JAVA1.7+Hadoop 2.7.3+Spark 2.1.0一主多从集群搭建
文章目录
- 0 集群信息及基本初始化
- 0.1 集群初始化
- 0.2 集群信息
- 1 Hadoop 2.7.3环境搭建
- 1.1 下载JDK1.7、Hadoop2.7.3、Spark2.1.0包
- 1.2 解压JDK安装包
- 1.3 配置java环境(hadoop Master和Slave上都要做这一步操作)
- 1.4 检查Java环境是否配置成功
- 1.5 搭建hadoop 2.7.3环境(Hadoop Master中进行)
- 1.6 将Hadoop Master配置的hadoop文件夹全部复制到Slave中
- 1.7 配置Master和Slvae机器中的hadoop环境变量。
- 1.8 使/etc/profile配置生效
- 1.9 在Master上执行hadoop的格式化
- 1.10 启动Hadoop
- 1.11 验证hadoop的启动情况
- 2 Spark环境搭建
- 2.1 安装scala环境
- 2.2 在Slave上也执行与Master上相同的操作,安装scala环境
- 2.3 在Master上安装Spark
- 2.4 在Master中Spark文件拷贝到Slave中
- 2.5 在Slave上配置Spark
- 2.6 在Master中启动Spark集群并验证
- 3 Spark和Hadoop集群的启动与停止
- 3.1 Hadoop集群开启与停止
- 3.2 Spark集群开启与停止
- 4 Spark和Hadoop集群测试
- 4.1 测试Hadoop集群
- 4.2 测试Spark集群
0 集群信息及基本初始化
0.1 集群初始化
这一步主要是给机器生成SSH Key以及机器别名等配置,具体初始化操作请参考此文章的2.1节集群初始化设置。
0.2 集群信息
Hadoop/Spark Master为node8,其IP地址为:192.168.1.113。
Hadoop/Spark Slave为node2~node7和node8,即该集群有1主7从。
1 Hadoop 2.7.3环境搭建
1.1 下载JDK1.7、Hadoop2.7.3、Spark2.1.0包
mkdir homework
cd homework
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3-src.tar.gz
wget http://distfiles.macports.org/scala2.10/scala-2.10.4.tgz
wget https://archive.apache.org/dist/spark/spark-2.1.0/spark-2.1.0-bin-hadoop2.7.tgz
注:JDK1.7需要从官方网站下载,并且可能需要账号登录,可以使用临时邮箱,临时邮箱网址:https://linshiyouxiang.net/,JDK 1.6~1.8下载网址。
1.2 解压JDK安装包
cd ~/homework
tar -xvf jdk-7u80-linux-x64.tar.gz
1.3 配置java环境(hadoop Master和Slave上都要做这一步操作)
vim ~/.bashrc #在该文件默认添加如下3行内容:
export JAVA_HOME=/home/k8s/homework/jdk1.7.0_80
export CLASSPATH=.:${JAVA_HOME}/lib:${JAVA_HOME}/jre/lib
export PATH=${JAVA_HOME}/bin:${JAVA_HOME}/jre/bin:$PATH
#注意:这并不是全局的JAVA配置,如果需要全局JAVA配置,请将上面3行内容添加到/etc/profile文件末尾
source ~/.bashrc #让配置生效
1.4 检查Java环境是否配置成功
java -version #配置成功则会输出:java version "1.7.0_80"
1.5 搭建hadoop 2.7.3环境(Hadoop Master中进行)
#1.5.1 解压
cd ~/homework && tar -xvf hadoop-2.7.3.tar.gz
#1.5.2创建相关目录
cd hadoop-2.7.3 && mkdir tmp && mkdir logs && mkdir hdfs && mkdir hdfs/data && mkdir hdfs/name
#1.5.3修改hadoop配置
cd ~/homework/hadoop-2.7.3/etc/hadoop
vim hadoop-env.sh #找到该文件中的export JAVA_HOME一行,将其修改为export JAVA_HOME=/home/k8s/homework/jdk1.7.0_80
vim yarn-env.sh #找到该文件中的export JAVA_HOME一行,将其修改为export JAVA_HOME=/home/k8s/homework/jdk1.7.0_80
vim slaves #删除localhost,将node2~node7和node9添加到该文件中
vim core-site.xml #找到该文件中的1.6 将Hadoop Master配置的hadoop文件夹全部复制到Slave中
for i in `seq 2 7` ;do
ssh node$i mkdir /home/k8s/homework
scp -r ~/homework/hadoop-2.7.3 node$i:/home/k8s/homework/
done
ssh node9 mkdir /home/k8s/homework
scp -r ~/homework/hadoop-2.7.3 node9:/home/k8s/homework/
1.7 配置Master和Slvae机器中的hadoop环境变量。
在/etc/profile文件末尾添加如下6行内容:
export HADOOP_HOME=/home/k8s/homework/hadoop-2.7.3
export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
1.8 使/etc/profile配置生效
source /etc/profile
1.9 在Master上执行hadoop的格式化
可能需要使用service iptables stop关闭防火墙,但是在我们的机器上不关闭也没问题。
cd ~/homework/hadoop-2.7.3/bin
./hdfs namenode -format
1.10 启动Hadoop
在Master上执行如下操作:
cd ~/homework/hadoop-2.7.3/sbin
./start-all.sh
1.11 验证hadoop的启动情况
#11.1 在浏览器输入http:192.168.1.113:50070查看结果
#11.2 在Master中输入jps命令,如果结果如下图1,则表示成功
#11.3 在Slave中输入jps命令,如果结果如下图2,则表示成功
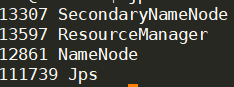
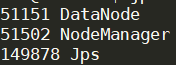
2 Spark环境搭建
2.1 安装scala环境
cd ~/homework
tar -xvf scala-2.10.4.tgz
sudo vim /etc/profile #在文件末尾添加如下内容:
export SCALA_HOME=/home/k8s/homework/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin
#vim /etc/profile结束
source /etc/profile #使/etc/profile配置生效
scala -version #查看安装结果,如果出现scala code runner version 2.10.4表示scala安装成功
2.2 在Slave上也执行与Master上相同的操作,安装scala环境
2.3 在Master上安装Spark
cd ~/homework
#开始配置Spark
tar -xvf spark-2.1.0-bin-hadoop2.7.tgz
sudo vim /etc/profile #在文件末尾添加如下内容:
export SPARK_HOME=/home/k8s/homework/spark-2.1.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
#vim /etc/profile结束
source /etc/profile
cd ~/homework/spark-2.1.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh #在该文件末尾添加如下6行内容:
export SCALA_HOME=/home/k8s/homework/scala-2.10.4
export JAVA_HOME=/home/k8s//homework/jdk1.7.0_80
export SPARK_MASTER_IP=192.168.1.113
export SPARK_WORKER_MEMORY=1G
export HADOOP_CONF_DIR=/home/k8s/homework/hadoop-2.7.3/etc/hadoop
export LD_LIBRARY_PATH=/home/k8s/homework/hadoop-2.7.3/lib/native
#vim spark-env.sh结束,其中SPARK_MASTER_IP指的是要作为Spark集群Master的机器IP,可以使用ifconfig查看
cp slaves.template slaves
vim slaves #将文件中的localhost删除,同时添加node2~node7和node9
2.4 在Master中Spark文件拷贝到Slave中
for i in `seq 2 7` ; do
scp -r ~/homework/spark-2.1.0-bin-hadoop2.7 node$i:/home/k8s/homework/
done
scp -r ~/homework/spark-2.1.0-bin-hadoop2.7 node9:/home/k8s/homework/
2.5 在Slave上配置Spark
#配置slave中的spark环境,需要在slave中执行如下指令:
sudo vim /etc/profile #在该文件末尾添加如下2行内容:
export SPARK_HOME=/home/k8s/homework/spark-2.1.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
#vim /etc/profile结束
2.6 在Master中启动Spark集群并验证
cd /home/k8s/homework/spark-2.1.0-bin-hadoop2.7/sbin
./start-all.sh #指令执行的输出如图3
jps #如果jps后Master机器中新增Master则表示spark master启动成功,出现图4结果即为成功
#2.3.5 验证Spark Slave结果,在slave中执行如下指令:
jps #如果出现Slave则表示Spark集群配置成功,即Slave中的最终结果如图5

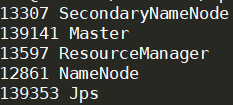

3 Spark和Hadoop集群的启动与停止
3.1 Hadoop集群开启与停止
#1.hadoop集群开启
ssh node8 #进入master
cd ~/homework/hadoop-2.7.3/sbin
./start-all.sh
#2.hadoop集群停止
ssh node8 #进入master
cd ~/homework/hadoop-2.7.3/sbin
./stop-dfs.sh && ./stop-yarn.sh #stop-all.sh是过时的,不过也可以停止集群
3.2 Spark集群开启与停止
#1.spark集群开启
ssh node8 #进入master
cd ~/homework/spark-2.1.0-bin-hadoop2.7/sbin
./start-all.sh
#2.spark集群停止
ssh node8 #进入master
cd ~/homework/spark-2.1.0-bin-hadoop2.7/sbin
./stop-all.sh
4 Spark和Hadoop集群测试
4.1 测试Hadoop集群
#1 建立一个输入文件
vim wordcount.txt #其内容为如下3行:
Hello hadoop
hello spark
hello bigdata
#2 执行如下指令:
hadoop fs -mkdir -p /Hadoop/Input
hadoop fs -put wordcount.txt /Hadoop/Input
hadoop jar /home/k8s/homework/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /Hadoop/Input /Hadoop/Output #如果提示有Output文件夹,可以执行hadoop fs -rf -r /Hadoop/Output进行删除
#3 上述指令执行结束后执行如下指令:
hadoop fs -cat /Hadoop/Output/* #如果可以看到图6的输出表示hadoop成功
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fKMsD1DN-1592983129035)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20200624114404531.png)]
4.2 测试Spark集群
#1 执行如下脚本:
spark-shell #进入图7界面
#2执行如下指令:
val file=sc.textFile("hdfs://node8:9090/Hadoop/Input/wordcount.txt")
val rdd = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_) #注意从var 到(_+_)这是一条完整的指令
rdd.collect()
rdd.foreach(println)
#注:其中的node8:9090是在hadoop-2.7.3/etc/hadoop/core-site.xml文件中配置的
#3 输出的正确结果如图7所示,至此spark集群搭建完成

相关参考:
- 完全分布式的hadoop集群搭建-hadoop2.7.3
- spark2.1.0完全分布式集群搭建-hadoop2.7.3
- spark教程:Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程