1.背景
监控redis的运行实时情况和历史,了解redis的运行情况
2.目的
通过此监控,可以实时监控redis服务的运行状态;并通过历史数据,了解redis的走势。采取相应的操作,达到监控的目的。
3.监控环境搭建
(3.1)修改主机名
(3.1.1)在/etc/hosts
192.168.165.130 nameNode #添加ip和主机名
(3.1.2) 在/etc/sysconfig/network
NETWORKING=yesHOSTNAME=nameNode #主机名再重启机器
(3.2)安装jdk-7u79-linux-x64.rpm
rpm -ivh jdk-7u79-linux-x64.rpm
修改/etc/profile文件
JAVA_HOME=/usr/java/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH

通过命令java -version出现,说明Java配置完成
(3.3)hadoop伪分布式的配置安装
tar zxvf hadoop-2.5.1-x64.tar.gz
mv hadoop-2.5.1 hadoop
mv hadoop /usr/
(3.3.1)配置HADOOP_HOME
在etc/profile里面
JAVA_HOME=/usr/java/jdk1.7.0_79
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
(3.3.2)在 etc/hadoop/core-site.xml
hadoop.tmp.dir
/usr/hadoop/tmp
A base for other temporary directories.
fs.defaultFS
hdfs://nameNode:9000
(3.3.3)在etc/hadoop/hdfs-site.xml
dfs.namenode.name.dir
/usr/hadoop/hdfs/name
dfs.datanode.data.dir
/usr/hadoop/hdfs/data
dfs.replication
1
(3.3.4)在etc/hadoop/mapred-site.xml
mapreduce.framework.name
Yarn
(3.3.5)在etc/hadoop/yarn-site.xml
Yarn.nodemanager.aux-services
mapreduce.shuffle
The address of the applications manager interface in the RM.
Yarn.resourcemanager.address
192.168.165.130:18040
The address of the scheduler interface.
Yarn.resourcemanager.scheduler.address
192.168.165.130:18030
The address of the RM web application.
Yarn.resourcemanager.webapp.address
192.168.165.130:18088
The address of the resource tracker interface.
Yarn.resourcemanager.resource-tracker.address
192.168.165.130:8025
(3.3.6)/etc/hadoop/hadoop-env.sh
中修改JAVA_HOME的目录地址
export JAVA_HOME=/usr/java/jdk1.7.0_79
3.4 hbase的安装
(3.4.1) 在/usr/local/hc下执行
tar zxvf hbase-1.0.1.1-bin.tar.gzmv hbase-1.0.1.1 hbase
mv hbase /usr/
(3.4.2)修改/hbase/conf/hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_79(自己的jdk安装路径)
export HBASE_CLASSPATH=/usr/hadoop/conf设置到Hadoop的conf目录是用来引导Hbase找到Hadoop
export HBASE_MANAGES_ZK=true
(3.4.3)修改/hbase/conf/hbase-site.sh
hbase.cluster.distributed
true
hbase.rootdir
hdfs://nameNode:9000/hbase
dfs.replication
1
3.5 启动hadoop和hbase
(3.5.1)首次启动需要格式化namenode。
bin/hadoop namenode -format
(3.5.2)启动hadoop
./start-dfs.sh
./start-yarn.sh
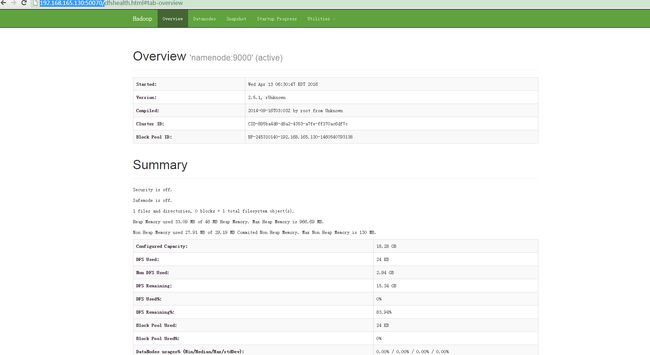
可通过浏览器浏览:http://192.168.165.130:50070/ 则出现如下界面,说明启动成功;
(3.5.3)启动hbase
在/usr/hbase/bin
./start-hbase.sh
可通过./hbase shell进入hbase控制台,执行控制台命令操作hbase
*在hbase升级到1.0.0版本后,默认端口做了改动。其中16020端口是hmaster服务和hregionserver服务各自使用的默认端口,导致端口冲突。
该问题可以通过 使用单独的regionserver启动脚本程序启动regionserver来规避。
使用方法:
bin/local-regionservers.sh start 1
关闭hbase 用./stop-hbase.sh
3.6 安装opendTSDB
(3.6.1) 什么是opendTSDB
OpenTSDB 用HBase存储所有的时序(无须采样)来构建一个 分布式、可伸缩的时间序列数据库 。它支持秒级数据采集所有metrics,支持永久存储,可以做容量规划,并很容易的接入到现有的报警系统里。OpenTSDB可以从大规模的集群(包括集群中的网络设备、操作系统、应用程序)中获取相应的metrics并进行存储、索引以及服务,从而使得这些数据更容易让人理解,如web化、图形化等。
对于运维工程师而言,OpenTSDB可以获取基础设施和服务的实时状态信息,展示集群的各种软硬件错误,性能变化以及性能瓶颈。对于管理者而言,OpenTSDB可以衡量系统的SLA,理解复杂系统间的相互作用,展示资源消耗情况。集群的整体作业情况,可以用以辅助预算和集群资源协调。对于开发者而言,OpenTSDB可以展示集群的主要性能瓶颈,经常出现的错误,从而可以着力重点解决重要问题。
(3.6.2)基本概念
Metric 。一个可测量的单位的标称。 metric 不包括一个数值或一个时间,其仅仅是一个标签,包含数值和时间的叫 datapoints ,metric是用逗号连接的不允许有空格,例如:
hours.worked
webserver.downloads
accumulation.snow
Tags 。一个metric应该描述什么东西被测量,在OpenTSDB中,其不应该定义的太简单。通常,更好的做法是用Tags来描述具有相同维度的metric。Tags由tagk和tagv组成,前者表示一个分组,后者表示一个特定的项。
Time Series 。一个metric的带有多个tag的data point集合。
Timestamp 。一个绝对时间,用来描述一个数值或者一个给定的metric是在什么时候定义的。
Value 。一个Value表示一个metric的实际数值。
UID 。在OpenTSDB中,每一个metric、tagk或者tagv在创建的时候被分配一个唯一标识叫做UID,他们组合在一起可以创建一个序列的UID或者 TSUID 。在OpenTSDB的存储中,对于每一个metric、tagk或者tagv都存在从0开始的计数器,每来一个新的metric、tagk或者tagv,对应的计数器就会加1。当data point写到TSD时,UID是自动分配的。你也可以手动分配UID,前提是 auto metric 被设置为true。默认地,UID被编码为3Bytes,每一种UID类型最多可以有16,777,215个UID。你也可以修改源代码改为4Bytes。UID的展示有几种方式,最常见的方式是通过http api访问时,3 bytes的UID被编码为16进制的字符串。
*注意事项
a. 减少metric, tag name和tag value的数量。
b. 为每个metric使用同类的tag name
c. 考虑系统常用的查询方式,选择合适的时间序列metric和tag
d. 每个metric的tag数量维持在5个以内,最多不超过8个。
(3.6.3)opendTSDB下载安装
OpenTSDB依赖jdk和Gnuplot,Gnuplot需要提前安装,版本要求为最小4.2,最大4.4,执行以下命令安装即可:
yum install automakeyum install gnuplot autoconf
接下来下载和安装openTSDB
git clone git://github.com/OpenTSDB/opentsdb.git
cd opentsdb
./build.sh
#TSDB通讯的端口
tsd.network.port = 4242
#数据保存到保存到HBase表下
tsd.storage.hbase.data_table = tsdb
#ZooKeeper Quorum
tsd.storage.hbase.zk_quorum = localhost
(3.6.4)初始化建表
建表文件opentsdb/src/create_table.sh,如果这是你第一次用你的HBase实例去运行OpenTSDB,你首先需要去创建必须的HBase表:
进入opentsdb文件夹
env COMPRESSION=none HBASE_HOME=/usr/hbase ./src/create_table.sh
tsdtmp=${TMPDIR-'/tmp'}/tsd # For best performance, make suremkdir -p "$tsdtmp" # your temporary directory uses tmpfs
./build/tsdb tsd --port=4242 --staticroot=build/staticroot --cachedir="$tsdtmp"
此时你能访问TSD的网络接口通过:127.0.0.1:4242 (假设这跑在你的主机上).
(3.6.5)创建你的第一个指标
首先创建metrics,命令会输出它的UID。
tsdb mkmetric 标签名称1 标签名称2
3.7安装grafana
(3.7.1)下载grafana-2.6.0-1.x86_64.rpm
地址为:https://grafanarel.s3.amazonaws.com/builds/grafana-2.6.0-1.x86_64.rpm
service grafana-server start
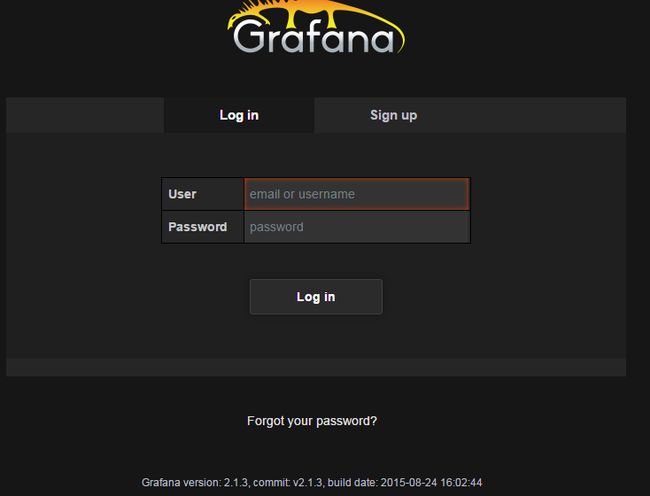
启动后,在浏览器输入http://localhost:3000,默认端口号是3000,默认用户名是admin,密码是admin。点击登录。
(3.7.2)界面介绍
主页面(下图)主要分为两部分,左侧是按钮界面,右侧是动态显示图表界面。其中dashboards是所有的数据显示表盘。每一个表盘里面可以有很多动态图表。

Data Sources是grafana连接的数据源管理界面,稍后再介绍。
(3.7.3)显示数据
要显示数据,第一步得有数据,如果已经有了数据库(grafana原生支持influxDB,Graphite,OpenTSDB)可以直接设置数据源,否则需要自行安装数据库。我们使用OpenTSDB作为数据源。
(3.7.4)配置数据源
点击主页面左侧的Data Source 进入数据源配置界面。点击Add new,进入数据源编辑界面。
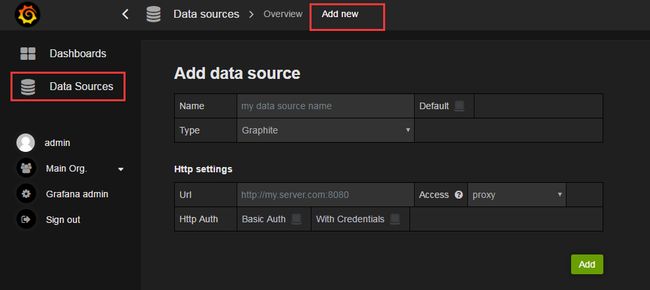
(添加数据源界面)
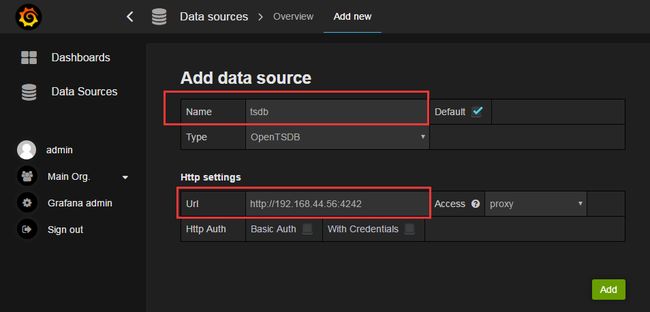
(编辑数据源界面)
Edit data source
Name:自定义数据源的名称,在其他地方使用这个引用。
Default:默认数据源配置。多个数据源的默认选择。
Type:选择数据源的类型,可以根据自己安装的数据库的版本和类型选择,他的数据库自己选择。
Http settings
Url:数据库的连接地址。格式是:http://IP:Port。IP是数据库暴露出来的IP地址, OpenTSDB默认的端口号是4242

1. 现在数据源已经配置成功,现在来创建表盘显示数据。
点击Dashboards-Home-New,出现下面的界面。点击右侧的设置按钮---settings,进入该dashboard的设置界面。
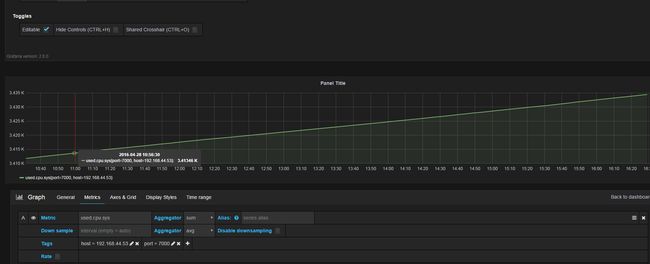
配置要查询指标mkmetric ,tags过滤条件过滤想要的数据。