Python爬虫之BeautifulSoup爬取天气网
Python爬虫之BeautifulSoup爬取天气网
代码如下
import requests
from lxml import etree
from bs4 import BeautifulSoup
from pyecharts import Bar
ALL_DATA = []
def parse_page(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"
}
response = requests.get(url, headers=headers)
text = response.content.decode("UTF-8")
soup = BeautifulSoup(text, 'html5lib')
conMidtab = soup.find('div', class_='conMidtab')
tables = conMidtab.find_all('table')
for table in tables:
trs = table.find_all('tr')[2:]
for index, tr in enumerate(trs):
tds = tr.find_all("td")
city_td = tds[0]
if index == 0:
city_td = tds[1]
city = list(city_td.stripped_strings)[0]
temp_td = tds[-2]
min_temp = list(temp_td.stripped_strings)[0]
ALL_DATA.append({"城市": city, "最低气温": int(min_temp)})
# print({"城市": city, "最低气温": int(min_temp)})
def main():
urls = ["http://www.weather.com.cn/textFC/hb.shtml",
"http://www.weather.com.cn/textFC/db.shtml",
"http://www.weather.com.cn/textFC/hd.shtml",
"http://www.weather.com.cn/textFC/hz.shtml",
"http://www.weather.com.cn/textFC/hn.shtml",
"http://www.weather.com.cn/textFC/xb.shtml",
"http://www.weather.com.cn/textFC/xn.shtml",
"http://www.weather.com.cn/textFC/gat.shtml"
]
for url in urls:
parse_page(url)
# 分析数据
# 根据最低气温排序
ALL_DATA.sort(key=lambda data: data['最低气温'])
data = ALL_DATA[0:10]
for da in data:
print(da)
# 安装pyecharts
cities = list(map(lambda x: x['城市'], data))
temps = list(map(lambda x: x['最低气温'], data))
chart = Bar("中国天气最低气温")
chart.add('', cities, temps)
chart.render("tianqi.html")
if __name__ == '__main__':
main()
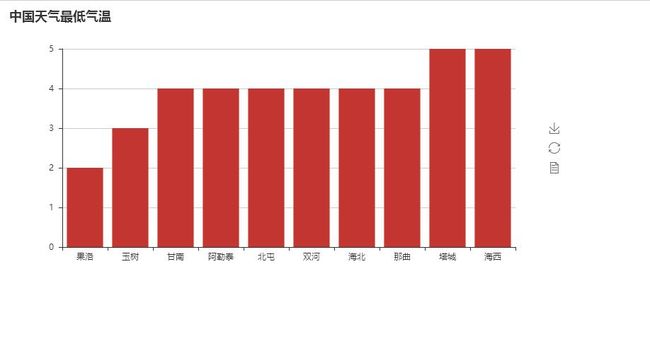
效果图
项目地址:https://gitee.com/java521/BeautifulSoup