http1.0 http1.1 http2 之间的区别
一、HTTP基础
1.1 HTTP定义
HTTP协议(HyperTextTransferProtocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传输协议。
1.2 HTTP发展史

1.3 HTTP1.0
早先1.0的HTTP版本,是一种无状态、无连接的应用层协议。
HTTP1.0规定浏览器和服务器保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器处理完成后立即断开TCP连接(无连接),服务器不跟踪每个客户端也不记录过去的请求(无状态)。
这种无状态性可以借助cookie/session机制来做身份认证和状态记录。而下面两个问题就比较麻烦了。
首先,无连接的特性导致最大的性能缺陷就是无法复用连接。每次发送请求的时候,都需要进行一次TCP的连接,而TCP的连接释放过程又是比较费事的。这种无连接的特性会使得网络的利用率非常低。
其次就是队头阻塞(head of line blocking)。由于HTTP1.0规定下一个请求必须在前一个请求响应到达之前才能发送。假设前一个请求响应一直不到达,那么下一个请求就不发送,同样的后面的请求也给阻塞了。
为了解决这些问题,HTTP1.1出现了。
1.4 HTTP的基本优化方向
影响一个 HTTP 网络请求的因素主要有两个:带宽和延迟。
带宽:如果说我们还停留在拨号上网的阶段,带宽可能会成为一个比较严重影响请求的问题,但是现在网络基础建设已经使得带宽得到极大的提升,我们不再会担心由带宽而影响网速,那么就只剩下延迟了。
延迟:
-
浏览器阻塞(HOL blocking):浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有 4 个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。
-
DNS 查询(DNS Lookup):浏览器需要知道目标服务器的 IP 才能建立连接。将域名解析为 IP 的这个系统就是 DNS。这个通常可以利用DNS缓存结果来达到减少这个时间的目的。
-
建立连接(Initial connection):HTTP 是基于 TCP 协议的,浏览器最快也要在第三次握手时才能捎带 HTTP 请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
二、HTTP1.0和HTTP1.1的一些区别
HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。 主要区别主要体现在:
对于HTTP1.1,不仅继承了HTTP1.0简单的特点,还克服了诸多HTTP1.0性能上的问题。
首先是长连接,HTTP1.1增加了一个Connection字段,通过设置Keep-Alive可以保持HTTP连接不断开,避免了每次客户端与服务器请求都要重复建立释放建立TCP连接,提高了网络的利用率。如果客户端想关闭HTTP连接,可以在请求头中携带Connection: false来告知服务器关闭请求。
其次,是HTTP1.1支持请求管道化(pipelining)。基于HTTP1.1的长连接,使得请求管道化成为可能。管线化使得请求能够“并行”传输。举个例子来说,假如响应的主体是一个html页面,页面中包含了很多img,这个时候keep-alive就起了很大的作用,能够进行“并行”发送多个请求。(注意这里的“并行”并不是真正意义上的并行传输,具体解释如下。)
需要注意的是,服务器必须按照客户端请求的先后顺序依次回送相应的结果,以保证客户端能够区分出每次请求的响应内容。
也就是说,HTTP管道化可以让我们把先进先出队列从客户端(请求队列)迁移到服务端(响应队列)。
HTTP 1.1
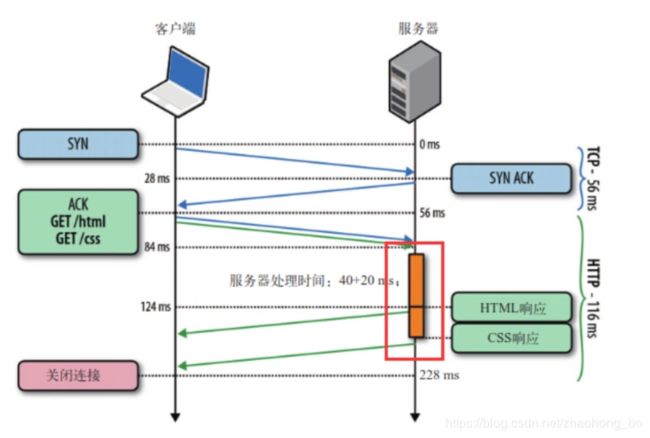
如图所示,客户端同时发了两个请求分别来获取html和css,假如说服务器的css资源先准备就绪,服务器也会先发送html再发送css。
换句话来说,只有等到html响应的资源完全传输完毕后,css响应的资源才能开始传输。也就是说,不允许同时存在两个并行的响应。
可见,HTTP1.1还是无法解决队头阻塞(head of line blocking)的问题。同时“管道化”技术存在各种各样的问题,所以很多浏览器要么根本不支持它,要么就直接默认关闭,并且开启的条件很苛刻…而且实际上好像并没有什么用处。
那我们在谷歌控制台看到的并行请求又是怎么一回事呢?
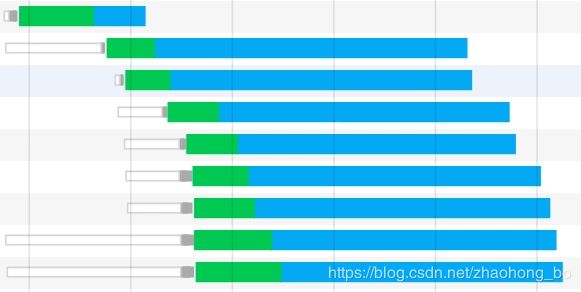
如图所示,绿色部分代表请求发起到服务器响应的一个等待时间,而蓝色部分表示资源的下载时间。按照理论来说,HTTP响应理应当是前一个响应的资源下载完了,下一个响应的资源才能开始下载。而这里却出现了响应资源下载并行的情况。这又是为什么呢?
其实,虽然HTTP1.1支持管道化,但是服务器也必须进行逐个响应的送回,这个是很大的一个缺陷。实际上,现阶段的浏览器厂商采取了另外一种做法,它允许我们打开多个TCP的会话。也就是说,上图我们看到的并行,其实是不同的TCP连接上的HTTP请求和响应。这也就是我们所熟悉的浏览器对同域下并行加载6~8个资源的限制。而这,才是真正的并行!
此外,HTTP1.1还加入了缓存处理(强缓存和协商缓存)新的字段如cache-control,支持断点传输,以及增加了Host字段(使得一个服务器能够用来创建多个Web站点)。
HTTPS与HTTP的一些区别
- HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
- HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
- HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
HTTP 2.0 vs HTTP 1.0 性能
HTTP 2.0 的出现,相比于 HTTP 1.x ,大幅度的提升了 web 性能。

这是 Akamai 公司建立的一个官方的演示,用以说明 HTTP/2 相比于之前的 HTTP/1.1 在性能上的大幅度提升。 同时请求 379 张图片,从Load time 的对比可以看出 HTTP/2 在速度上的优势。
三、HTTP 1.1 和 HTTP 2.0 区别
后面我们将通过几个方面来说说HTTP 2.0 和 HTTP1.1 区别,并且和你解释下其中的原理。
3.1 二进制分帧
HTTP2.0通过在应用层和传输层之间增加一个二进制分帧层,突破了HTTP1.1的性能限制、改进传输性能。
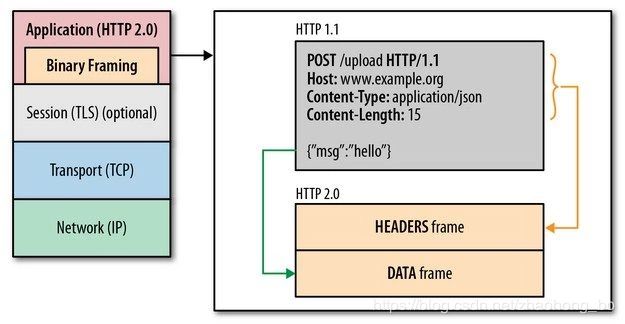
可见,虽然HTTP2.0的协议和HTTP1.x协议之间的规范完全不同了,但是实际上HTTP2.0并没有改变HTTP1.x的语义。
简单来说,HTTP2.0只是把原来HTTP1.x的header和body部分用frame重新封装了一层而已。
3.2 多路复用
下面是几个概念:
- 流(stream):已建立连接上的双向字节流。
- 消息:与逻辑消息对应的完整的一系列数据帧。
- 帧(frame):HTTP2.0通信的最小单位,每个帧包含帧头部,至少也会标识出当前帧所属的流(stream id)。
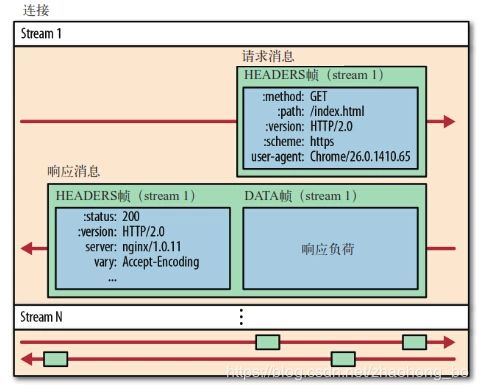
从图中可见,所有的HTTP2.0通信都在一个TCP连接上完成,这个连接可以承载任意数量的双向数据流。
每个数据流以消息的形式发送,而消息由一或多个帧组成。这些帧可以乱序发送,然后再根据每个帧头部的流标识符(stream id)重新组装。
举个例子,每个请求是一个数据流,数据流以消息的方式发送,而消息又分为多个帧,帧头部记录着stream id用来标识所属的数据流,不同属的帧可以在连接中随机混杂在一起。接收方可以根据stream id将帧再归属到各自不同的请求当中去。
另外,多路复用(连接共享)可能会导致关键请求被阻塞。HTTP2.0里每个数据流都可以设置优先级和依赖,优先级高的数据流会被服务器优先处理和返回给客户端,数据流还可以依赖其他的子数据流。
可见,HTTP2.0实现了真正的并行传输,它能够在一个TCP上进行任意数量HTTP请求。而这个强大的功能则是基于“二进制分帧”的特性。
多路复用允许单一的 HTTP/2 连接同时发起多重的请求-响应消息。看个例子:
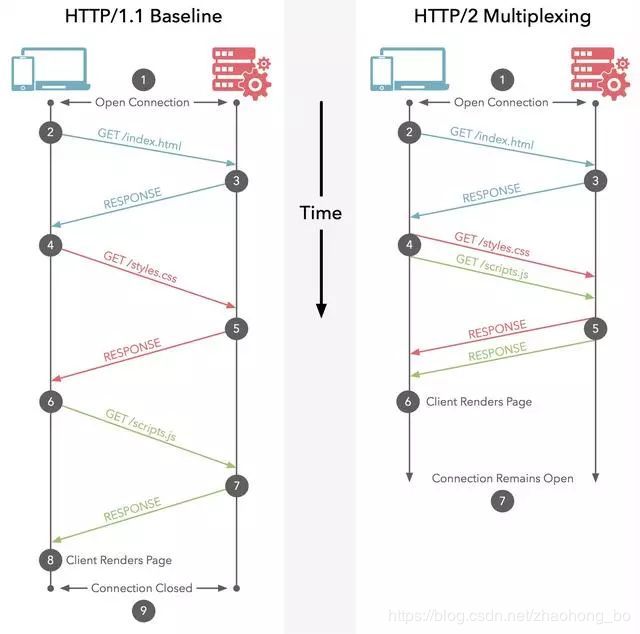
整个访问流程第一次请求index.html页面,之后浏览器会去请求style.css和scripts.js的文件。左边的图是顺序加载两个个文件的,右边则是并行加载两个文件。
我们知道HTTP底层其实依赖的是TCP协议,那问题是在同一个连接里面同时发生两个请求响应着是怎么做到的?
首先你要知道,TCP连接相当于两根管道(一个用于服务器到客户端,一个用于客户端到服务器),管道里面数据传输是通过字节码传输,传输是有序的,每个字节都是一个一个来传输。
例如客户端要向服务器发送Hello、World两个单词,只能是先发送Hello再发送World,没办法同时发送这两个单词。不然服务器收到的可能就是HWeolrllod(注意是穿插着发过去了,但是顺序还是不会乱)。这样服务器就懵b了。
接上面的问题,能否同时发送Hello和World两个单词能,当然也是可以的,可以将数据拆成包,给每个包打上标签。发的时候是这样的①H ②W ①e ②o ①l ②r ①l ②l ①o ②d。这样到了服务器,服务器根据标签把两个单词区分开来。实际的发送效果如下图:

HTTP 性能优化的__关键并不在于高带宽,而是低延迟__。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
HTTP/2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。
总结下:多路复用技术:单连接多资源的方式,减少服务端的链接压力,内存占用更少,连接吞吐量更大;由于减少TCP 慢启动时间,提高传输的速度
3.3 首部压缩
为什么要压缩?在 HTTP/1 中,HTTP 请求和响应都是由「状态行、请求 / 响应头部、消息主体」三部分组成。一般而言,消息主体都会经过 gzip 压缩,或者本身传输的就是压缩过后的二进制文件(例如图片、音频),但状态行和头部却没有经过任何压缩,直接以纯文本传输。
随着 Web 功能越来越复杂,每个页面产生的请求数也越来越多,导致消耗在头部的流量越来越多,尤其是每次都要传输 UserAgent、Cookie 这类不会频繁变动的内容,完全是一种浪费。
我们再用通俗的语言解释下,压缩的原理。头部压缩需要在支持 HTTP/2 的浏览器和服务端之间:
- 维护一份相同的静态字典(Static Table),包含常见的头部名称,以及特别常见的头部名称与值的组合;
- 维护一份相同的动态字典(Dynamic Table),可以动态的添加内容;
- 支持基于静态哈夫曼码表的哈夫曼编码(Huffman Coding);
静态字典的作用有两个:
- 对于完全匹配的头部键值对,例如 “:method :GET”,可以直接使用一个字符表示;
- 对于头部名称可以匹配的键值对,例如 “cookie :xxxxxxx”,可以将名称使用一个字符表示。
HTTP/2 中的静态字典如下(以下只截取了部分):
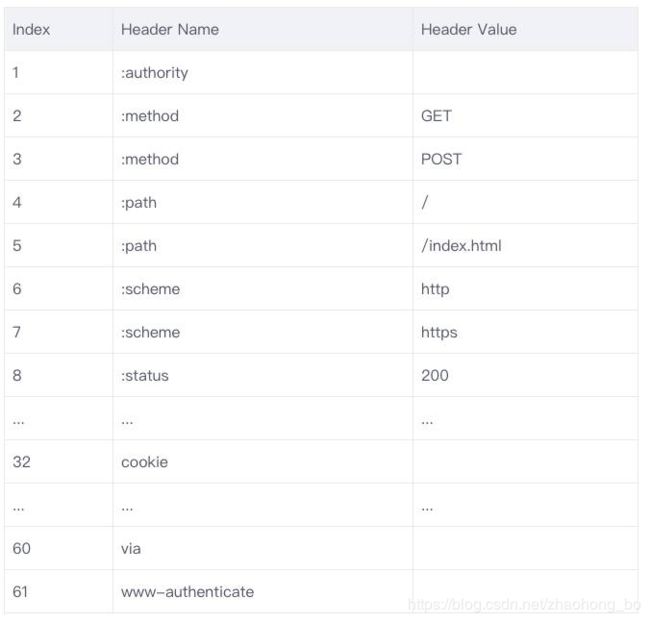
同时,浏览器和服务端都可以向动态字典中添加键值对,之后这个键值对就可以使用一个字符表示了。需要注意的是,动态字典上下文有关,需要为每个 HTTP/2 连接维护不同的字典。在传输过程中使用,使用字符代替键值对大大减少传输的数据量。
3.4 HTTP2支持服务器推送
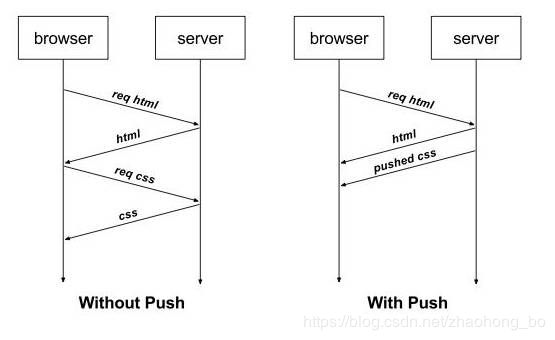
服务端推送是一种在客户端请求之前发送数据的机制。当代网页使用了许多资源:HTML、样式表、脚本、图片等等。在HTTP/1.x中这些资源每一个都必须明确地请求。这可能是一个很慢的过程。浏览器从获取HTML开始,然后在它解析和评估页面的时候,增量地获取更多的资源。因为服务器必须等待浏览器做每一个请求,网络经常是空闲的和未充分使用的。
为了改善延迟,HTTP/2引入了server push,它允许服务端推送资源给浏览器,在浏览器明确地请求之前。一个服务器经常知道一个页面需要很多附加资源,在它响应浏览器第一个请求的时候,可以开始推送这些资源。这允许服务端去完全充分地利用一个可能空闲的网络,改善页面加载时间。
3.5HTTP/2采用二进制格式而非文本格式
见 3.1 二进制分帧
参考:https://www.hollischuang.com/archives/2066