初学乍练redis:分片与集群
目录
一、配置集群
二、增加节点
三、分配插槽
四、获取与插槽对应的节点
五、故障恢复
大部分摘自Redis入门指南(第2版)。
即使使用哨兵,redis集群的每个数据库依然存有集群中的所有数据,从而导致集群的总数据存储受限于可用内存最小的数据库节点,形成木桶效应。由于redis中的所有数据都基于内存存储,这一问题尤为突出,特别是把redis用作持久化存储服务时。
在旧版redis中通常使用客户端分片来解决水平扩容问题,即启动多个redis数据库节点,由客户端决定每个键交由哪个节点存储,下次客户端读取该键时直接到该节点读取。这样可以实现将整个数据分布存储在N个数据库节点中,每个节点只存放总数据量的1/N。但是对于需要扩容的场景来说,在客户端分片后,如果想增加节点,需要对数据进行手工迁移,同时在迁移的过程中为了保证数据一致性,还需要将集群暂时下线,相对比较复杂。
考虑到redis实例非常轻量的特点,可以采用预分片技术(presharding)在一定程度上避免此问题。具体来说是在节点部署初期,就提前考虑日后的存储规模,建立足够多的实例(如128个节点),初期时数据很少,所以每个节点存储的数据也非常少。由于节点轻量的特性,数据之外的内存开销并不大,这使得只需要很少的服务器即可运行这些实例。日后存储规模扩大后,所要做的不过是将某些实例迁移到其它服务器上,而不需要对所有数据进行重新分片并进行集群下线的数据迁移。
无论如何,客户端分片终归有很多缺点,如维护成本高,增加、移除节点较繁琐等。redis 3.0版的一大特性就是支持数据分片的集群功能。集群的特点在于拥有和单机实例同样的性能,同时在网络分区后能够提供一定的可访问性以及对主库故障恢复的支持。另外集群支持几乎所有的单机实例支持的命令,对于涉及多键的命令(如mget),如果每个键都位于同一节点中,则可以正常支持,否则会提示错误。除此之外集群还有一个限制是只能使用默认的0号数据库,如果执行select切换数据库则会提示错误:
(error) ERR SELECT is not allowed in cluster mode哨兵与集群是两个独立的功能,但从特性来看哨兵可以视为集群的子集,当不需要数据分片或者在客户端进行分片的场景下使用哨兵就足够了,但如果需要进行水平扩容,则集群是一个较好的选择。
一、配置集群
使用集群,只需要将每个数据库节点的cluster_enabled配置选项打开即可。每个集群至少需要3个主库才能正常运行。
为了演示集群的应用场景以及故障恢复等操作,这里以配置一个3主3从的集群系统为例。首先建立启动6个redis实例,需要注意的是配置文件中应该打开cluster-enabled:
cluster-enabled yes这里设置6个实例的端口分别是20001到20006。集群会将当前节点记录的集群状态持久化地存储在指定文件中,这个文件默认为当前工作目录下的nodes.conf文件。每个节点对应的文件必须不同,否则会造成启动失败,所以启动节点时需要注意最后为每个节点使用不同的工作目录,或者通过cluster-config-file选项修改持久化文件的名称:
cluster-config-file nodes.conf设置6个redis实例的工作目录为/var/redis/20001至/var/redis/20006,20001实例的配置文件内容如下:
daemonize yes
port 20001
dir "/var/redis/20001"
pidfile "/var/redis/20001/redis.pid"
logfile "/var/redis/20001/redis.log"
protected-mode no
cluster-enabled yes其它实例的配置文件内容类似,除了端口和目录相关的配置不同。准备好配置文件后,启动六个实例:
redis-server /var/redis/20001/redis.conf
redis-server /var/redis/20002/redis.conf
redis-server /var/redis/20003/redis.conf
redis-server /var/redis/20004/redis.conf
redis-server /var/redis/20005/redis.conf
redis-server /var/redis/20006/redis.conf每个节点启动后都会输出类似下面的内容:
No cluster configuration found, I'm 29dc490500ab4ee655d0c06c0adf752da631e821其中29dc490500ab4ee655d0c06c0adf752da631e821表示该节点的运行ID,运行ID是节点在集群中的唯一标识,同一个运行ID,可能地址和端口是不同的。
启动后,可以使用redis命令行客户端连接任意一个节点使用info命令来判断集群是否正常启用了:
[root@hdp4~]#redis-cli -p 20001 info cluster
# Cluster
cluster_enabled:1
[root@hdp4~]#其中cluster_enabled为1表示集群正常启用了。现在每个节点都是完全独立的,要将它们加入同一个集群里还需要几个步骤。redis源代码中提供了一个辅助工具redis-trib.rb可以非常方便地完成这一任务。因为redis-trib.rb是用ruby语言编写的,所以运行前需要在服务器上安装ruby程序。redis-trib.rb依赖于gem包redis,可以执行gem install redis来安装,该命令要求ruby版本在2.2.2及以上,否则报错:
[root@hdp4/var/redis]#gem install redis
Fetching: redis-4.0.2.gem (100%)
ERROR: Error installing redis:
redis requires Ruby version >= 2.2.2.
[root@hdp4/var/redis]#可以使用下面的过程解决该问题,每条命令的作用参见“redis requires ruby version 2.2.2的解决方案”。
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
curl -sSL https://get.rvm.io | bash -s stable
find / -name rvm -print
source /usr/local/rvm/scripts/rvm
rvm list known
rvm install 2.5.1
rvm use 2.5.1
rvm use 2.5.1 --default
rvm remove 2.0.0
ruby --version
gem install redis使用redis-trib.rb来初始化集群,只需要执行:
/root/redis-4.0.11/src/redis-trib.rb create --replicas 1 127.0.0.1:20001 127.0.0.1:20002 127.0.0.1:20003 127.0.0.1:20004 127.0.0.1:20005 127.0.0.1:20006其中create参数表示要初始化集群,--replicas 1表示每个主库拥有的从库个数为1,所以整个集群共有3个主库以及3个从库。
执行完后,redis-trib.rb会输出如下内容:
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
127.0.0.1:20001
127.0.0.1:20002
127.0.0.1:20003
Adding replica 127.0.0.1:20005 to 127.0.0.1:20001
Adding replica 127.0.0.1:20006 to 127.0.0.1:20002
Adding replica 127.0.0.1:20004 to 127.0.0.1:20003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 29dc490500ab4ee655d0c06c0adf752da631e821 127.0.0.1:20001
slots:0-5460 (5461 slots) master
M: 5c1ce88d38e56f2875d28a3ad0d9826a7db7987b 127.0.0.1:20002
slots:5461-10922 (5462 slots) master
M: 7a696ad25bb57f375ac64cab991c4bd58062b2a7 127.0.0.1:20003
slots:10923-16383 (5461 slots) master
S: 5db8ddbbf35d6a8c750f89b290fc1953cbc28a44 127.0.0.1:20004
replicates 5c1ce88d38e56f2875d28a3ad0d9826a7db7987b
S: 719552d1296c1a21835591efca4458620fb7ff63 127.0.0.1:20005
replicates 7a696ad25bb57f375ac64cab991c4bd58062b2a7
S: 1a3b85286c5033e8ed403c1cb6a66043e472eb98 127.0.0.1:20006
replicates 29dc490500ab4ee655d0c06c0adf752da631e821
Can I set the above configuration? (type 'yes' to accept): yes内容包括集群具体的分配方案,如果觉得没问题则输入yes来开始创建,接下来的输出如下:
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join...
>>> Performing Cluster Check (using node 127.0.0.1:20001)
M: 29dc490500ab4ee655d0c06c0adf752da631e821 127.0.0.1:20001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: 1a3b85286c5033e8ed403c1cb6a66043e472eb98 127.0.0.1:20006
slots: (0 slots) slave
replicates 29dc490500ab4ee655d0c06c0adf752da631e821
S: 5db8ddbbf35d6a8c750f89b290fc1953cbc28a44 127.0.0.1:20004
slots: (0 slots) slave
replicates 5c1ce88d38e56f2875d28a3ad0d9826a7db7987b
S: 719552d1296c1a21835591efca4458620fb7ff63 127.0.0.1:20005
slots: (0 slots) slave
replicates 7a696ad25bb57f375ac64cab991c4bd58062b2a7
M: 5c1ce88d38e56f2875d28a3ad0d9826a7db7987b 127.0.0.1:20002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
M: 7a696ad25bb57f375ac64cab991c4bd58062b2a7 127.0.0.1:20003
slots:10923-16383 (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.下面根据输出信息详细介绍集群创建的过程。
首先redis-trib.rb会以客户端的形式尝试连接所有的节点,并发送ping命令以确定节点能够正常服务。如果有任何节点无法连接,则创建失败。同时发送info命令获取每个节点的运行ID以及是否开启了集群功能(即cluster_enabled为1)。
准备就绪后集群会向每个节点发送cluster meet命令,格式为cluster meet ip port,这个命令用来告诉当前节点指定ip和port上在运行的节点也是集群的一部分,从而使得6个节点最终可以归入一个集群。
然后redis-trib.rb会分配主从库节点,分配的原则是尽量保证每个主库运行在不同的IP地址上,同时每个从库和主库均不运行在同一IP地址上,以保证系统的容灾能力。分配结果如下:
Using 3 masters:
127.0.0.1:20001
127.0.0.1:20002
127.0.0.1:20003
Adding replica 127.0.0.1:20005 to 127.0.0.1:20001
Adding replica 127.0.0.1:20006 to 127.0.0.1:20002
Adding replica 127.0.0.1:20004 to 127.0.0.1:20003其中主库是20001、20002、20003端口上的节点,20005是20001的从库,20006是20002的从库,20004是20003的从库。因为我们是在一台主机上,用不同端口模拟集群节点,输出中会有如下警告:
[WARNING] Some slaves are in the same host as their master主从分配完成后,会为每个主库分配插槽,分配插槽的过程其实就是分配哪些键归哪些节点负责。之后对每个要成为从库的节点发送cluster replicate 主库运行ID,来将当前节点转换成从库并复制指定运行ID的主库节点。
此时整个集群的过程即创建完成,使用redis命令行客户端连接任意一个节点执行cluster nodes可以获得集群中的所有节点信息,如在20001执行:
[root@hdp4~]#redis-cli -p 20001 cluster nodes
1a3b85286c5033e8ed403c1cb6a66043e472eb98 127.0.0.1:20006@30006 slave 29dc490500ab4ee655d0c06c0adf752da631e821 0 1536894759000 1 connected
5db8ddbbf35d6a8c750f89b290fc1953cbc28a44 127.0.0.1:20004@30004 slave 5c1ce88d38e56f2875d28a3ad0d9826a7db7987b 0 1536894755658 4 connected
719552d1296c1a21835591efca4458620fb7ff63 127.0.0.1:20005@30005 slave 7a696ad25bb57f375ac64cab991c4bd58062b2a7 0 1536894757000 5 connected
29dc490500ab4ee655d0c06c0adf752da631e821 127.0.0.1:20001@30001 myself,master - 0 1536894757000 1 connected 0-5460
5c1ce88d38e56f2875d28a3ad0d9826a7db7987b 127.0.0.1:20002@30002 master - 0 1536894758665 2 connected 5461-10922
7a696ad25bb57f375ac64cab991c4bd58062b2a7 127.0.0.1:20003@30003 master - 0 1536894759666 3 connected 10923-16383
[root@hdp4~]#从上面的输出中可以看到所有节点的运行ID、地址和端口、角色、状态以及负责的插槽等信息。redis-trib.rb是一个非常好用的辅助工具,其本质是通过执行redis命令来辅助集群管理任务。
二、增加节点
redis是使用cluster meet命令来使每个节点认识集群中的其它节点的,可想而知如果想要向集群中加入新的节点,也需要使用cluster meet命令实现。加入新节点非常简单,只需要向新节点(以下记作A)发送如下命令即可:
cluster meet ip portip和port是集群中任意一个节点(主从均可)的地址和端口号,A接收到客户端发来的命令后,会与该地址和端口号的节点B进行握手,使B将A认作当前集群中的一员。B与A握手成功后,B会使用Gossip协议将节点A的信息通知给集群中的每一个节点。通过这一方式,即使集群中有多个节点,也只需要选择meet其中任意一个节点,即可使新节点最终加入整个集群。
为保证每个主库的可用性,一般一次加两个节点,一个作为主库,另一个作为新主库的从库。下面向集群中添加两个新节点20007和20008。
1. 启动20007、20008两个redis实例,目录与配置文件和其它节点类似。
redis-server /var/redis/20007/redis.conf
redis-server /var/redis/20008/redis.conf2. 将新节点加入集群
redis-cli -p 20007 cluster meet 127.0.0.1 20006
redis-cli -p 20008 cluster meet 127.0.0.1 200063. 查看集群节点,可以看到20007、20008两个新节点已经加到集群中,默认角色是主库。
[root@hdp4/var/redis/20008]#redis-cli -p 20001 cluster nodes
529ca76cfe1c01231545c499f6760851a735ce54 127.0.0.1:20007@30007 master - 0 1536896078000 0 connected
1a3b85286c5033e8ed403c1cb6a66043e472eb98 127.0.0.1:20006@30006 slave 29dc490500ab4ee655d0c06c0adf752da631e821 0 1536896078000 1 connected
5db8ddbbf35d6a8c750f89b290fc1953cbc28a44 127.0.0.1:20004@30004 slave 5c1ce88d38e56f2875d28a3ad0d9826a7db7987b 0 1536896077899 4 connected
719552d1296c1a21835591efca4458620fb7ff63 127.0.0.1:20005@30005 slave 7a696ad25bb57f375ac64cab991c4bd58062b2a7 0 1536896078903 5 connected
29dc490500ab4ee655d0c06c0adf752da631e821 127.0.0.1:20001@30001 myself,master - 0 1536896074000 1 connected 0-5460
432289dd3c84d658e6620fe5af14f36fbb11790e 127.0.0.1:20008@30008 master - 0 1536896078000 7 connected
5c1ce88d38e56f2875d28a3ad0d9826a7db7987b 127.0.0.1:20002@30002 master - 0 1536896078000 2 connected 5461-10922
7a696ad25bb57f375ac64cab991c4bd58062b2a7 127.0.0.1:20003@30003 master - 0 1536896079904 3 connected 10923-16383
[root@hdp4/var/redis/20008]#三、分配插槽
新的节点加入集群后有两种选择,要么使用cluster replicate命令复制每个主库来以从库的形式运行,要么向集群申请分配插槽(slot)来以主库的形式运行。
在一个集群中,所有的键会被分配给16384个插槽,而每个主库会负责处理其中的一部分插槽。现在再回过头来看创建集群时的输出:
M: 29dc490500ab4ee655d0c06c0adf752da631e821 127.0.0.1:20001
slots:0-5460 (5461 slots) master
M: 5c1ce88d38e56f2875d28a3ad0d9826a7db7987b 127.0.0.1:20002
slots:5461-10922 (5462 slots) master
M: 7a696ad25bb57f375ac64cab991c4bd58062b2a7 127.0.0.1:20003
slots:10923-16383 (5461 slots) master上面的每一行表示一个主库的信息,其中可以看到20001负责处理0-5460这5461个插槽,20002负责处理5461-10922这5462个插槽,20003负责处理10923-12539这5461个插槽。虽然redis-trib.rb初始化集群时分配给每个节点的插槽都是连续的,但是实际上redis并没有此限制,可以将任意的几个插槽分配给任意的节点负责。
在介绍如何将插槽分配给指定的节点前,先来介绍键与插槽的对应关系。redis将每个键的键名的有效部分使用CRC16算法计算出散列值,然后取对16384的余数。这样使得每个键都可以分配到16384个插槽中,进而分配到指定的一个节点处理。这里键名的有效部分是指:
(1)如果键名包含{符号,且在{符号后面存在}符号,并且{和}之间有至少一个字符,则有效部分是指{和}之间的内容;
(2)如果不满足上一条规则,那么整个键名为有效部分。
例如,键hello.world的有效部分为"hello.world",键{user102}:last.name的有效部分为"user102"。如果命令涉及多个键(如mget),只有当所有键都位于同一个节点时redis才能正常支持。利用键的分配规则,可以将所有相关的键的有效部分设置成同样的值,使得相关键都能分配到同一个节点以支持多键操作。比如,{user102}:first.name和{user102}:last.name会被分配到同一个节点,所以可以使用mget {user102}:first.name {user102}:last.name来同时获取两个键的值。
介绍完键与插槽的对应关系后,再来介绍如何将插槽分配给指定节点。插槽的分配分为如下几种情况。
(1)插槽之前没有被分配过,现在想分配给指定节点。
(2)插槽之前被分配过,现在想移动到指定节点。
其中第一种情况使用cluster addslots命令来实现,redis-trib.rb也是通过该命令在创建集群时为新节点分配插槽的。cluster addslots命令的用法为:
cluster addslots slot1 [slot2] ... [slotN]如将100和101两个插槽分配给某个节点,只需要在该节点执行:cluster addslots 100 101 即可。如果指定插槽已经分配过,则会提示错误:
[root@hdp4/var/redis]#redis-cli -p 20007 cluster addslots 100 101
(error) ERR Slot 100 is already busy
[root@hdp4/var/redis]#可以通过命令cluster slots来查看插槽的分配情况:
[root@hdp4/var/redis]#redis-cli -p 20001 cluster slots
1) 1) (integer) 0
2) (integer) 5460
3) 1) "127.0.0.1"
2) (integer) 20001
3) "29dc490500ab4ee655d0c06c0adf752da631e821"
4) 1) "127.0.0.1"
2) (integer) 20006
3) "1a3b85286c5033e8ed403c1cb6a66043e472eb98"
2) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 20003
3) "7a696ad25bb57f375ac64cab991c4bd58062b2a7"
4) 1) "127.0.0.1"
2) (integer) 20005
3) "719552d1296c1a21835591efca4458620fb7ff63"
3) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 20002
3) "5c1ce88d38e56f2875d28a3ad0d9826a7db7987b"
4) 1) "127.0.0.1"
2) (integer) 20004
3) "5db8ddbbf35d6a8c750f89b290fc1953cbc28a44"
[root@hdp4/var/redis]#其中返回结果的格式很容易理解,一共3条记录,每条记录的前两个值表示插槽的开始号码和结束号码,后面的值则为负责该插槽的节点,包括主库和其所有的从库,主库始终在第一位。
对于情况2,处理起来相对复杂一些,不过redis-trib.rb提供了比较方便的方式来对插槽进行迁移。我们首先使用redis-trib.rb将一个插槽从20001迁移到20002,然后在介绍如何不使用redis-trib.rb来完成迁移。
首先执行如下命令:
/root/redis-4.0.11/src/redis-trib.rb reshard 127.0.0.1:20001其中reshard表示告诉redis-trib.rb要重新分片,127.0.0.1:20001是集群中的任意一个节点的地址和端口,redis-trib.rb会自动获取集群信息。
接下来,redis-trib.rb将会询问具体如何进行重新分片,首先会询问想要迁移多少个插槽:
How many slots do you want to move (from 1 to 16384)?我们只需要迁移一个,所以输入1后回车。接下来redis-trib.rb会询问要把插槽迁移到哪个节点:
What is the receiving node ID?可以通过cluster nodes命令获取20002的运行ID,这里是5c1ce88d38e56f2875d28a3ad0d9826a7db7987b,输入并回车。接着最后一步是询问从哪个节点移出插槽:
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.我们输入20001对应的运行ID,按回车然后输入done再按回车确认即可。接下来输入yes来确认重新分片方案,重新分片即告成功。
Moving slot 0 from 127.0.0.1:20001 to 127.0.0.1:20002:使用cluster slots命令获取当前插槽的分配情况如下:
[root@hdp4/var/redis]#redis-cli -p 20001 cluster slots
1) 1) (integer) 1
2) (integer) 5460
3) 1) "127.0.0.1"
2) (integer) 20001
3) "29dc490500ab4ee655d0c06c0adf752da631e821"
4) 1) "127.0.0.1"
2) (integer) 20006
3) "1a3b85286c5033e8ed403c1cb6a66043e472eb98"
2) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 20003
3) "7a696ad25bb57f375ac64cab991c4bd58062b2a7"
4) 1) "127.0.0.1"
2) (integer) 20005
3) "719552d1296c1a21835591efca4458620fb7ff63"
3) 1) (integer) 0
2) (integer) 0
3) 1) "127.0.0.1"
2) (integer) 20002
3) "5c1ce88d38e56f2875d28a3ad0d9826a7db7987b"
4) 1) "127.0.0.1"
2) (integer) 20004
3) "5db8ddbbf35d6a8c750f89b290fc1953cbc28a44"
4) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 20002
3) "5c1ce88d38e56f2875d28a3ad0d9826a7db7987b"
4) 1) "127.0.0.1"
2) (integer) 20004
3) "5db8ddbbf35d6a8c750f89b290fc1953cbc28a44"
[root@hdp4/var/redis]#可以看到现在比之前多了一条记录(上面的第三条记录),第0号插槽已经由20002负责,此时重新分片成功。
那么redis-trib.rb实现重新分片的原理是什么,我们如何不借助redis-trib.rb手工进行重新分片呢?使用如下命令即可:
cluster setslot 插槽号 node 新节点的运行ID如想要把0号插槽迁移回20001:
[root@hdp4/var/redis]#redis-cli -p 20001 cluster setslot 0 node 29dc490500ab4ee655d0c06c0adf752da631e821
OK
[root@hdp4/var/redis]# 此时重新使用cluster slots查看插槽的分配情况,可以看到已经恢复如初了。
然而这样这样迁移的前提是插槽中没有任何键,因为使用cluster setslot命令迁移插槽时并不会连同相应的键一起迁移,这就造成了客户端在指定节点无法找到未迁移的键,造成这些键对客户端来说“丢失了”。为此需要手工获取插槽中存在那些键,然后将每个键迁移到新的节点中才行。
手工获取某个插槽存在哪些键的方法是:
cluster getkeysinslot 插槽号,要返回的键的数量之后对每个键,使用migrate命令将其迁移到目标节点:
migrate 目标节点地址 目标节点端口 键名 数据库号码 超时时间 [copy] [replace]其中copy选项表示不将键从当前数据库中删除,而是复制一份副本。replace表示如果目标节点存在同名键,则覆盖。因为集群只能使用0号数据库,所以数据库好始终为0。如要把键abc从当前节点(如20002)迁移到20001:
migrate 127.0.0.1 20001 abc 0 15999 replace至此,我们已经知道如何将插槽委派给其它节点,并同时将当前节点中插槽下所有的键迁移到目标节点中。然而还有最后一个问题是如果要迁移的数据量比较大,整个过程会花费较长时间,那么究竟在什么时候执行cluster setslot命令来完成插槽的交接呢?如果在键迁移未完成时执行,那么客户端就会尝试在新的节点读取键值,此时还没有迁移完成,自然有可能读不到键值,从而造成相关键的临时“丢失”。相反,如果在键迁移完成后再执行,那么在迁移时客户端会在旧的节点读取键值,然后有些键已经迁移到新的节点上了,同样也会造成键的临时“丢失”。那么redis-trib.rb工具是如何解决这个问题的呢?
redis提供了如下两个命令用来实现在集群不下线的情况下迁移数据:
cluster setslot 插槽号 migrating 新节点的运行ID
cluster setslot 插槽号 importing 原节点的运行ID 进行迁移时,假设要把0号插槽从A迁移到B,此时redis-trib.rb会依次执行如下操作:
(1)在B执行cluster setslot 0 importing A。
(2)在A执行cluster setslot 0 migrating B。
(3)执行cluster getkeysinslot 0 获取0号插槽的键列表。
(4)对第3步获取的每个键执行migrate命令,将其从A迁移到B。
(5)执行cluster setslot 0 node B来完成迁移。
从上面的步骤来看redis-trib.rb多了 1 和 2 两个步骤,这两个步骤就是为了解决迁移过程中键的临时“丢失”问题。首先执行完前两步后,当客户端向A请求插槽0中的键时,如果键存在(即尚未被迁移),则正常处理。如果不存在,则返回一个ASK跳转请求,告诉客户端这个键在B里,如图1所示。客户端接收到ASK跳转请求后,首先向B发送ASKING命令,然后重新发送之前的命令。相反,当客户端向B请求插槽0中的键时,如果前面执行了ASKING命令,则返回键值内容,否则返回MOVED跳转请求,如图2所示。这样一来客户端只要能够处理ASK跳转,则可以在数据库迁移时自动从正确的节点获取到相应的键值,避免了键在迁移过程中临时“丢失”的问题。
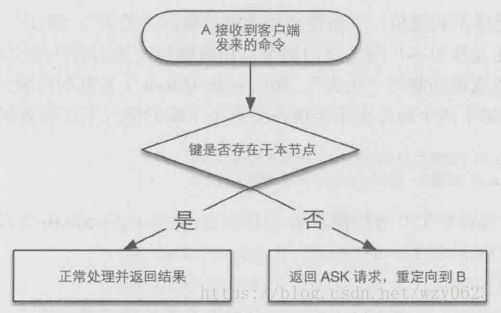 图1 A的命令处理流程
图1 A的命令处理流程
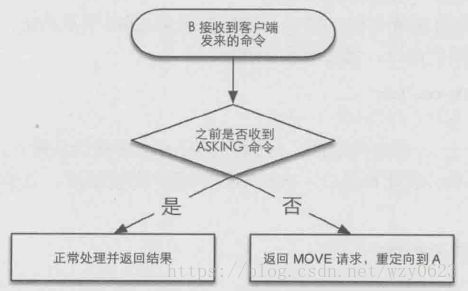 图2 B的命令处理流程
图2 B的命令处理流程
下面步骤使用redis-trib.rb将20001的前100个(0-99)插槽分配给20007,然后将20008置为20007的从库。
/root/redis-4.0.11/src/redis-trib.rb reshard 127.0.0.1:20001
redis-cli -p 20008 cluster replicate 529ca76cfe1c01231545c499f6760851a735ce54查看集群节点确认:
[root@hdp4/var/redis]#redis-cli -p 20001 cluster slots
1) 1) (integer) 0
2) (integer) 99
3) 1) "127.0.0.1"
2) (integer) 20007
3) "77c7b70656fa7da8f2a2a18d263d27b2d2bebf87"
4) 1) "127.0.0.1"
2) (integer) 20008
3) "57c1887ef41303b4022410a3642e33a6e5792afc"
2) 1) (integer) 100
2) (integer) 5460
3) 1) "127.0.0.1"
2) (integer) 20001
3) "8bfc95799d5526dbc459e6ba7e09273be0e294ac"
4) 1) "127.0.0.1"
2) (integer) 20004
3) "174f212703fc2d7d9f71695e15b63a153f871a9b"
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 20003
3) "7f5ae9d475fcbd44ea4faf7ccab952b5c0826ecb"
4) 1) "127.0.0.1"
2) (integer) 20006
3) "b0f59c91430553307b6da94c49fb8c033fb10559"
4) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 20002
3) "4427b2d29a32fad9d98c002dcf2d872f3784ab70"
4) 1) "127.0.0.1"
2) (integer) 20005
3) "459278a1c1657733ad9b71246a2ffb532597ad4e"
[root@hdp4/var/redis]#四、获取与插槽对应的节点
对于指定的键,可以根据前文所述的算法来计算其属于哪个插槽,但是如何获取某一个键由哪个检点负责呢?实际上,当客户端向集群中的任意一个节点发送命令后,该节点会判断相应的键是否在当前节点中,如果键在该节点中,则会像单机实例一样正常处理该命令;如果键不在该节点中,就会返回一个MOVE重定向请求,告诉客户端这个键目前由哪个节点负责,然后客户端再将同样的请求向目标节点重新发送一次以获得结果。
一些语言的redis库支持代理MOVE请求,所以对于开发者而言命令重定向的过程是透明的,使用集群与使用单机实例没有什么不同。然而有些语言的redis库并不支持集群,这时就需要在客户端编码处理了。
还是以上面的集群配置为例,键foo实际应该由20003负责,通过尝试在20001节点执行与键foo相关的命令,就会有如下输出:
[root@hdp4/var/redis]#redis-cli -p 20001 set foo bar
(error) MOVED 12182 127.0.0.1:20003
[root@hdp4/var/redis]#返回的是一个MOVE重定向请求,12182表示foo所属的插槽号,127.0.0.1:20003则是负责该插槽的节点地址和端口,客户端收到重定向请求后,应该将命令重定向20003节点发送一次:
[root@hdp4/var/redis]#redis-cli -p 20003 set foo bar
OK
[root@hdp4/var/redis]#redis命令行客户端提供了集群模式来支持自动重定向,使用-c参数来启用:
[root@hdp4/var/redis]#redis-cli -c -p 20001
127.0.0.1:20001> set foo bar
-> Redirected to slot [12182] located at 127.0.0.1:20003
OK
127.0.0.1:20003> 可见加入了 -c 参数后,如果当前节点并不负责要处理的键,redis命令行客户端会进行自动命令重定向,而这一过程正是每个支持集群的客户端应该实现的。
然而相比单机实例,集群的命令重定向也增加了命令的请求次数,原先只需要执行一次的命令现在可能需要依次发向两个节点,算上往返时延,可以说请求重定向对性能还是有些影响的。
为了解决这一问题,当发现新的重定向请求时,客户端应该在重新向正确节点发送命令的同时,缓存插槽的路由信息,即记录当下插槽是由哪个节点负责的。这样每次发起命令时,客户端首先计算相关键是属于哪个插槽的,然后根据缓存的路由判断插槽由哪个节点负责。考虑到插槽总数相对较少(16384个),缓存所有插槽的路由信息后,每次命令将均只发向正确的节点,从而达到和单机实例同样的性能。
五、故障恢复
在一个集群中,每个节点都会定期向其它节点发送ping命令,并通过有没有收到回复来判断目标节点是否已经下线了。具体来说,集群中的每个节点每隔1秒就会随机选择5个节点,然后选择其中最久没有响应的节点发送ping命令。
如果一定时间内目标节点没有响应回复,则发起ping命令的节点会认为目标节点疑似下线(pfail)。疑似下线可以与哨兵的主观下线类比,两者都表示某一节点从自身的角度认为目标节点是下线的状态。与哨兵的模式类似,如果要使在整个集群中的所有节点都认为某一节点已经下线,需要一定数量的节点都认为该节点疑似下线才可以,这一过程具体为:
(1)一旦节点A认为节点B是疑似下线状态,就会在集群中传播该消息,所有其它节点收到消息后都会记录这一信息;
(2)当集群中的某一节点C收集到半数以上的节点认为B是疑似下线的状态时,就会将B标记为下线(fail),并且向集群中的其它节点传播该消息,从而使得B在整个集群中下线。
在集群中,当一个主库下线时,就会出现一部分插槽无法写入的问题。这时如果该主库拥有至少一个从库,集群就进行故障恢复操作来将其中一个从库转变成主库来保证集群的完整。选择哪个从库作为主库的过程与在哨兵中选择领头哨兵的过程一样,都是基于Raft算法,过程如下:
(1)发现其复制的主库下线的从库(下面称作A)向每个集群中的节点发送请求,要求对方选自己成为主库。
(2)如果收到请求的节点没有选过其他人,则会同意将A设置成主库。
(3)如果A发现有超过集群中节点总数一半的节点同意选自己成为主库,则A成功成为主库。
(4)当有多个从库节点同时参选主库,则会出现没有任何节点当选的可能。此时每个参选节点将等待一个随机时间重新发起参选请求,进行下一轮选举,直到选举成功。
当某个从库当选为主库后,会通过命令slaveof no one将自己转换成主库,并将就的主库的插槽转换给自己负责。如果一个至少负责一个插槽的主库下线且没有相应的从库可以进行故障恢复,则整个集群默认会进入下线状态无法继续工作。如果想在这种情况下使集群仍能正常工作,可以修改配置cluster-require-full-coverage为no(默认为yes):
[root@hdp4~]#redis-cli -c -p 20001 config get cluster-require-full-coverage
1) "cluster-require-full-coverage"
2) "yes"
[root@hdp4~]#redis-cli -c -p 20001 config set cluster-require-full-coverage no
OK
[root@hdp4~]#redis-cli -c -p 20001 config get cluster-require-full-coverage
1) "cluster-require-full-coverage"
2) "no"
[root@hdp4~]#