darknet中的图像缩放算法(双线性内插值法)
一:双线性内插值法
设原图像的height,width,channels分别为h,w,c
目标图像(resize结果)的height,width,channels分别为h_r,w_r,c_r
则长宽的调整比例分别为:![]() ,
,![]()
那么目标图像中的像素点(a, b, c),对应原图像的像素点![]() ,要取整。
,要取整。
这是k近邻内插值的方法。
而双线性内插值,对于缩放后的像素点不再是简单的取整。
设![]() ,即对应原图像的像素点为
,即对应原图像的像素点为![]() ,因为通道数不缩放,所以下文都不再把通道数写出来,(2.4,3.6)该像素点其实对应在点(2,3),(2,4),(3,3),(3,4)之间,所以缩放后的点(2.4,3.6)应该由这四个点共同决定,见下图:
,因为通道数不缩放,所以下文都不再把通道数写出来,(2.4,3.6)该像素点其实对应在点(2,3),(2,4),(3,3),(3,4)之间,所以缩放后的点(2.4,3.6)应该由这四个点共同决定,见下图:
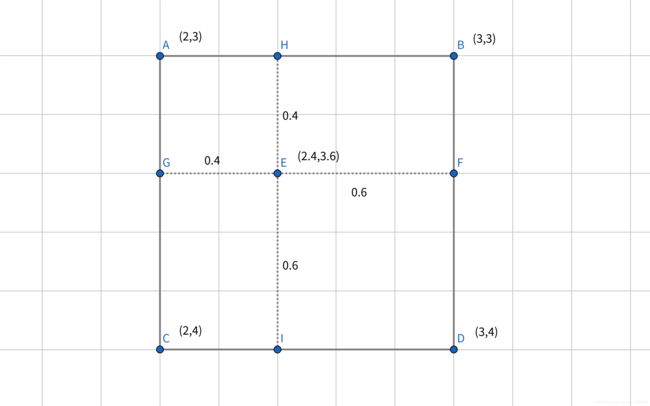
Pixel(E)=0.4*0.4*Pixel(A)+0.4*0.6*Pixel(B)+0.4*0.6*Pixel(C)+0.6*0.6*Pixel(D)
由上图可以清晰的看出双线性内插值法将对应原图像的像素点的小数部分视为一种占比关系,我们再梳理一下:
设缩放比例为scale_h(height的缩放比例),scale_w(width的缩放比例),缩放后的图像中像素点(x,y),对应的原始图像中的像素点为(x*scale_width,y*scale_height),取他的小数部分为(a,b),取他的整数为(c,d),则其像素值受到这四个像素点的像素值决定A(c,d),B(c+1,d),C(c,d+1),D(c+1,d+1)
则像素点Pixel(x,y)=Pixel(A)*a*(1-b)+Pixel(B)*(1-a)*(1-b)+Pixel(C)*a*b+Pixel(D)*(1-a)*b
这就是双线性内插值法的计算过程。
二:darknet框架中的实现
相关算法在src/image.c中,resize_image函数,代码如下:
image resize_image(image im, int w, int h)
{
//目标大小608*608
image resized = make_image(w, h, im.c);
image part = make_image(w, im.h, im.c);
int r, c, k;
float w_scale = (float)(im.w - 1) / (w - 1);
float h_scale = (float)(im.h - 1) / (h - 1);
for(k = 0; k < im.c; ++k){
for(r = 0; r < im.h; ++r){
for(c = 0; c < w; ++c){
float val = 0;
if(c == w-1 || im.w == 1){
val = get_pixel(im, im.w-1, r, k);
} else {
float sx = c*w_scale;
int ix = (int) sx;
float dx = sx - ix;
val = (1 - dx) * get_pixel(im, ix, r, k) + dx * get_pixel(im, ix+1, r, k);
}
set_pixel(part, c, r, k, val);
}
}
}
for(k = 0; k < im.c; ++k){
for(r = 0; r < h; ++r){
float sy = r*h_scale;
int iy = (int) sy;
float dy = sy - iy;
for(c = 0; c < w; ++c){
float val = (1-dy) * get_pixel(part, c, iy, k);
set_pixel(resized, c, r, k, val);
}
if(r == h-1 || im.h == 1) continue;
for(c = 0; c < w; ++c){
float val = dy * get_pixel(part, c, iy+1, k);
add_pixel(resized, c, r, k, val);
}
}
}
free_image(part);
return resized;
}我现将darknet中的实现思想表述以下,再来分析代码。
再借用这附图:
上述在讲解双线性内插值时,是宽高同时进行缩放的,可以现进行宽缩放或高缩放。在计算过程中,就可以先求中间点H,I的像素值或点G,F的像素值
即Pixel(H)=Pixel(A)*0.4+Pixel(B)*0.6,Pixel(I)=Pixel(C)*0.4+Pixel(D)*0.6,Pixel(E)=Pixel(H)*0.4+Pixel(I)*0.6
或Pixel(G)=Pixel(A)*0.4+Pixel(C)*0.6,Pixel(F)=Pixel(B)*0.4+Pixel(D)*0.6,Pixel(E)=Pixel(G)*0.4+Pixel(F)*0.6
而darknet采用的是先对宽(width)进行缩放,再对高(height)进行缩放
现在来看代码:
首先来看缩放比例的计算:
float w_scale = (float)(im.w - 1) / (w - 1);
float h_scale = (float)(im.h - 1) / (h - 1);看到这里,小朋友你是不是有很多❓,为什么要减1啊?
在寻找对应原图像的像素点时,缩放后的图像中像素点(x,y),对应的原始图像中的像素点为(x*scale_width,y*scale_height),这个(x*scale_width,y*scale_height)是两个小数,我们对他向下和向上取整,获得那四个像素点,其中向上取整时,得到的那俩个像素点可能超出了图像的大小,那么对于这种点采取像素值取0的方式。那么对于缩放后的图像的最外侧的像素点,在计算其像素值时,一定会超出图像大小,那么就要取0值进行计算,这无端的在外圈像素引入了误差,从视觉效果来说,缩放后的图像会有一圈颜色偏暗(黑)的像素圈圈。
所以darknet不对最下端和最右端的像素进行缩放,所以实际进行缩放的图像大小为(im.w-1,im.h-1),那么对于最后一行和最后一列的像素值直接从原图像的对应位置直接取值,对应代码为:
if(c == w-1 || im.w == 1){
val = get_pixel(im, im.w-1, r, k);
}搞清楚这些后,整个过程就很明朗了,先对width进行缩放:
for(k = 0; k < im.c; ++k){
for(r = 0; r < im.h; ++r){
for(c = 0; c < w; ++c){
float val = 0;
if(c == w-1 || im.w == 1){
val = get_pixel(im, im.w-1, r, k);
} else {
float sx = c*w_scale;
int ix = (int) sx;
float dx = sx - ix;
val = (1 - dx) * get_pixel(im, ix, r, k) + dx * get_pixel(im, ix+1, r, k);
}
set_pixel(part, c, r, k, val);
}
}
}part用于存储width缩放的中间值
再对height进行缩放:
for(k = 0; k < im.c; ++k){
for(r = 0; r < h; ++r){
float sy = r*h_scale;
int iy = (int) sy;
float dy = sy - iy;
for(c = 0; c < w; ++c){
float val = (1-dy) * get_pixel(part, c, iy, k);
set_pixel(resized, c, r, k, val);
}
if(r == h-1 || im.h == 1) continue;
for(c = 0; c < w; ++c){
float val = dy * get_pixel(part, c, iy+1, k);
add_pixel(resized, c, r, k, val);
}
}
}由于darknet中图像保存为一维数组,所以要特别注意图像像素的索引,darknet中的图像是以行(height),列(width),通道(channel)进行展开为一维数组的。可以通过get_pixel函数来理解像素的索引。