Python爬虫入门学习笔记
Python爬虫技术
1. 爬虫技能:
- . 静态网页数据抓取(urllib/requests/BeautifulSoup/lxml)
- . 动态网页数据抓取(ajax/phantomjs/selenlum)
- . 爬虫框架(scrapy)
- . 补充知识:前端知识、数据库知识、文本处理知识
2. 爬虫环境配置
- 平台:Windows10
- Pycharm/Anaconda3 (Python3.5以上)
- MySQL数据库
- mongoDB数据库
- Navicat数据库客户端
3. 爬虫四步基本框架
- 请求 urllib/requests
- 解析 BeautifulSoup/lxml
- 提取 css选择器/xpath表达式/正则表达式
- 储存 csv/MySQL/mongoDB等
一、请求。
1.用urllib直接请求页面
from urllib.request import urlopen
url = "https://www.python.org/"
response = urlopen(url)
content = response.read()
#需要解码
content = content.decode('utf-8')
print(content)
直接用urlopen打开的方式太直白,有时我们需要委婉一点的请求:
import urllib.request
url = "https://www.python.org/"
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(response.geturl())
print(response.info())
#打印请求状态码
print(response.getcode())
print(type(response))
结果:
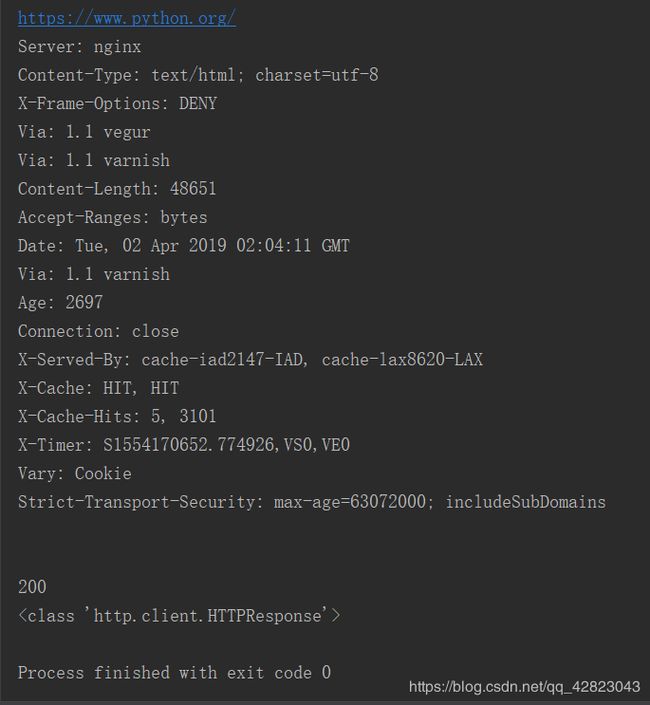
2.requests请求库
import requests
res = requests.get('http://www.python.org/')
print(res.status_code)
print(res.text)#纯文本
#print(res.content)#还有一些图片视频等
太直白多不好,我们还需要设置请求头headers:
import requests
url = 'http://www.python.org/'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3650.400 QQBrowser/10.4.3341.400'
}
res = requests.get(url,headers=headers)
print(res.text)
二、解析库
1.Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库。他能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方式。Beautiful Soup会帮你节省数小时甚至数天的工作时间。
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3650.400 QQBrowser/10.4.3341.400'
}
url = 'http://new.qq.com/'
Soup = BeautifulSoup(requests.get(url=url,headers=headers).text.encode('utf-8'),'lxml')
em = Soup.find_all('h3',attrs={'class':'bold'})
for i in em:
title = i.a.get_text()
link = i.a['href']
print({'标题':title,'连接':link})

2.解析库lxml
import requests
from lxml import etree
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3650.400 QQBrowser/10.4.3341.400'
}
url = 'http://www.people.com.cn/'
html = requests.get(url=url, headers=headers)
html.encoding='GBK'
con = etree.HTML(html.text)
title = con.xpath('//ul[@class="list14 top"]/li/a/text()')
link = con.xpath('//ul[@class="list14 top"]/li/a/@href')
for i in zip(title,link):
print({'标题':i[0],
'链接':i[1]})
如下图查看编码格式是GB2312,所以需要encoding=‘GBK’.
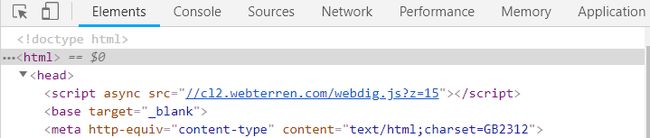
找到我们想要抓取的数据的地址:

结果显示:

三、提取
1.css选择器:select方法(在上述bs4代码里使用的)
2.xpath表达式(在上述lxml代码里使用的)
3.正则表达式(较全面也复杂)
四、数据的保存
1.CSV库的使用
关于 csv库的使用,我们从写和读两个方面来讲。csv库有四个主要的类 writer,DictWriter,reader,DictReader。
import csv
#待写入的数据
data_1 = ['Tom','Cody','Zack']
data_2 = ['Mike','Bill']
#创建并打开文件
with open('test_writer.csv','w',newline='',encoding='utf-8') as csvfile:
#获得writer对象 delimiter是分隔符 默认是“,”
writer = csv.writer(csvfile,delimiter=' ')
#调用 writer的 writerow方法将 data写入 test_writer.csv文件
writer.writerow(data_1)
writer.writerow(data_2)
结果:
Tom Cody Zack
Mike Bill
系列传送门:
Python爬虫入门学习实战项目(一)
Python爬虫入门学习实战项目(二)