如何使用YoloV3 训练自己的目标检测模型
使用YoloV3 训练自己的目标检测模型
参考资料:
https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
编译darknet.exe :
1使用vs2015 打开,修改darknet.vcxproj里的cuda版本为你的版本


在C/C++属性的预处理定义中可以选择使用哪些选型,此处将OPENCV添加在预处理定义选项中,取消预处理定义内的内容。这样来开启程序对OPENCV的支持
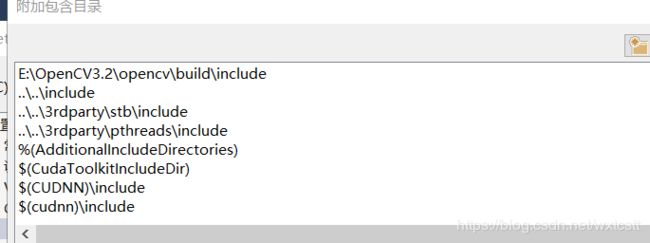
2修改工程里的 Opencv路径信息,添加opencv的库路径和文件
![]()
![]()
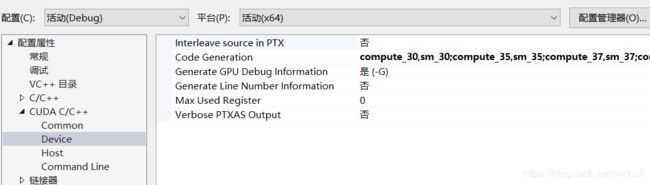
3修改CUDA的计算能力为你的GPU的算力,方法是打开你安装的CUDA的例子把里面工程的Code Generation拷贝到你的darknet工程中
主要 步骤如下:
1 我的训练文件下的文件如下所示,请确保你已经下载或者生成了darknet.exe 程序,darknet.exe将用来训练你需要识别的图像数据
2 在cfg下创建你的配置文件文件 名字任意,如yolo-obj.cfg ,复制yolov3.cfg(这个是官方的配置文件)的内容到此文件中
3 修改yolo-obj.cfg文件 改变如下行,在此文件的最开始的几行
内存较少的GPU可以尽量增大subdivisions的值,如batch=16 subdivision=16 防止出现out of Memory
batch = 64
subdivisions=8 batch值太大可能超过GPU的显存造成无法训练,会在训练过程中报显存耗尽的错误,我的GPU显存是16GB ,增大subdivision可以减少显存的使用,合适的调节这两个值训练精度更高的模型,batch越大越容易收敛,batch越小收敛速度变慢,也可能过拟合,但可能精度更高
4 修改classes=N 其中N修改为你需要识别的物体的种类总数,注意一共有三个 [yolo]层的class位置需要修改
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=2
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=15 根据公式filters=(classes + 5)x3将每一个[yolo] 层前面的第一个[convolutional]层的 [filters=255] 修改为你的公式结果
注意:一共有三个[convolutional]层位置需要修改
[convolutional]
size=1
stride=1
pad=1
filters=21
activation=linear6创建obj.names 每一行存储一个目标类型,例如我的例子中只识别狗和猫 obj.names 内容如下一行一个种类
dog
cat7 创建obj.data 包含如下训练的配置信息,obj.data的内容如下
classes= 2
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = backup/ classes= 2 此处写你的类别数
train = data/train.txt 训练文件的列表,可以使用相对路径也可以是绝对路径,例子如下:
valid = data/train.txt 测试文件的列表,可以和train.txt内容一致
names = data/obj.names 类别文件第6步定义的
backup = backup/ 训练参数的存储目录
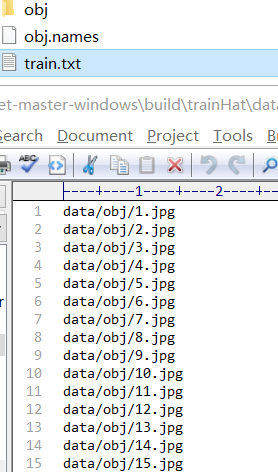
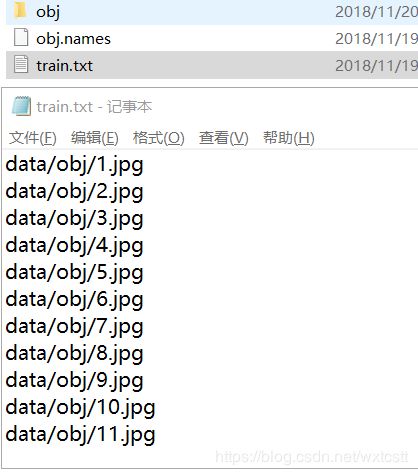
7 把jpg图像放在如\data\obj\的路径下,并把所有的文件名写入train.txt文件中,如下:
8 使用yolomark标记图片,这会为每一个图片创建一个.txt 标记物体的坐标,格式
0 0.503516 0.494444 0.742969 0.916667
yolomark的下载地址如下:
https://download.csdn.net/download/wxtcstt/10858627
yolomark 文件夹内容如下,其中data文件下包括img文件夹包含所有的要训练的图片,obj.names同上包含种类的名字一行一个种类

双击yolo_mark.exe 打开标记软件主页面,切换object id行的标记索引,然后使用鼠标框取图像中的识别物,如下所示,狗在obj.names下的第一行所以索引为0 点击object id的0位置开始框取狗的位置,会自动在狗图片同路径下生成同样名字的txt文件如下,注意:请保持如下图一张图片一张标记txt的结构然后将整个此文件夹内容复制到\data\obj\下作为训练和标记文件,并将train.txt填入图片的路径信息,train.txt不能有错误的图像信息,否则会在训练中报错停止


9: 创建或编辑文件train.txt 在路径data\下 文件内存储训练的图片的路径,相对于darknet.exe的路径
data/obj/1.jpg
data/obj/2.jpg
data/obj/3.jpg
10 下载预训练的参数 https://pjreddie.com/media/files/darknet53.conv.74 放入darknet.exe的路径下
11 使用如下命令开始训练 ,会打开训练界面
darknet.exe detector train obj.data cfg/yolov3hat.cfg darknet53.conv.74开始经历长时间刷屏的等待,模型会逐渐收敛会在data\backup\生成参数文件每一个200M的左右
12 从 data\backup\ 获得训练参数 yolo-obj_XXX.weights
13 测试模型 其中yolo-obj_XXX.weights是你训练好的参数文件,yolo-obj.cfg是你的配置文件
darknet.exe detector test obj.data cfg/yolo-obj.cfg backup/yolo-obj_XXX.weights data/obj/6.jpg