储负载等因素,导致实时任务出现堆积,但Receivers却还在持续读取数据,此种情况很容易导致计算崩溃。Direct 则没有这种顾虑,其Driver在触发batch 计算任务时,才会读取数据并计算。队列出现堆积并不会引起程序的失败。
至于其他方面的优势,比如 简化并行(Simplified Parallelism)、高效(Efficiency)以及强一致语义(Exactly-once semantics)在之前已列出,在此不再介绍。虽然Direct 有以上这些优势,但是也存在一些不足,具体如下:
提高成本。Direct需要用户采用checkpoint或者第三方存储来维护offsets,而不像Receiver-based那样,通过ZooKeeper来维护Offsets,此提高了用户的开发成本。
监控可视化。Receiver-based方式指定topic指定consumer的消费情况均能通过ZooKeeper来监控,而Direct则没有这种便利,如果做到监控并可视化,则需要投入人力开发。
总结
本文介绍了基于Spark Streaming的Kafka数据读取方式,包括Receiver-based以及Direct两种方式。两种方式各有优劣,但相对来说Direct 适用于更多的业务场景以及有更好的可护展性。至于如何选择以上两种方式,除了业务场景外也跟团队相关,如果是应用初期,为了快速迭代应用,可以考虑采用第一种方式;如果要深入使用的话则建议采用第二种方式。本文只介绍了两种读取方式,并未涉及到读取策略、优化等问题。这些会在后续的文章中详细介绍。