机器真的已经战胜人类医生了吗?医学AI标题党文章中的三大陷阱
作者 | Dr Luke Oakden-Rayner
翻译校对|吴蕾 刘晓莉 曹翔
◆ ◆ ◆
序
关于“机器人战胜人类医生”的文章铺天盖地,正高居各类科技网站首页。
例如《通过辐射变化,计算机程序的脑肿瘤辨识能力战胜医生(神经科学新闻,2016)》,《在肺癌的类别和严重程度预测方面,计算机击败了病理学家 (斯坦福医学新闻中心,2016),《人工智能阅读乳腺影像的精确度达到了99% (Futurism, 2016)》,《数码诊断:智能机器比人类更出色(Singularity Hub, 2016)》。
这些标题确实吸引眼球,有的更是出自于像斯坦福大学这样的专业杂志。显然,甚至不少专业人士都认为,机器在这些医疗相关的专业领域,已经战胜了人类。
但是机器真的已经开始战胜人类医生了吗?来自University of Adelaide的Dr Luke据此撰写了相关评论文章,并被选为uiux.blog过去一周最值得阅读的文章之一。作者希望通过这份“避雷指南”告诉大家:如何用批判性的视角来阅读医学人工智能报告,明辨真伪。
◆ ◆ ◆
医学人工智能文章的三大陷阱
我希望我能解释清楚为什么这些说法某种程度上是合理正确的,但又是全然错误的。我想这可能不仅仅对普通人有用,对大多数有识之士都会有所裨益。
这些文章中出现的错误类型大致有三种:作者要么不懂机器;要么不懂人工智能;再或者没有将医生和机器的诊断结果进行比较。
1)人类医生是否在从事机器做的事情
记者,技术专家,未来主义者等专业人士,其实很多并不懂医学。
医学是复杂的。
生物学,治疗学,整个系统是如此巨大,它超出了任何一个人的认知范围。 医生和其他医疗保健专业人员有一些模糊朦胧的感觉,但即便是他们,也只是管中窥豹。 我们可以看一下,治疗系统本身是多么复杂:
-
我们必须经过12年的培训,才能成为某项医学子领域的专家。 法律要求医生在整个职业生涯中保持学习,一般只能在数十年后才能达到高峰。
-
研究人员将他们的生命献给了人类生物学的极小的一部分。
-
对于每个医生或管理人员,需有成千上万的其他训练有素的专业人员相辅,才能保持医疗体系正常运行。 在许多国家,医疗保健人员比任何其他行业都多,大多数人接受过高等教育。
医学的规模是巨大的。
医学研究产出大于任何其他学科的数量级,其规模之大令人乍舌。
-
你认为NIPS(Conference and Workshop on Neural Information Processing Systems,即神经信息处理系统大会)有几千个名参观者,已经是大会了? 事实上,最大型的放射学会议RSNA,有超过五万人次参加。
-
我们顶尖期刊的影响因子将近60(根据nejm网站公布,http://www.nejm.org/page/media- center / fact sheet),它有超过六十万名读者。 NIPS会议是在5以下,一些小组在Nature杂志发表文章,但即使Nature杂志本身,影响因子只有38。
-
资金总额难以确定,但对于医学和所有其他科学来说,美国公共资金的比例约为3:1。
-
仅看PubMed的话,即便它只检索4000个左右的期刊,每年也要检索约一百万篇医疗文章。
医学是特殊的。
它经常会都围绕着一个可疑的论据进行研究,而且错误的结论,被误导的结果,不可重现的结果,甚至没有结果,各种错误比比皆是。 我们的许多决定是出于非科学的原因作出的,背后受文化,政治,金融,法律等方面的影响。 除非你置身其中,否则你将很难理解其来龙去脉。甚至即便你从内部来看,它也没有太清晰的意义 。
医学是一片混沌,这句话并非虚言。
这就是为什么你所感受到的,相对于医生实际的所作所为,大部分理解是错误的。那是因为某些东西听起来像是医学的,似乎在医学实践的范围之内的,这并不意味着这是医生所从事的。
那么,假如医生并没有在实践和学习,并不擅长,甚至并不觉得某项工作很有意义,我们讨论机器做得比医生好又有什么用呢?
让我们再来看几个例子。我推荐的这个文章在是reddit上非常著名的一篇文章,这是一个很棒的研究团队写的一篇很棒的文章,然而经常被断章取义地引用。
(研究报告链接:
https://med.stanford.edu/news/all-news/2016/08/computers-trounce-pathologists-in-predicting- lung-cancer-severity.html)。
它发布于斯坦福医学新闻中心,意思是在预测肺癌类型和严重性方面,计算机战胜了病理学家这是颇具挑战性的言论。 显然,在某些预测任务方面,他们创造的机器学习系统已经远远超过人类病理学家。我会忽略这件作品中的多处医学错误,并专注于问题的本质。
他们说,电脑能更好地预测癌症。
这就应该唤起人们的警醒。如果你在标题上看到“预测”之类的字眼,你就可以停止阅读了。
规则一:医生不会进行预测
这完全是不直观的说法,但基本上是真实的。我们看下面的文章摘要部分选取:
“现在实行的病理学是非常主观的,”迈克尔斯奈德说(https://med.stanford.edu/profil/michael-snyder),他是博士,教授和遗传学主席。 “两个非常熟练的病理学家评估同一张幻灯片,将只有约60%的可能性达成一致。
然而,对于病理幻灯片的人工预测,是无法准确预知病人的预后情形的。
这也强调了我的观点。人类医生并不做这件事情。
他们训练计算机去识别哪些癌症患者存活时间更短,这听上去是医学话题,而且很有用,然而并非如此,没有证据说这是有帮助的。
病理学家经过学习和锻炼,提供的是各种治疗的方法,做手术或不做手术,采用化疗还是放疗,进行两项,三项,还是都不需要。 这些不是去定义一个人将活多久,病理学家没有理由擅长此道。
那么,做病状预断研究有帮助吗?答案是一定的。 我完全同意斯坦福研究团队, 这是医学的未来。 预测分析是一种识别有效患者组的好方法, 这无疑将为我们带来更稳妥的治疗决定。我们称之为精准医疗。之所以称其为精准,是由于它与我们目前的做法不同。 不精确的医学是建立在一整套妥协和简化的流程之上的,尽管现在工作得也很不错。
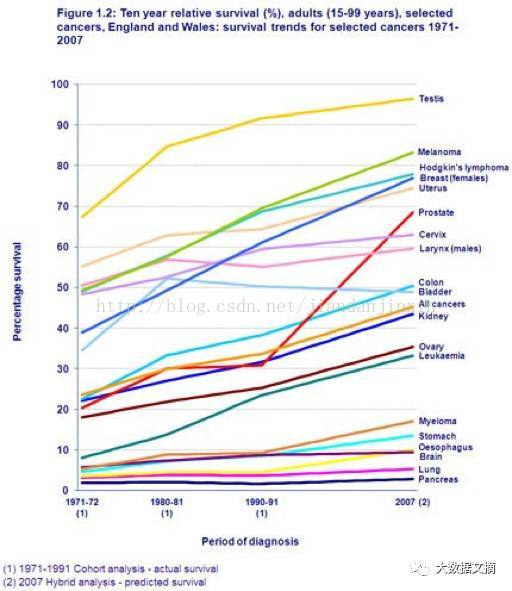
图1.2:十年相对存活率,成人组,部分癌症。
英格兰和威尔士:1971-2007年部分癌症存活率趋势
这是我最喜欢的图表,即使我们没有做任何预测,我们也在进步。
关键是,我们需要一个定义,“打败医生”实际上是什么样子。
如果我们接受一台机器在任何含糊的医学行为上胜过一个医生就足够了,那我们对于完整的概念就过于轻描淡写了。
就如同我们说,在不使用手的情况下驾驶时,自动驾驶汽车比人类驾驶更好,这是无谓的重复。
在这种错误理解的风气下,预测并不是唯一被用错的东西。 看看广泛报道的外科医生机器人史上首次击败人类医生,其中机器人在缝合猪肠子的时候,“胜过”人类外科医生。
(相关链接:
http://spectrum.ieee.org/the- human-os/robotics/medical-robots/autonomous-robot-surgeon-bests-human-surgeons-in-world- first)
还有一篇出自于一份优秀杂志的报道,一个惊人的团队在进行惊人的工作,他们创建了一个自主的肠缝合机器人。从上下文来看,这是一个伟大的进步。
(相关链接:http://stm.sciencemag.org/content/8/337/337ra64)
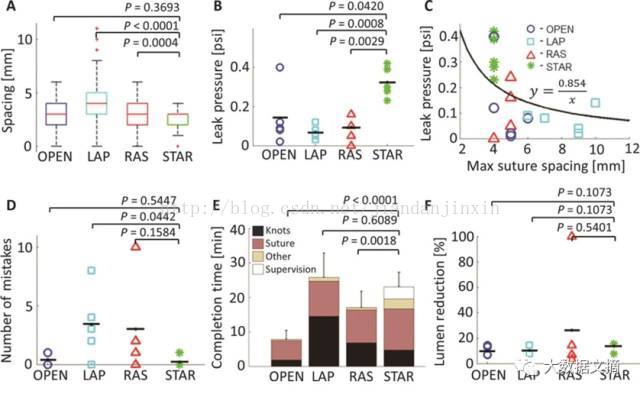
图3 是从论文中截取的优秀成果
看看图。 他们测试了什么? 缝合间距的准确性;迫使修复完成的肠道泄漏所需的压力有多大。 这些是机械度量,并且不清楚它们与结果有什么相关性。 泄漏一次听上去是临床用辞,但没有证据表明,泄漏所需的力和实际泄漏的数量之间有直接的联系。 可能有阈值效应,但“更好的”缝合并没有特别的有用之处, 可能有S形图案,或其他更复杂的关系,这可能导致厌食症的加重,医学届总有奇怪的事情发生(https://www.ncbi.nlm.nih.gov/pubmed/24355117)(用抗凝血剂浸透的支架产生更多凝块)。 我们只是不知道究竟发生了什么。
底部三个图是不同的。 错误的数量,手术时间,手术并发症的存在。 这些都外科医生跟踪作为自己表现的重要指标。 STAR(Smart Tissue Autonomous Robot)在这里,并没有更好。花费了更长的时间,STAR在错误或并发症方面没有显着差异。
你现在可能有点困惑,因为好像我刚刚描述了一组不同的图。 STAR看起来在最后三个图里表现相当不错。
STAR是在执行开放性手术。 外科医生会立即理解这一点,并忽略LAP和RAS结果,因为这是不公平的。 他们在猪身上切了一个大洞,把肠子拉出去修复。 这是一个很重要的问题。与其相比,人类使用腹腔镜进行手术,这就像要求他们将一只手绑在背后。 开放性手术对患者的风险高得多。
我们使用腹腔镜外科手术,尽管并发症发生比例会上升一些,你不需要在患者身上打一个很大很危险的洞,这对病人是有好处的。
和人类外科医生实施开放性手术相比较,STAR输了。手术时间长三倍,三倍长时间的全身麻醉可不是什么小事情。
正如Andrej Karpathy所说:人的精确度不是一个点,而是一条曲线。 我们总是权衡于精度和时间代价。 外科医生不会纠结于毫米级别的精确的缝间距,可能是因为它没什么意义。 我并没有对近一百年的外科手术加以研究,但是如果更仔细的缝合有帮助的话我完全乐意考虑, 外科医生或许也会接受这样的手术(或许不会((http://qualitysafety.bmj.com/content/early/2015/07/09/bmjqs-2015-004319),往往文化胜于证据)。
这与预测癌症存活是一样的,病理学家不会试图将人分成十几个生存类别,然后再决定要不要做手术。
所以也许有一个更普遍的规则,什么时候才能说机器人击败了医生?
规则1:用公平的准则进行比较
规则1a:医生不做预测
规则1b:问医生他们实际做了什么,以及什么样的测试更公平。 医生致力于在准确性和时间代价之间进行权衡,并优化结果(无论是健康,财政,政治,文化等)
这是否意味着我们需要进行大型随机对照试验,以找出相关系统是否真的有助于结局?
我不会这么做。 我能想到某些特定的任务,通过因果链的理解足以做出一个准确的推断。 例如,在上面的论文中,肠腔内减小肠修复已经通过足够彻底的测试,需要20%或更多的减少以具有高几率的症状。 我们可以使用它作为比较点。 但是说13%比17%更好...我们可能需要进一步测试来验证这个说法(或问外科医生!)。
这是我在“超人”医学系统研究中看到的第一个问题,但不是所有的任务的选择都不合适。 有一些任务确实是医生实施的,我们知道如何做得更好。 例如,通过辐射变化来观察脑肿瘤,计算机程序击败了医生(http://neurosciencenews.com/ai-brain-cancer-neurology- 5058 /)显示,计算机能够比放射科医生更好地区分放射性坏死(放疗有时会导致该问题)脑肿瘤复发。 这是非常重要的,是放射科医生的难题,也是计算方法的一个伟大目标。
这也自然来到了第二个常见的错误。
2)这不是你所谓的人工智能
人工智能,是这么回事儿? 机器学习是在蚕食世界? 深度学习现在如此热门? 当然,但这并非全部。
并不是所有的机器学习都是平等的,并非所有的都是开创性的,即使大多数人没有看到差别并且认为它是重要的。
然而,它也确实很重要。
因为发表在美国神经放射学杂志(AJNR)上的一篇关于脑肿瘤的论文(同样很好、重要的论文)并没有使用深度学习。这在放射学文献中是非常常见的,因为从2010年或者2011年开始,一些主要的论文表明旧式的图像分析可以做一些有趣的事情,例如从医学图像中鉴定出的癌症病例中的肿瘤亚型。
这些技术并不能轻易地基于人类的大脑。他们并不“领会”世界。他们不具有“认知”能力、不“智能”,也不会像其它的流行用语一样广泛流传。
这些技术已经存在几十年了,我们已经有足够的计算能力可以以几乎相同的时间在笔记本电脑上运行它们。长期以来,这项工作并没有遇到硬性障碍。那么为什么之前尝试了成百上千次的一直失败,现在突然成功了?
现在,这并不是关于它自身的一个争论,而是它应该被关注。非深层系统在类似于人类的任务中并没有表现得很出色。
相同的技术在物体识别方面并没有击败人类。他们不能帮助解决Go或者Atari。他们不能击败人类打字员,也不能安全和自主地驾驶汽车数亿英里。他们从来没有离开过停车场。
规则二:深度学习并不利用人类设计的特征
旧式图像分析方法是人类通过精心构造的数学矩阵来描述图像。这是非常困难的,所以我们能做到最好的是识别图像的构建基块。像边缘和小图案的东西,我们可以量化它们在图像或者图像区域中有多少。
这是他们在论文中要进行的步骤。

对于初学者,你可以看到为什么对于放射科医生来说那么难。A和E看起来完全相同。
他们在这里做的是:将区域变明亮(使其内部更光滑),量化目前存在多少纹理。他们在大约50名患者队列中尝试了一百多个纹理,选择表现最好的那些并把它们组合成一个识别标志用于预测。在一定的统计确定水平上,使用这些标志的表现优于人类。
希望任何受到过系统训练的个人读到这里,现在要敲响警钟了(谨慎注意了)。
使用人为定义的特征最大的问题是,你可能需要测试它们,并选择最好的。
多假设检验是一个诡异的存在。我真的特别想写一篇博客文章来谈这一点,因为我发现它确实太神奇了。其实这个故事的寓意是:如果你测试了许多假设(“检测癌症的纹理x”是一个假设),那么你会得到很多假阳性(False Positive)。如果你测试的p值是0.05,那么你的结果有5%的机会逃掉。如果你在阈值0.05下测试得到100个结果,那么你可能会有20个逃掉的结果。
特征选择:选择表现最佳的特征—可能会变得更糟,不是更好。你期望的20个逃掉的结果,然后你挑出前十个特征。
我喜欢本文用于特征选择的mRMR算法,并且我自己也使用它。但是最后的维度降低不会解决过拟合。你早已过度的拟合了你的数据。特征的选取可以帮助我们探索预测并呈现它们,没什么别的了。
事实上,所有的研究人员都明白这一点。我们知道,当我们样本量n非常小,特征p较多(特征数超出样本数)时,我们很有可能过拟合。我们尽最大努力采用诸如留出验证集(hold-out validation sets)、交叉验证(Cross-Validation)等技术减轻这种情况的发生。这个团队做了所有的这一切,并且表现得非常完美,是一个高质量的工作。
但是这一领域的所有研究人员仍然知道这样的结果不能被信任。这并不真实。我们可能不需要大规模的临床随机试验,但是除非一个系统希望对来自一个完全不同的患者队列的更多病例进行测试。
但不要用我的话语理解它。让我们一起来阅读这篇文章。
我们的研究确实有其局限性。作为一个可行性研究, 由于受限于训练集和holdout 集相对较小的样本量,报道的结果只是初步的。
需要强调的是,这些研究员恰好在这里已经对自己研究的局限性有所表达。
它不只是样本大小。你可以完美地分割你的训练和测试集,但如果你尝试十几种不同的算法去观察哪种算法表现最好时,你已经过拟合了你的数据(图再次源于斯坦福的论文)。虽然还行,但是也必须承认(过拟合)。
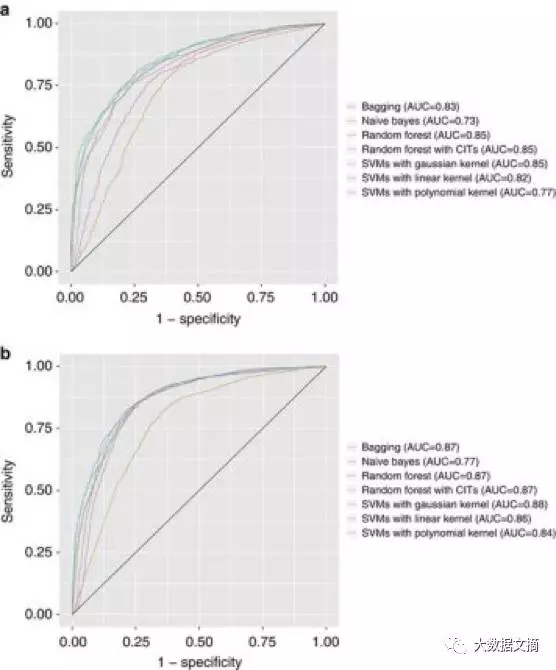
测试多个算法可以告诉你真实测试精度的大致范围,但是你不应该期望在新的数据集中有相同的结果。
还有一件有点更有争议的事在这里需要提及,就是公共数据集。你需要对公共数据集非常谨慎,尤其是如果你之前曾工作中接触过它们或是在一篇论文、博客文章或者tweet上阅读过一些人曾接触或使用过它们。因为你刚污染过你测试集。你知道什么技术在这个数据集中比其他的更好,这就有了它自己的特性和偏差。那么你得到拟合偏差的虚假结果而不是真实研究目标的机会会非常高。
许多机器学习研究人员对ImageNet感兴趣,不会对每周的“新的先进的”结果感到非常兴奋,除非在精确度上有了明显的提升。由于数百个组正在处理数据,并且尝试了数百个具有广泛超参数搜索的模型,因而它们没有理由不会出现过拟合。
我的机器学习的同事耸了耸肩。它只是被接受,半信半疑地采取每一个结果并继续前进。如果有人告知记者和公众,这是最好不过了。
因此,这是对于规则2更好的表述。
规则2:阅读论文
规则2a:如果不是深度学习,它可能并不比医生好。
规则2b:在小型或者公共数据集中,过拟合是极为容易发生,且不可避免的。因而需要寻找更大规模的测试集,多个无关的队列,真实的患者。
3)文章所说和你所想并非一致
类型3的错误是很容易的。这篇文章从未提到标题所指内容,或文章完全误解了研究。
数字诊断:智能机器相比于人做的工作更好,Singularity Hub 是一个很好的例子。文章并没有单独提出头对头的比较。这些都是猜想和假设。即使它可能是一篇好的文章,但它的标题并不合适。
人们认为未来人工智能读取乳腺影像的准确度能达到 99%,这有点令人震惊。这篇论文是关于使用自然语言处理的研究。它与阅读乳腺影像无关,但从放射科医生所做的报告中提取了文本信息。标题是错误的,其他很多文章也有这样的问题。
规则三:阅读文章
十分简单
医生是有优势的……
那么它离开我们要去何方?
我仍然坚信,我们还没有看到一台机器在任何与实际医疗实践相关的任务中胜过医生。慢慢建立起来的前期研究表明这并不会永久持续,但到现在为止我没有看到机器人获胜的情况。
我希望我的规则将是有用的,以帮助区分尚未完成的伟大研究和值得非常激动的真正突破。
如果我错过了某个研究,请告知我。
当我写下这些,从字面上的最后一段变得不真实。
Google刚刚在美国医学协会杂志(影响因子37)上发表了这篇论文。因为它实际上依赖于大肆的宣传,这是一个好的方式结束这部分。因为当情况变化,任何有价值的规则集仍然可以工作。
他们训练了深度学习系统,以从视网膜的图片诊断糖尿病视网膜病变(眼睛中的血管损伤)。这是眼科医生目前使用完全相同的技术执行的任务,通过眼底镜观察视网膜。
Google的系统在一个大型临床数据集(130000名患者)中与专家的表现不分上下。虽然这不一定是“超越”人类医生,但运行该模型可能只需要花费每个患者不到一分钱。一个眼科医生的成本远远不只这一点,并且老实的说,他们应该有时间去做更值得做的事。我很高兴称这次机器学习取得了胜利。
让我们一起看看我的规则,他们可以工作起来吗?
规则1——这是人类医生做的,以相同的输入完成任务。
规则2——是深度学习,具有相当好的数据集。
规则3——它真的是一件事情吗?
所以你看,我科学地证明了我自己的系统是错误的。
现在还不能叫我是一个愤世嫉俗的医生。
作为最后一点,值得看看为什么Google系统可以工作。大部分情况下,他们购买了一个很好的数据集。他们有一个2~7名的眼科医生小组对130000多个图像(源于一组的54名眼科医生)中的每一个进行评分。这是一个巨大的任务,我甚至都不认识54名眼科医生。
这个技术可能接近准备一个大型的随机对照试验,这可是一个了不起的事情。
这些未来几年我们将会看到。将会有许多这样的任务,如果有人愿意构建数据集,人类可以做什么,计算机就可以做什么。虽然大多数医疗任务可能并不适用于此,但是这将足以开始频繁地发生。
这确实令人激动。