节省3500万的背后,运维如何兼顾成本与效率?
讲师介绍
籍鑫璞
奇虎360
智能运维项目技术负责人
360机器学习工程师,2016年加入360后一直从事与智能运维相关的工作,致力于用AI手段解决运维场景下的各种疑难杂症。
从运维成本和效率两方面发力,以达到节省资源、提高效率的目的。
今天我们要分享的是近几年我们在AIOps(智能运维)领域的探索和实践经验。
下面是本次分享的摘要:
-
背景介绍
-
360对AIOps的思考
-
AIOps的实践方案
-
经验和总结
一、背景介绍
随着互联网的软硬件呈现爆发性的增长,新的架构层出不穷,运维人员需要做到7*24小时的职守来保证系统的可靠性和稳定性。但这明显是不可能的。
那么面对这种空前的压力,有没有一种“机器大脑”能够减少甚至代替运维人员去做一些事情,极大地减少他们的工作量,提高运维的效率?又该如何得到这种“机器大脑”呢?
很多运维场景都可以总结成一些规则化的东西,可以经过提炼总结生成人工经验库。除了人工经验以外,是否可以通过AI算法对历史数据进行分析,得到一些由机器生成的规则?
答案当然是可以的。如果能将AI算法+人工经验应用到Ops中,代替一部分的人工决策,这样将推动运维从普通的自动化阶段到智能化阶段迈进。
从今年开始,很多公司在AIOps领域进行了一些尝试。我们公司的AIOps也经历了从最开始的标准化到后来的精细化、数据化运维的前期铺垫,在2018年,AIOps项目组正式组建,经过近一年的发展,已经在很多单点应用方面取得比较好的效果,并争取在今年年底,能够实现一些场景的闭环。

二、360对AIOps的思考
大家熟悉的AIOps场景有很多,诸如异常检测、根因分析、故障自愈、容量预测等方面。根据平台的实际场景和业界AIOps的实践经验,我们将AIOps划分为三个场景:成本、效率和稳定性。
针对成本来说,利用AI算法节省资源、智能调度、提高资源利用率的手段来节省资源;针对效率方面来说,利用AI算法主动发现问题、分析问题和解决问题,真正节省人力,提高效率。

那如何开展AIOps呢?我们认为AIOps需要开展需要下面三种人员:运维人员、运维开发、机器学习工程师。三者缺一不可,否则项目就会半途而废。

上面介绍了我们对AIOps的理解,下面就是纯干货出场了,我们将分两个大方向五个具体项目来介绍AIOps最佳实践经验。
三、AIOps实践方案
1、基础
数据积累
所谓“巧妇难为无米之炊”,在启动AIOps之前,需要准备很多数据,包括机器维度的基础数据、网络数据、日志数据、甚至进程数据等。我们有专门的大数据工程师历时两年多对数据进行收集,为后面的数据分析、机器学习模型打下坚实的基础。
下面是我们前后收集的数据总结:

容量预估
有了历史数据,我们就可以对数据进行一些分析。
首先介绍一种场景——容量预估。对重要监控项的预测,能够使我们及时了解指标的走势,为后面的决策提供了科学的依据。
监控项的样本就是时间序列,通过分析监控项的序列,得到未来一段时间的预测值。根据波动剧烈程度,监控项可以分为波动不太剧烈和剧烈的;根据周期性,可以分为具有周期性和不具有周期性等等,当然还有很多划分的标准。可见,不同时间的序列,我们需要使用不同的模型去预测。
在对时间序列进行预测的过程中,我们先后使用了下面几种模型,从中总结出了一些经验:
很多时间序列具有周期性,我们还自研了一个周期性检测的模型,能够比较好的判断一个序列是否具有周期性。在周期性检测的基础上,进一步跟进序列的周期性特征,来预测不同的时间序列。
对于预测模型,前人已经总结了很多种,我们在项目中使用了下面一些模型,你可以根据时间开销和准确度来选择自己的模型。以上所有的预测方法将在近期进行开源,还希望大家持续关注:

主机分类
在实际的项目中,我们经常会遇到分类任务,比如根据主机监控项的特征,需要用模型判断出该机器是否为空闲机器;再比如,我们会根据监控项的特征,来判断该机器属于的类型(CPU、磁盘、内存密集型)。
机器学习中有很多分类算法,比如SVM、决策树、分类树等都可以完成分类任务。我们只需要做一些预处理以及特征工程等方面的工作后,就可以使用Python中现成的分类模型,在此就不详细介绍。
2、项目
有了容量预估和主机分类的基础模块后,我们在成本方面先后做了资源回收、智能调度系统两个项目,并取得了比较好的效果。
资源回收
资源回收,就是及时发现比较空闲的机器,通知业务进行回收,以达到提高资源利用率的目的。
我们的资源回收系统分为三块:容量预估、主机分类以及通知模块。容量预估模型是对五个比较重要的指标(CPU使用率、内存使用率、网卡流量、磁盘使用率以及状态连接数)进行预测以及定量分析后,生成了五个特征。接下来使用分类器来对五个特征进行分类后,得到空闲的机器列表,最后将空闲机器通知给相应的业务负责人。
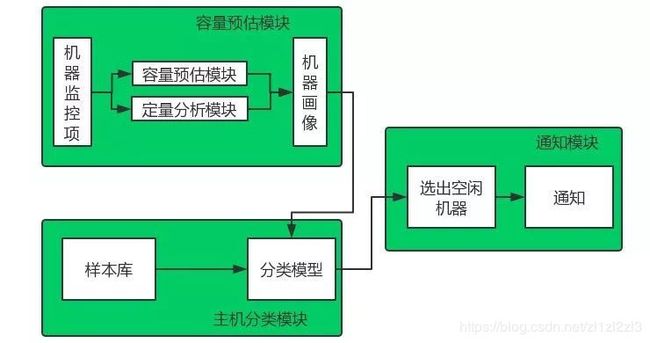
在AIOps中,经常会遇到负样本不足的问题,一个原因是异常的场景比较少,另一个原因是用户标注的成本比较高。
在主机分类的过程中,我们使用了两种手段来生成样本,一种是人工标注,一种是用户标注,解决了负样本不足的问题。下面这幅图是我们在Q2季度时候资源回收取得的效果,目前看还不错:

MySQL智能调度系统
我们线上的MySQL机器存在严重的浪费问题,例如下面的场景:可以看到只要有一个指标是高负载的情况,这个机器将不可用。细想一下,如果一台机器内存比较高,但是并不代表这台机器不可用,我们可以将CPU使用率较高但内存使用率较低的实例调度到这台机器上,达到充分利用资源的目的。

为了将不同类型的机器和不同类型的实例进行合理搭配,需要将实例和机器进行分类。在该项目中,实例分类采用了BP神经网络,其中输入是7个重要的实例指标,输出是4个类别(低消耗、计算型、存储型、综合型)。
机器分类采用决策树模型,输入是5个机器指标,输出和实例的输出类型一样。样本全部采用人工标注的方式,生成了1000左右的样本。
有了分类好的机器和实例以后,就需要进行调度。在调度过程中,考虑了多种因素:
-
尽量保证迁移次数少
-
尽量少的避免切主
-
保证主库和大容量端口的稳定性
-
控制每台机器上主库的个数(不超过5个)和实例总个数
-
同一端口的实例不能出现在同一机器上
-
不调度黑名单机器
我们按照上面的原则对一个机房的实例进行测试,端口迁移的次数为45次,可能将30台高负载机器中的14台变为可用状态。
成本一直是我们今年努力的一个大方向。除了上面介绍的两个项目,我们还使用了分时计算的手段来进一步节省资源。今年的目标是能够为公司节省五千万的成本,目前已经节省三千五百万,还没有达到目标,需要继续努力。
上面介绍的是成本方面的工作,下面介绍效率方面的项目。
异常检测
异常检测是AIOps最常见的场景,算法也有很多,业界比较流行的比如普通的统计学习方法——3σ原则,它利用检测点偏移量来检测出异常。比如普通的回归方法,用曲线拟合方法来检测新的节点和拟合曲线的偏离程度,甚至有人将CNN和RNN模型应用到异常点的检测。
我们公司使用LVS比较多,为了应对流量突增和突减的情况,需要一个异常检测算法。
通过对LVS流量的时间序列图的分析,发现有的曲线有周期性,有的没有;有的毛刺比较多,有的比较平稳,所以需要有一个普适检测算法,能够处理各种复杂的场景。
现实场景中,负样本比较少,我们采用了无监督模型,除此之外,还借鉴投票机制来解决单纯的方法有时候具有偏差这样的问题。
在该项目中,我们采用了五种以上的检测算法,有统计学中同比环比的情况、曲线拟合算法以及周志华老师的隔离森林模型。通过这些模型来一起对一个时间序列进行检测。如果这些算法中有超过一半的算法认为该检测点为异常点,我们就认为这个点为异常点。

跟踪了将近半年线上LVS流量数据,检测算法的准确率高于95%,效果还是不错的。
报警收敛
为了保证系统的可靠性,运维人员经常设置很多监控项来及时了解系统的状况。如果某个监控项超过设置的阈值,则系统中某些指标出现问题,需要运维人员进行处理。这样不经过过滤,直接将所有的报警全部发出来的方式,很容易增加运维人员的压力,而且随着报警数的增多,也很容易造成他们的疲劳感,并不能达到好的报警效果。
我们对历史报警进行分析,发现其中有很多规律。如果我们利用算法分析出这些报警项之间的关系,再加上人工经验,将很大程度减少报警的数目。
人工经验就不用说了,下面介绍一下如何通过算法去分析出报警项之间的潜在关系。
我们采用机器学习中关联分析常用的算法Apriori来分析历史报警,该模型利用频繁项集分析出A→B这种关系。将这种规则应用到报警中,如果A报警发出,则B报警就不需要发出,这样就能够成倍减少报警次数。下图是我们对过去30天的报警数据分析,得到20+的关联规则:

我们线上维护着一个规则库,这个规则库来源于两部分:算法分析规则、人工总结规则。在利用这些规则同时,我们还结合了业务的评级来对业务报警进行一定程度的合并处理。跟踪了半年的报警,采用这个规则库能够减少60%-80%的报警。
报警事件的根因分析
上节介绍了减少报警的方式,但是现实中的报警是不可避免的。在发生报警以后,如何快速定位具体问题就成为关键的环节。那如何通过模型去定位问题呢?
通过统计分析,我们线上发生最多的是这六大类的报警,这些报警分别是:
-
主机存活(host.alive);
-
磁盘空间使用率(df.bytes.used.percent);
-
磁盘分区只读(sys.disk.rw);
-
CPU使用率(cpu.idle);
-
内存使用率(mem.swapused.percent);
-
磁盘io操作百分比(disk.io.util)。
在发生报警后,运维人员需要登陆到机器或者监控系统去看出现问题的时间段内是哪些监控项或者进程出现问题。这样繁重且具有很强规则性的场景特别适合模型去搞定。本节将介绍一种模型,能够帮助运维人员缩小报警排查范围,快速定位到问题。
该项目中要分析两个维度数据:
-
一个是事件维度,关注的是六大类报警事件;
-
一个是指标维度,关注机器维度的监控项(大约有200左右个监控项)。
那如何在事件发生后,找到跟它相关的指标呢?实现的方法如下:
1)针对每个事件,使用在2014年SIGKDD会议上发表的论文《Correlating Events with Time Series for Incident Diagnosis》中提到的方法,看哪些指标跟这个事件发生有关系。这样的做目的是对指标进行初筛,达到降维的目的。
2)针对第一步选出来的指标,求出这些指标的信息增益比,选择前k个(我们取得值是5)特征作为最后的影响指标;
3)最后使用xgboost对影响指标进行分类,验证效果。
下图是我们对这六大类报警的分析结果,取报警事件最相关的Top5指标,取得比较好的准确率:

比如下一次发生“host.alive”报警,就有很大概率是 'cpu.idle' 、 'net.if.total.bits.sum' 、 'mem.memused.percent' 、 'mem.swapused.percent' 和 'ss.closed' 导致的,这样就能够减少排查问题的时间。
四、经验和总结
通过将近一年的努力,我们已经在一些单点的应用方面取得比较好的效果。下面是接下来要做的工作前瞻:
-
报警进程级别的定位;
-
开源组件(容量预估、异常检测以及报警事件的关联分析);
-
运维聊天机器人。
接下来的工作中,我们将结合一些具体的场景将上面介绍的一些单点串联起来,真正能够从发现异常问题、分析问题到最后的解决问题,形成真正意义上的闭环。
以上就是我此次分享的全部内容,感谢大家的参与,谢谢!
直播回放
https://m.qlchat.com/topic/details?topicId=2000002350036659&tracePage=liveCenter