数据库学习笔记:SQL语句+刷题+零碎知识点大集合
牛客刷题零碎知识点:
select * from tableName limit i,n
# tableName:'表名
# i:为查询结果的索引值(默认从0开始),当i=0时可省略i
# n:为查询结果返回的数量
# i与n之间使用英文逗号","隔开
# limit n 等同于 limit 0,n
-left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录 (以左表为主表)
-right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录(以右表为主表)
-inner join(等值连接) 只返回两个表中联结字段相等的行(左右两表共有的)
order by:
依照查询结果的某一列(或多列)属性,进行排序(升序:ASC;降序:DESC;默认为升序)
1》单一列属性排序
2》多个列属性排序
选择多个列属性进行排序,然后排序的顺序是,从左到右,依次排序
如果前面列属性有些是一样的话,再按后面的列属性排序。(前提一定要满足前面的属性排序,因为在前面的优先级高)
group by:
按照查询结果集中的某一列(或多列),进行分组,值相等的为一组
1》细化集函数(count,sum,avg,max,min)的作用对象
未对查询结果分组,集函数将作用于整个查询结果
对查询结果分组后,集函数将分别作用于每个组
2》GROUP BY子句的作用对象是查询的中间结果表
分组方法:按指定的一列或多列值分组,值相等的为一组
使用GROUP BY子句后,SELECT子句的列名列表中只能出现分组属性(比如:sno)和集函数(比如:count())
3》多个列属性进行分组举例
4》使用HAVING短语筛选最终输出结果
只有满足HAVING短语指定条件的组才输出
HAVING短语与WHERE子句的区别:作用对象不同
1》WHERE子句作用于基表或视图,从中选择满足条件的元组
2》HAVING短语作用于组,从中选择满足条件的组
https://blog.csdn.net/vividboy/article/details/2313023
strftime是一种计算机函数,根据区域设置格式化本地时间/日期,函数的功能将时间格式化,或者说格式化一个时间字符串。
日期格式应该补充完整为‘0000-00-00 00:00:00’
https://blog.csdn.net/Lwmjm/article/details/8156648
SQL命令就是前端Web和后端数据库之间的接口,使得数据可以传递至Web应用程序。很多Web站点都会利用用户输入的参数动态地生成SQL查询要求,攻击者通过在URL、表单域,或者其他的输入域中输入自己的SQL命令,以此改变查询属性,骗过应用程序,从而可以对数据进行不受限的访问。
SQL常用函数参考:
https://blog.csdn.net/shengongbao114/article/details/89029087
https://blog.csdn.net/weixin_40444678/article/details/81026004
在MySQL中,我们可以通过EXPLAIN命令获取MySQL如何执行SELECT语句的信息,包括在SELECT语句执行过程中表如何连接和连接的顺序。
https://blog.csdn.net/wuseyukui/article/details/71512793
不同数据库连接字符串的方法不完全相同,MySQL、SQL Server、Oracle等数据库支持CONCAT方法,
SELECT CONCAT_WS(space(1),last_name,first_name) AS Name FROM employees;
SQLite数据库只支持用连接符号"||"来连接字符串。
concat、concat_ws、group_concat函数用法(参考:https://www.cnblogs.com/xbblogs/p/6066386.html)
INSERT INTO 表示插入数据,数据库会检查主键(PrimaryKey),如果出现重复会报错;
INSERT IGNORE INTO 表示,如果数据库中已经存在相同的记录,则忽略当前新数据;
SQLite中,使用 INDEXED BY 语句进行强制索引查询
SELECT * FROM salaries INDEXED BY idx_emp_no WHERE emp_no = 10005
MySQL中,使用 FORCE INDEX 语句进行强制索引查询
SELECT * FROM salaries FORCE INDEX idx_emp_no WHERE emp_no = 10005
https://blog.csdn.net/heizistudio/article/details/8593959
https://blog.csdn.net/bruce128/article/details/46777567
构造触发器时注意以下几点:
1、用 CREATE TRIGGER 语句构造触发器,用 BEFORE或AFTER 来指定在执行后面的SQL语句之前或之后来触发TRIGGER
2、触发器执行的内容写出 BEGIN与END 之间
3、可以使用 NEW与OLD 关键字访问触发后或触发前的employees_test表单记录
https://blog.csdn.net/Ashimar_a/article/details/78647809
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
https://blog.csdn.net/number1killer/article/details/77839529
replace(X,Y,Z):
X:要处理的字符串
Y:被替换的字符串
Z:替换后的字符串
由于SQLite中不能通过 ALTER TABLE ... ADD FOREIGN KEY ... REFERENCES ... 语句 -- 来对已创建好的字段创建外键,因此只能先删除表,再重新建表的过程中创建外键。
https://blog.csdn.net/championhengyi/article/details/78559789
《SQL FOREIGN KEY 约束》https://www.runoob.com/sql/sql-foreignkey.html
返回查询结果中相同的部分既他们的交集。
INTERSECT运算自动去除重复,如果想保留所有的重复,必须用INTERSECT ALL代替INTERSECT,结果中出现的重复元组数等于两集合出现的重复元组数里较少的那个
《Sql中的并(UNION)、交(INTERSECT)、差(minus)、除去(EXCEPT)详解》
https://www.cnblogs.com/elves/p/3653771.html
SQL查询语句中的 limit 与 offset 的区别:
-
limit y分句表示: 读取 y 条数据 -
limit x, y分句表示: 跳过 x 条数据,读取 y 条数据 -
limit y offset x分句表示: 跳过 x 条数据,读取 y 条数据
Case具有两种格式。简单Case函数和Case搜索函数。
--简单Case函数
SELECT SUM(population),
CASE (country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他'
END)
FROM Table_A
--Case搜索函数
UPDATE Personnel
SET salary =
CASE (WHEN salary >= 5000 THEN salary * 0.9
WHEN salary >= 2000 AND salary < 4600 THEN salary * 1.15
ELSE salary END);
- 介质故障是指外存储设备故障,主要有磁盘损坏,磁头碰撞盘面,突然的强磁场干扰,数据传输部件出错,磁盘控制器出错等,一般称为硬故障(hard crash)。
- 运行故障是系统软件或者应用软件等在运行过程中导致的一系列故障,一般称为软故障(soft crash)。
- 系统故障指在系统运行过程中,由于某种原因,造成系统停止运行,以致事务在执行过程中以非正常的方式终止,这是内存中的信息丢失,而存储在外存上的数据未受影响,这种情况称为系统故障。
- 事务故障更多的是非预期的,不能由事务程序处理的情况,主要有:①逻辑上的错误,如运算溢出、死循环、非法操作、地址越界等等;②违反完整性限制的无效的输入数据;③违反安全性限制的存取权限;④资源限定,如为了解除死锁、实施可串化的调度策略等而ABORT一个事务;⑤用户的控制台命令
范式是数据库逻辑模型的设计规范(规则),因为逻辑设计后就是物理设计,牵扯到具体的数据实施。如果没有一个合理的规范,数据库的数据将不规范,不利于以后的使用操作。
第一范式(1NF)
所谓第一范式(1NF)是指在关系模型中,对域添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性。在符合第一范式(1NF)表中的每个域值只能是实体的一个属性或一个属性的一部分。简而言之,第一范式就是无重复的域。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的设计基本要求,一般设计中都必须满足第一范式(1NF)。不过有些关系模型中突破了1NF的限制,这种称为非1NF的关系模型。换句话说,是否必须满足1NF的最低要求,主要依赖于所使用的关系模型。
第二范式(2NF)
在1NF的基础上,非码属性必须完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。例如在员工表中的身份证号码即可实现每个一员工的区分,该身份证号码即为候选键,任何一个候选键都可以被选作主键。在找不到候选键时,可额外增加属性以实现区分,如果在员工关系中,没有对其身份证号进行存储,而姓名可能会在数据库运行的某个时间重复,无法区分出实体时,设计辟如ID等不重复的编号以实现区分,被添加的编号或ID选作主键。(该主键的添加是在ER设计时添加,不是建库时随意添加)
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是在第一范式的基础上属性完全依赖于主键。
第三范式(3NF)
在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
第三范式(3NF)是第二范式(2NF)的一个子集,即满足第三范式(3NF)必须满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性,也就是在满足2NF的基础上,任何非主属性不得传递依赖于主属性。
巴斯-科德范式(BCNF)
Boyce-Codd Normal Form(巴斯-科德范式)
在3NF基础上,任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集的依赖)巴斯-科德范式(BCNF)是第三范式(3NF)的一个子集,即满足巴斯-科德范式(BCNF)必须满足第三范式(3NF)。通常情况下,巴斯-科德范式被认为没有新的设计规范加入,只是对第二范式与第三范式中设计规范要求更强,因而被认为是修正第三范式,也就是说,它事实上是对第三范式的修正,使数据库冗余度更小。这也是BCNF不被称为第四范式的原因。某些书上,根据范式要求的递增性将其称之为第四范式是不规范,也是更让人不容易理解的地方。而真正的第四范式,则是在设计规范中添加了对多值及依赖的要求。
定义:关系模式R∈1FNF,若X→Y且Y不是X的子集时X必含有码,则R∈BCNF。也就是说,关系模式R中,若每一个决定因素都包含码,则R∈BCNF。
由BCNF的定义可以得到结论,一个满足BCNF的关系模式有:
- 所有非主属性对每一个码都是完全函数依赖。
- 所有主属性对每一个不包含它的码也是完全函数依赖。
- 没有任何属性完全函数依赖于非码的任何一组属性。
若R∈BCNF,按定义排除了任何属性对码的传递依赖与部分依赖,所以R∈3NF。
一般关系型数据库设计中,达到BCNF就可以了!
举例:
1NF: 原子性,属性不能再分
2NF:不存在部分函数依赖,如(A, B, C, D),(A,B)为候选键,不能由候选关键字的一部分决定非关键字,如B->C
3NF:不存在传递函数依赖,如A->B->C
BCNF:进一步消除主属性的传递依赖(A, B, C, D), 候选键有(A,B)和(B,C),所以主属性为A,B,C,不存在(A,B)->C,
几乎所有的关系模式都符合第一范式,但是具体的数据库设计里,表最好达到第三范式(不包含部分函数依赖和传递函数依赖)
数据库的ACID性质:
- 原子性(ATOMIC) 整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节
- 一致性(Consistency)在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏
- 隔离性(Isolation)两个事务的执行是互不干扰的,一个事务不可能看到其他事务运行时中间某一时刻的数据
- 持久性(Durability)在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
数据库设计通常分为6个阶段
1需求分析:分析用户的需求,包括数据、功能和性能需求
2概念结构设计:主要采用E-R模型进行设计,包括画E-R图
3逻辑结构设计:通过将E-R图转换成表,实现从E-R模型到关系模型的转换
在数据库逻辑设计阶段的主要任务有:
1. 把 E-R 图转换为关系模型
2. 数据模型的优化
3. 用户外模式(用户子模式)的设计
4数据库物理设计:主要是为所设计的数据库选择合适的存储结构和存取路径
5数据库的实施:包括编程、测试和试运行
6数据库运行与维护:系统的运行与数据库的日常维护
主要讨论其中的第3个阶段,即逻辑设计。通过一个实际的案例说明在逻辑设计中E-R图向关系模式的转换。
SQL语言支持数据库三级模式结构,在SQL中,模式对应于基本表,内模式对应于存储文件,外模式对应于视图和部分基本表,元组对应于表中的行,属性对应于表中的列
数据查询语言( DQL ):其语句,也称为“数据检索语句”,用以从表中获得数据,确定数据怎样在应用程序给出。保留字 SELECT 是DQL (也是所有 SQL )用得最多的动词,其他 DQL 常用的保留字有 WHERE , ORDER BY , GROUP BY 和 HAVING 。这些 DQL 保留字常与其他类型的 SQL 语句一起使用。
数据操作语言( DML ) : 其语句包括动词 INSERT , UPDATE 和 DELETE 。它们分别用于添加,修改和删除表中的行。也称为动作查询语言,DML分为宿主型DML和自含型DML两类。宿主型DML本身不能独立使用必须嵌入主语言中,例如,嵌入C,COBOL,FORTRAN等高级语言中。自含型DML是交互式命令语言,语法简单,可以独立使用。
事务处理语言( TPL ):它的语句能确保被 DML 语句影响的表的所有行及时得以更新。 TPL 语句包括 BEGIN TRANSACTION ,COMMIT 和 ROLLBACK 。
数据控制语言( DCL ):它的语句通过 GRANT 或 REVOKE 获得许可,确定单个用户和用户组对数据库对象的访问。某些 RDBMS 可用GRANT 或 REVOKE 控制对表单个列的访问是用来设置或修改数据库用户和角色权限的语言,如 grant 。
数据定义语言( DDL ) : 其语句可在数据库中创建新表( CREAT TABLE );为表加入索引等。 DDL 包括许多与人数据库目录中获得数据有关的保留字。它也是动作查询的一部分。 DDL 比 DML 要多,主要的命令、有CREATE 、 ALTER 、 DROP 等, DDL 主要是用在定义或改变表( TABLE )的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用。
1.DDL包括模式、外模式、内模式定义模块、安全性定义模块和完整性定义模块。
2.子模式DDL用来描述数据库的局部逻辑结构
指针控制语言( CCL ):它的语句,像 DECLARE CURSOR , FETCH INTO 和 UPDATE WHERE CURRENT 用于对一个或多个表单独行的操作。
关系数据模型的逻辑结构是关系
层次数据模型的逻辑结构是树
网状数据结构的逻辑结构是图
between 和 and 关键字是闭区间
数据库完整性(Database Integrity)是指数据库中数据在逻辑上的一致性、正确性、有效性和相容性。数据库完整性由各种各样的完整性约束来保证,因此可以说数据库完整性设计就是数据库完整性约束的设计。数据库完整性约束可以通过DBMS或应用程序来实现,基于DBMS的完整性约束作为模式的一部分存入数据库中。通过DBMS实现的数据库完整性按照数据库设计步骤进行设计,而由应用软件实现的数据库完整性则纳入应用软件设计
数据库系统的三级模式是概念模式、外模式和内模式。
概念模式(模式)是数据库系统中全局数据逻辑结构的描述,是全体用户公共数据视图。
外模式也称子模式或用户模式,它是用户的数据视图,给出了每个用户的局部数据描述。
内模式又称物理模式,它给出了数据库物理存储结构与物理存取方法。
外模式使用户可以看见和使用的局部数据的逻辑结构和特征的描述。
·
模式使用户可以看见和使用的全部数据的逻辑结构和特征的描述。
设计数据库概念结构时,常用的数据抽象方法是概括、分类、聚集。
模式是内模式的逻辑实现
内模式是模式的物理实现
外模式是模式的部分抽取
外模式/模式的逻辑映像保证逻辑独立性,模式/内模式的映像则保证物理独立性。
外模式、模式在逻辑设计阶段得到,内模式在物理设计阶段得到

①模式(schema):
模式也称逻辑模式,是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
②外模式(external schema):
外模式也称子模式(subschema)或用户模式,它是数据库用固话(包括应用程序员和最终用户)能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。
③内模式(internal schema):
内模式也称存储模式(storage schema),一个数据库只有一个内模式。它是数据物理存储和存储方式的描述,是数据在数据库内部的组织方式。
数据库系统基本概念
-
数据库(DB):长期存放在计算机内的有组织的可共享的数据集合
-
数据库管理系统(DBMS):完成数据库的建立、使用和维护功能
-
数据库系统(DBS)
-
数据库+数据库管理系统
-
(应用系统+数据库管理员 +用户)
-
-
数据库管理员(DBA):除DBMS完成外,还需专门的人员来完成,这些人被称为DBA
外码要么为空,要么对应主码中的一个值
执行顺序:
from --> where --> group by --> having --> select
--> order by -->limit

数据库恢复的基础是利用转储的冗余数据。这些转储的冗余数据包括: 日志文件、数据库后备副本
关系模型的三个组成部分,是指关系数据模型的数据结构、
关系数据模型的操作集合、
关系数据模型的完整性约束
1)丢失更新
当两个或多个事物读入同一数据并修改,会发生丢失更新问题,即后一个事物更新的结果被前一事务所做更新覆盖 即当事务A和B同事进行时,事务A对数据已经改变但并未提交时B又对同一数据进行了修改(注意此时数据是A还未提交改变的数据),到时A做的数据改动丢失了
(2)不可重复读
当两个数据读取某个数据后,另一事务执行了对该数据的更新,当前一事务再次读取该数据(希望与第一次读取的是相同的值)时,得到的数据与前一次的不一样,这是由于第一次读取数据后,事务B对其做了修改,导致再次读取数据时与第一次读取的数据不想同
(3)读‘脏数据’
当一个事务修改某个数据后,另一事务对该数据进行了读取,由于某种原因前一事务撤销了对改数据的修改,即将修改过的数据恢复原值,那么后一事务读到的数据与数据可得不一致,称之为读脏数据
共享锁【S锁】
又称读锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁【X锁】
又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
关系代数的运算分为两类:一是传统的集合运算;二是专门的关系运算。
其中集合运算符包括并(∪)、差(-)、交(∩)和笛卡儿积(×)。
专门的关系运算符包括投影(π)、选择(σ)和连接([*]])和除(÷)。
其中并、差、笛卡儿积、投影和选择5种运算为基本的运算,其他3种运算均可以用5种基本运算来表达。
在 mysql 中 , “=” 会默认的当做比较符号处理 ( 很多地方 ), mysql 为了区分比较和赋值的概念 ,重新定义了一个新的的赋值符号 :=
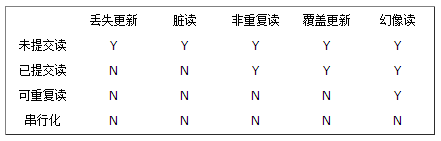
并发与事务隔离:
并发:丢失更新,脏读,非重复读,覆盖更新,幻想读
事务隔离:未提交读,已提交读,可重复读,串行化
1、更新丢失: 一个事务的更新覆盖了另一个事务的更新。
2、脏读: 一个事务读取了另一个事务未提交的数据。
3、不可重复读:一个事务两次读取同一个数据,两次读取的数据不一致。
4、幻象读: 一个事务两次读取一个范围的记录,两次读取的记录数不一致。
未提交读: 一个事务在执行过程中可以看到其他事务没有提交的新插入的记录,而 且能看到其他事务没有提交的对已有记录的更新。
已提交读: 一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,而且能看到其他事务已经提交的对已有记录的更新。
可重复读: 一个事务在执行过程中可以看到其他事务已经提交的新插入的记录,但是不能看到其他其他事务对已有记录的更新。
串行化: 一个事务在执行过程中完全看不到其他事务对数据库所做的更新。(事务执行的时候不允许别的事务并发执行。事务串行化执行,事务只能一个接着一个地执行,而不能并发执行)
视图包含下列结构是不可以更新的
1:集合运算符 union,union all, intersect,minus
2:distinct关键字
3:group by,order by,connect by,或者start with
4:子查询
5:分组函数
6:需要更新的列不是视图定义的
7:具有连接查询(可以更新键值保存表的数据)
8:违反基表的约束条件;连接视图是指基于多表连接查询创建的视图(一般不容易修改,但通用instead of触发器可以实现修改的功能)
绑定变量是相对文本变量来讲的,所谓文本变量是指在SQL直接书写查询条件,这样的SQL在不同条件下需要反复解析,绑定变量是指使用变量来代替直接书写条件,查询bind value在运行时传递,然后绑定执行。优点是减少硬解析,降低CPU的争用,节省shared_pool ;缺点是不能使用histogram,sql优化比较困难。
有一些必需的数据冗余是用来建立表之间的联系(所以数据冗余度并非越低越好)
CHAR的长度是固定的,而VARCHAR2的长度是可以变化的, 比如,存储字符串“abc",对于CHAR (10),表示你存储的字符将占10个字节(包括7个空字符),而同样的VARCHAR2 (10)则只占用3个字节的长度,10只是最大值,当你存储的字符小于10时,按实际长度存储。
视图设计的几种方法:
’1、自顶向下。先全局框架,然后逐步细化
2、自底向上。先局部概念结构,再集成为全局结构
3、由里向外。先核心结构,再向外扩张
4、混合策略。1与2相结合,先自顶向下设计一个概念结构的框架,再自底向上为框架设计局部概念结构
E-R图 用矩形表示实体型;用椭圆表示实体的属性;用菱形表示实体型之间的联系
在两个或者多个并发进程中,如果每个进程持有某种资源而又等待其它进程释放它或它们现在保持着的资源,在未改变这种状态之前都不能向前推进,称这一组进程产生了死锁。通俗的讲就是两个或多个进程无限期的阻塞、相互等待的一种状态。
死锁产生的四个条件(有一个条件不成立,则不会产生死锁)
· 互斥条件:一个资源一次只能被一个进程使用
· 请求与保持条件:一个进程因请求资源而阻塞时,对已获得资源保持不放
· 不剥夺条件:进程获得的资源,在未完全使用完之前,不能强行剥夺
· 循环等待条件:若干进程之间形成一种头尾相接的环形等待资源关系
SQL语言的使用有两种方式:
(1)在终端交互方式下独立使用的SQL称为交互式SQL。
(2)嵌入到程序设计语言中(即宿主语言)使用的SQL称为嵌入式SQL。
在SQL语句中引用宿主变量时,为了区别数据库中变量,宿主变量前须加“:”
连接运算符主要用于连接字符串,其运算符有两个:+,&;
&用来强调两个表达式作为字符串连接,如“hello”&23&"word",结果为“hello23word”
+连接两个字符串,要求+两端的类型必须一致,如“hello”+23+"word",结果会报错“类型不匹配”
因此一般使用&连接两个字符串
<=小于、>=大于 ≤=小于等于、≥=大于等于
关系的完整性主要包括域完整性、实体完整性和参照完整性三种。
1.域(列)完整性
域完整性是对数据表中字段属性的约束,通常指数据的有效性,它包括字段的值域、字段的类型及字段的有效规则等约束,它是由确定关系结构时所定义的字段的属性决定的。限制数据类型,缺省值,规则,约束,是否可以为空,域完整性可以确保不会输入无效的值.。
2.实体(行)完整性
实体完整性是对关系中的记录唯一性,也就是主键的约束。准确地说,实体完整性是指关系中的主属性值不能为Null且不能有相同值。定义表中的所有行能唯一的标识,一般用主键,唯一索引 unique关键字,及identity属性比如说我们的身份证号码,可以唯一标识一个人.
3.参照完整性
参照完整性是对关系数据库中建立关联关系的数据表间数据参照引用的约束,也就是对外键的约束。准确地说,参照完整性是指关系中的外键必须是另一个关系的主键有效值,或者是NULL。参考完整性维护表间数据的有效性,完整性,通常通过建立外部键联系另一表的主键实现,还可以用触发器来维护参考完整性
数据库中有可能会存在不一致的数据。
造成数据不一致的原因主要有:
数据冗余
如果数据库中存在冗余数据,比如两张表中都存储了用户的地址,在用户的地址发生改变时,如果只更新了一张表中的数据,那么这两张表中就有了不一致的数据。
并发控制不当
比如某个订票系统中,两个用户在同一时间订同一张票,如果并发控制不当,可能会导致一张票被两个用户预订的情况。当然这也与元数据的设计有关。
故障和错误
如果软硬件发生故障造成数据丢失等情况,也可能引起数据不一致的情况。因此我们需要提供数据库维护和数据恢复的一些措施。
对于串行调度,各个事务的操作没有交叉,也就没有相互干扰,当然也不会产生并发所引起的。事务对数据库的作用是将数据库从一个一致的状态转变为另一个一致的状态。多个事务串行执行后,数据库仍旧保持一致的状态。 可串行性(Serializability) 是并发事务正确调度的准则。在RDBMS中,作为并发控制的正确性准则。一个给定的并发调度,当且仅当它是可串行化的,才认为是正确调度
DBMS功能:
1.数据定义:提供DDL数据定义语言,提供用户定义,修改数据库的三级模式结构,两级映射,约束的操作。
2.数据操作:DML数据操作语言,提供增删改查的操作。
3.数据库的运行管理:安全性检查等功能,保证数据库系统的正常运行。
4.数据分类组织,存储,管理:提供数据字典等。
5.数据库的保护:提供数据库恢复,并发控制等功能。
6.数据库的维护:数据转储,性能监控等功能。
7.通信:DBMS与操作系统的联机处理,与其他软件系统或者数据库的通信。
1:1联系的转换方法
联系转换为一个独立的关系:与该联系相连的各实体的码以及联系
本身的属性均转换为关系的属性,且每个实体的码均是该关系的候选码。
1:n联系的转换方法
一种方法是将联系转换为一个独立的关系,其关系的属性由与该联系相连的
各实体集的码以及联系本身的属性组成,而该关系的码为n端实体集的码;
另一种方法是在n端实体集中增加新属性,新属性由联系对应的1端实体
集的码和联系自身的属性构成,新增属性后原关系的码不变
m:n联系的转换方法在向关系模型转换时,一个
m:n联系转换为一个关系。转换方法为:与该联系相连的各实体集的码以及联系本身的属性均转换为关系的属性,新关系的码为两个相连实体码的组合(该码为多属性构成的组合码)
一级封锁协议是:事务T在修改数据R之前必须先对其加X锁,直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。
一级封锁协议可以防止丢失修改,并保证事务T是可恢复的。使用一级封锁协议可以解决丢失修改问题。
在一级封锁协议中,如果仅仅是读数据不对其进行修改,是不需要加锁的,它不能保证可重复读和不读“脏”数据。
二级封锁协议是:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,读完后方可释放S锁。
二级封锁协议除防止了丢失修改,还可以进一步防止读“脏”数据。但在二级封锁协议中,由于读完数据后即可释放S锁,所以它不能保证可重复读。
三级封锁协议是:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。
三级封锁协议除防止了丢失修改和不读“脏”数据外,还进一步防止了不可重复读。
上述三级协议的主要区别在于什么操作需要申请封锁,以及何时释放。
[知识点] 表的索引:主索引,候选索引,普通索引,唯一索引
[评析] 索引类型分类:
①主索引:主索引是一种只能在数据库表中建立不能在自由表中建立的索引。在指定的字段或表达式中,主索引的关键字绝对不允许有重复值。
②候选索引:和主索引类似,它的值也不允许在指定的字段或表达式中重复。一个表中可以有多个候选索引。
③唯一索引:唯一索引允许关键字取重复的值。当有重复值出现时,索引文件只保存重复值的第1次出现。提供唯一索引主要是为了兼容早期的版本。
④普通索引:普通索引允许关键字段有相同值。在一对多关系的多方,可以使用普通索引。
系统数据库是由 SQL
Server内部创建和提供的一组数据库。其中最主要的数据库有 4个。它们分别是Master、Msdb、Model和Tempdb。
① Master数据库:用于记录所有SQL Server系统级别的信息,这些信息用于控制用户数据库和数据操作。
②Msdb数据库:由 Enterprise Manager和Agent使用,记录着任务计划信息、事件处理信息、数据备份及恢复信息、警告及异常信息。
③Model数据库:SQL
Server为用户数据库提供的样板,新的用户数据库都以 model数据库为基础。每次创建一个新数据库时,SQL Server先制作一个model数据库的拷贝,然后再将这个拷贝扩展成要求的规模。
④tempdb数据库:一个共享的工作空间,SQL Server中的所有数据库都可以使用它。它为临时表和其他临时工作提供了一个存储区。
1、常见的数据库优化手段
答:库表优化,表设计合理化,符合三大范式;添加适当的索引(普通索引、主键索引、唯一索引、全文索引);分库分表;读写分离等;sql语句优化,定位执行效率低,慢sql的语句,通过explain分析低效率的原因;
2、索引的优缺点,什么字段上建立索引
答:优点方面:第一,通过创建唯一索引可以保证数据的唯一性;第二,可以大大加快数据的检索速度,是主要目的;第三;在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间;第四,可以在查询中使用优化隐藏器,提高系统的性能;
缺点方面:第一,创建索引和维护索引要耗费时间,并且随着数据量的增加而增加;第二,每一个索引需要占用额外的物理空间,需要的磁盘开销更大;第三,当对表中的数据进行增加、删除、修改操作时,索引也要动态维护,降低了数据的维护速度;
一般来说,在经常需要搜索的列上,强制该列的唯一性和组织表中数据的排列结构的列,在经常用在链接的列上,在经常需要排序的列上,在经常使用在where字句的列上可以添加索引,以提升查询速度;同样,对于一些甚少使用或者参考的列,只有很少数值的列(如性别),定义为text,image,bit的列,修改性能远远大于检索性能的列不适合添加索引;
3、数据库连接池
答:数据库连接池(Connection pooling)是程序启动时建立足够的数据库连接,并将这些连接组成一个连接池,由程序动态的对池中的连接进行申请、使用、释放;
(1)程序初始化时创建连接池
(2)使用时向连接池申请可用连接
(3)使用完毕,将连接返还给连接池
(4)程序退出时,断开所有的连接,并释放资源