【七】分布式微服务架构体系详解——分布式一致性
前言
我们在前面几篇文章中介绍了,分布式环境下会有网络延迟,节点挂掉的问题。这些问题解决的理论都和分布式一致性息息相关。无论是数据存储的集群,或者微服务系统的集群,为了达到高可用性,我们希望系统能够对分布式问题有很好的容错,保证一直会给用户一个好的Response。通过本章节,我们将了解到分布式系统中的一些“可能”以及“不可能”。
本文先介绍分布式系统中几个重要的理论:CAP、BASE、FLP不可能结果,以及这些理论的应用领域,可以让大家对耳熟能详的技术的背后理论有个更好的了解。然后再介绍下分布式一致性模型的概念和实现,理解了分布式一致性模型之后,后续章节会继续介绍一致性模型在分布式事务中的实践。
分布式系统相关理论
在分布式系统理论中,比较被广泛应用的就是CAP和FLP不可能结果理论。FLP基于异步通信模型的假设,一般是用于一些学术领域以及作为一些分布式算法的设计理论基础。CAP理论更加偏向于实践性,在最开始设计一个分布式系统的时候,需要很清楚我们需要的系统特性,而不需要关注具体的分布式算法的实现,所以依据一些理论,可以帮助我们根据具体场景更好地进行技术的选型。
对于分布式系统的理论,我们需要去了解,但在技术选型时要避免过于局限于理论的限制。
CAP
2000年7月,Eric Brewer教授提出CAP猜想。2年后,麻省理工学院的Seth Gilbert和Nancy Lynch从理论上证明了CAP。CAP理论已经成为分布式计算领域的公认定理。CAP理论主要由三个属性构成,C(Consistency)、A(Availability)、P(Partition tolerance)。根据CAP理论,这三者只能同时最多满足2个。三个属性的含义如下:
- Consistency(一致性): 所有节点访问的都是同一份最新的数据。
- Availability(可用性):系统一直能正常响应用户的请求。
- Partition tolerance(分区容错): 即使网络分区异常,节点通信消息丢失,整个系统还可以正常运作。
CAP的一些典型实践如下图:

CA,CP,AP 都有对应的实践,但是同时满足三者的中间区域是不存在的。
- CA:以保证严格的一致性为代表的2PC(两阶段提交,会在下一篇详细介绍),常用于一些传统的分布式关系型数据库系统如Oracle、Mysql的非集群版本,为了保证完全一致性,所以会牺牲分区容错。
- CP:典型的“多数选举算法”如:Paxos,Raft。保证了分区容错以及强一致性,可以允许少数节点是不可用的状态。大多数情况对于 2N+1个节点的集群可以允许有N个节点同时无法提供服务。应用方面,Zookeeper即是一个典型的CP分布式系统,Zookeeper 的 Zab 算法保证了任何时间访问不同节点都是得到一致的数据,但是会允许丢弃部分请求,需要客户端重新请求。
- AP:使用Gossip协议来做错误检测、保证了高可用以及分区容错,存储领域典型的应用有Amazon Dynoma提供了最终一致性而非强一致性,服务发现的应用如:Consul,基于Gossip协议来实现高可用的节点管理和集群广播消息以及弱一致性的保证。
关于2PC、Paxos算法会在后面一篇《共识问题》中详细介绍实现的细节。我们先关注下,如何取舍。首先,在现代分布式系统中,基本无法舍弃Partition tolerance。2PC一般用于传统的数据库系统,是因为很早的时候,还没有涉及到需要数据节点的分区,一般单机房只有主-从复制的情况,选择CA可以很好得保证分布式的事务特性。
目前,随着跨机房分布式系统尤其是跨地域分区节点的系统设计,分区容错性已经成为分布式系统必须具备的条件。所以更多的时候,需要在A和C中进行权衡:
- P+A:在CAP理论中,对于一些条件的假设是很苛刻的,比如一致性的语义是强一致性的,对于大多数的分布式业务系统来说,并不需要强一致性模型,而是最终一致性。所以如果你需要最终一致性模型,那么也可以保证在高可用性的前提下提供弱一致性模型。有些系统丢弃强一致性的原因,并不是为了分区容错,而是性能,因为强一致性提供了即使在网络故障时,所处理的请求结果一直是一致的,所以一般是为了强一致而阻塞请求,RT(response time)也会很高。所以对一致性要求不高的分布式系统往往实践着P+A+弱一致性。
- P+C:对于一些特殊场景,比如金融业务,又或者提供了一致性存储的分布式系统(如:Zookeeper),需要提供强一致性的保证。所以,会牺牲部分可用性。但是CAP的可用性也是比较狭义的,在实践中几乎无法保证永久的可用性,所以对于分布式系统的高可用性,常常用几个9来衡量。一般99.9%以上的可用性都可以称为高可用,换算下来,一年有<8.8h小时无法提供正常响应的系统,也是可以做到P+C+高可用性。
CAP理论不是让我们思考怎么实现的,更多的时候,是提供技术选型的参考。CAP理论定义在2000年,基于一些历史原因,所以也存在一定的局限性。比如Partition tolerance,也只描述了网络分区不可用的一种异常的情况,并没有考虑网络延时、节点挂掉等异常。反过来说,在有着可靠的稳定的网络的情况(比如,确保网线永远别被挖掘机挖断),也不存在需要在一致性和可用性之间选择了。
BASE理论
CAP理论的假设条件是很苛刻的,在现代的一些分布式系统的实践、以及大部分分布式NoSQL存储系统(HBase, Cassandra、Redis等等),为了得到更好的性能和扩展性,更多是提供BASE的保障。BASE理论是由三个词组组成:
- Basically Available:基本可用。对于存储系统来说,保证大多数时候是可用的。对于一些大型分布式应用系统来说,其底层的体系和部署更加复杂,一般是用*几个9(如99.99%)*来定义高可用性。
- Soft State:柔性状态,为了得到更好的扩展性,类似NoSQL系统,包括Mysql集群的异步模型的数据复制,是允许中间状态可见的。
- Eventual Consistency:最终一致性,也是分布式一致性模型中的一种弱一致性模型,如果停止往系统中写入数据,过一段时间,所有节点可以访问到同一份数据副本。
分布式的NoSQL系统的一致性理论大多基于BASE模型,而无法提供ACID特性。为了让开发者有更直观的理解,常常看到很多关于BASE vs ACID的对比,其实ACID和BASE是两个维度的概念。比如,ACID的原子性和隔离性是需要保证没有部分成功,不可见中间状态的,但是BASE的柔性状态是允许在某个时间点可以看到中间状态的数据。关于可用性方面,传统关系型数据库大多是单节点,在单个节点故障基本系统可用性很低,但是BASE 具有分区容错的特性,在可用性上会保证部分节点失败后其余正常节点可以响应请求。而关于一致性方面,ACID中的一致性和BASE中的一致性也不是同一概念。就像上一节介绍的,ACID的“一致性”是指事务中的数据的完整性约束不被破坏,而BASE的“最终一致性”是分布式一致性模型中的一种,下文会详细介绍各种一致性模型。
FLP不可能结果 (FLP impossibility result)
相比较CAP的实践性,FLP 不可能理论 更多的出现在共识算法的领域。FLP是以其三位作者 Fischer,Lynch, Patterson的名字命名的。
FLP 不可能理论阐述了基于异步的系统模型(系统模型可以回顾第 01 章,如果有节点挂掉的可能,即使网络是可靠的(消息会有延迟但只要消息目标节点没有挂掉,就一定会到达),也不存在一个可靠的共识算法。也即异步系统模型中有一个节点挂了,那么就无法保证所有节点达成共识。
FLP impossibility更多是作为设计共识问题的算法的理论。共识算法主要是为了解决分布式系统中,所有的节点如何对于某一个值达成一致。所以分布式系统的共识有以下三个标准,并且缺一不可:
- Termination(终止性):非失败进程最终需要决定一个值。
- Agreement(一致性):所有的进程必须决定的值必须是同一个值。
- Validity(有效性):这个被决定的值必须是被某些进程提出的。
一个算法如果做到了以上三点,则可以说其算法是一个共识算法,用通俗的方式理解,关于“4个人今晚吃什么”场景的共识结果如下图:
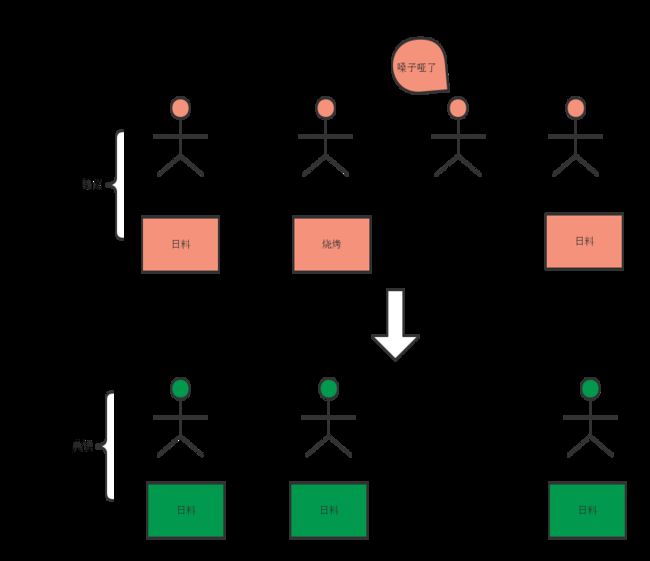
应用在分布式系统中,“共识”可以保证分布式系统的一致性。在同步系统模型中,有一些协议可以保证共识,如3PC(3阶段提交,会在下一章详解)。但是在异步系统模型,不存在基于FLP给出的假设条件下的共识算法。即使在共识算法中很出名的 Paxos 算法,其模型比FLP不可能理论的模型更加松散,Paxos允许消息丢失,也即假设网络也是不可靠的。但这并不影响Paxos在实践中的应用,Paxos算法已经做的足够好了,其具有分区容错特性,并且在少于1/2的节点失败的情况下,其余的节点还可以保证最终达成一致。Paxos保证了 Validity,Agreement 但是不保证绝对的Termination。不能完成终止性是因为Paxos存在活锁。Paxos算法的细节会在《共识问题》章节介绍。
尽管FLP 不可能理论是共识问题领域的重要理论,其证明了异步模型的共识不可能,但是分布式系统还是可以在实践中获得共识。关于分布式系统事务的实践,会在下一章介绍。
分布式一致性模型
一个单机系统中,比如我们往一个记事本中写入一句话,可以马上读到这一句话。而在分布式环境,存在多个节点(进程/实例),系统模型一般是异步的,节点可能crash,网络会有延时。往一个节点写入数据,从其他节点也能读到同样的数据,这样一个简单的事情,实现起来并不容易。分布式系统的一致性,就是为了处理系统中不同节点之间数据、状态的一致程度。根据这种程度的不同,被划分为一些不同的一致性模型。比如,CAP中的一致性是一致性模型中最严格的,所以也叫 “强一致性模型”or“线性一致性”or“原子一致性”。一般用于一些传统的关系型数据库。除了强一致性模型,也有一些弱一致性模型,如顺序一致性、因果一致性、最终一致性。
回顾下第3章 数据复制的内容,在一个基于异步复制的分布式数据库系统中,同一时间点访问两个数据库的节点,看到的是不同的数据,这是因为同一份数据写入两个节点是在不同的时间点,所以在分布式存储系统是不存在强一致性的,无论用了什么数据复制技术或者复制模型(主-主,主-从,无主节点等)。所以大多数数据库集群选择了最终一致性。也即如果停止往数据库的写请求,过一段时间,最终所有读请求都返回相同的值。也有的存储系统达到了强一致性,但这就要牺牲性能或者降低系统的容错性。
下面一起看一下不同的一致性模型的概念以及实现思路。在分布式系统实践中,需要哪一种一致性模型,更多的是要契合具体的需求场景。
线性一致性 (Linearizability)
概念
线性一致性Linearizability 模型的定义条件是很严格的。其需要分布式系统中,不同的进程(节点)满足以下两点:
- 写提交之后,能读到最新的值。
- 一个读请求读到了最新值,后需的读请求也返回这个最新的值。
也可以理解为:分布式系统的读写请求,就像在一个单实例的节点中原子地执行所有操作,所有操作是按照全局顺序执行,就好像是在单个机器上按照实际时间顺序执行所有操作一样。所以CAP理论中的C的一致性模型即是这里的强一致性模型。下图简单示意了线性一致性的数据的读写特征:
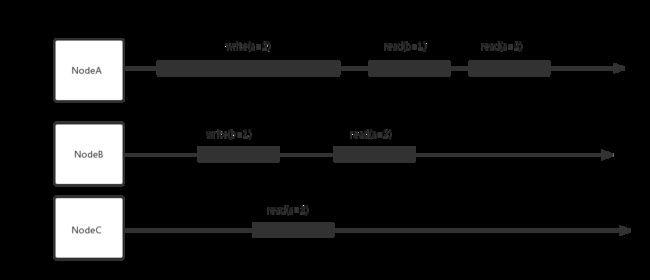
可以看到 NodeA 写入 a=2 之后,只要写入值生效之后,NodeC 就可以读到 a=2,随后的其他节点也都可以读到相同的值。
这里再区别一下两个词Serializability以及Linearizability以及的概念:
- Serializability(串行隔离): 用于描述数据库领域的,事务隔离的顺序性。每个事务可以读写很多对象,串行隔离保证了事务就像这些操作按照一定串行规则执行。有的数据库可以同时提供Serializability以及Linearizability,比如使用2PL(两阶段锁)实现隔离,并且用串行执行实现线性一致。而SSI的隔离实现不是线性一致的,因为通过快照读,读不到最新的值,并且隔离语义中不包含对于“写”的处理。
- Linearizability(分布式计算的线性一致): 用于描述分布式系统的操作,读写的顺序性。并不是针对事务中的操作的顺序而言,主要强调了对于分布式计算的读写的操作的顺序性。
实现
对数据一致性要求高的系统可以使用线性一致性模型,但是其性能一般无法接受。比如在第3章 数据复制中,假设我们的存储集群是Single-leader复制的模型,也即写入只写到单主节点,其他从节点采用同步复制的方式,则可能实现线性一致性。
在分布式系统中,如果想实现线性一致性,需要通过一个可靠的共识算法。比如Paxos,Raft。当然实现一个共识算法是很困难的,关于这两个算法的论证,会在后续的“共识算法”中介绍。目前比较普遍的方式是使用基于这两个算法的开源技术——Zookeeper、Etcd。这两者都是提供线性一致性的。
顺序一致性 、因果一致性(Sequential consistency and Casual consistency )
概念
比线性一致性较弱一点的一致性模型是顺序一致性。顺序一致性的 “顺序” 不是全局顺序,而是所有进程都以“一定顺序"执行。并且顺序一致性也没有全局时间概念,只是在并发处理时,让不同节点的操作顺序,在本地处理起来是一致的。
先来看一个示例,可以更直观地看一下顺序一致性的执行特点:

上图满足顺序一致性,但是不满足线性一致性。因为读不到最新写入的值。但是对于NodeA,NodeB 节点自身来说,NodeA节点的写入 a=2 没有影响NodeB的执行的顺序,所有NodeB 读取a的值是原来NodeB中的 a=1。总结来说,顺序一致性保证了本地时钟的基准下,本地操作顺序的一致,全局上就像所有的操作在"一定顺序"下执行。顺序一致性比线性一致性的“弱”,主要体现在顺序一致性只保证本地写操作的顺序,不一定要严格遵守全局的写顺序,而线性一致性具有全局时间的概念,是对全局的读+写的进行顺序处理。
比顺序一致性更加松散的一致性模型是因果一致性 。因果一致性保证了有因果关系的事件的一致性,对于没有因果关系的事件则允许并发情况的不一致,也不会考虑“非因果关系”操作的顺序性。
因果一致性只需要满足:
- 对本地操作执行顺序是满足因果顺序的;
- 对于全局的顺序上,对于读写顺序有因果关系的操作,需要保证读写操作的顺序,也即“写a->读a ; 写a,b->读a,b”;
- 闭包传递,"a->b,b->c"则一定 “a->c”。 "->"代表“happens before”。
如下图示意,满足因果一致性,但不满足顺序一致性的情况。
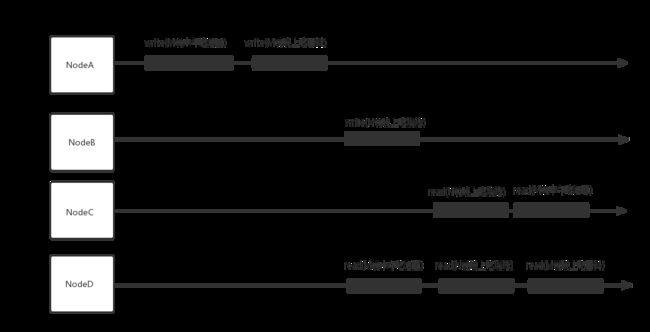
图中的"因果关系"是,“M要先吃中饭再吃晚饭”。但是"N"是另外一个人,跟M吃饭没有因果关系。所以NodeC,NodeD读取结果,对于M的因果顺序是需要保证先知道M中午吃什么,才知道M晚上吃什么,至于N的晚饭吃的时间点跟M吃饭时间点,这个顺序可能对于不同的Node读取的结果不同。但如果要满足顺序一致性,则需要保证所有节点都以一致的顺序执行。而图中NodeC 和NodeD 明显读到的顺序不一致。
实现
满足顺序一致性的一定满足因果一致性。在实践领域,顺序一致性需要所有的写操作有序。对于分布式的存储系统来说,如果是“单主写入”的集群,可以通过“复制日志”保证所有从节点写入顺序一致性,对于“多主写入”的情况,则需要使用一些处理写冲突的方式,忘了的同学可以回顾下03章 数据复制-多主复制的问题。
在分布式微服务系统的实践方面,实现顺序一致性的代价还是很高的。所以在特定场景下,可以使用一些方式实现因果一致性。因果一致性是在有网络延迟的场景下,兼顾性能和可用性的,最强的一致性了。而且一般实现方式也很易理解,如果读者还记得第1章 分布式系统的问题的内容,便知道,使用逻辑时钟可实现因果一致性。比如 微信朋友圈的评论功能 的实现:A发了朋友圈,B评论,C评论,这两者的评论顺序无所谓,但是A回复B则必须读取到B先评论,然后A回复B的评论。微信朋友圈即通过向量时钟 Vector clock实现了因果一致性。
在NoSQL领域,比如 Neo4j图形数据库,通过Raft算法,以及读写节点分离,实现了多写节点(Neo4j中叫Core节点)集群的因果一致性。
最终一致性 (Eventual consistency)
最终一致性是最弱的一致性模型,也即停止写入数据后,最终所有节点的数据都会保持一致。
目前大多数的NoSQL存储集群比如Cassandra、Dynamo、Redis 都是提供了 最终一致性。尤其对于一些k-v数据存储来说,数据之间很少产生强一致性关联或者因果关系。NoSQL相较于一致性,更多是关注性能和高可用性。
在分布式事务的实践方面,一般也都是使用最终一致性模型,满足BASE理论。最终一致性的实践会在下一章介绍。
对比一致性模型
几个一致性模型中,只有线性一致性是全局顺序的。顺序一致性,因果一致性都不是总顺序,而是局部顺序。下面再总结对比下几个模型的概念:
- 线性一致性:所有的操作都有全局的顺序,分布式的节点的操作就像在单机实例中执行。基于全局时钟。
- 顺序一致性:所有的写操作以一定的顺序,而这个顺序是没有绝对的时间概念的。所有节点的操作顺序分别是一致的。
- 因果一致性:有因果关系的操作是有序的,比如"写后读(RAW read after write)",类似happens-before关系。但如果是并发的操作,则是不可比较的。基于逻辑时钟。
- 最终一致性:大多系统一般为了获得高可用性,而使用最终一致性,适合于NoSQL存储集群以及分布式应用系统的实践。
小结
本文介绍了一些分布式技术背后的一致性理论。比如Dymamo实现了AP,Zookeeper实现了CP,基于2PC协议的传统关系型数据库如Mysql实现了CA。BASE理论更多应用于NoSQL的分布式集群中,所以NoSQL集群一般可以线性扩展并且能得到更好的性能。随后,本文也介绍了Flp不可能结果,知道了异步的系统模型下,在单个节点崩溃的情况下无法实现分布式共识,FLP相较于 CAP和BASE的实践性,其更多被使用于一些共识算法的证明论文里。
本文下半部分介绍了分布式一致性模型,CAP中的 “C” 是强一致模型。BASE中的 “E” 是最终一致性模型。同时,区别了一些概念:事务隔离主要是为了解决并发事务的竞争条件。一致性是为了解决在延迟和错误时,协调 “从节点”(Slaves)的状态,常用于分布式存储集群的“数据复制”方案。
本文还介绍了分布式计算的不同的一致性模型的概念。理解这些一致性模型可以有助于理解分布式场景下的顺序,以及一些不同模型导致的弱一致性现象。知道了从底层存储体系,到一些技术框架的"可能"以及"不可能"。一致性和共识是两个分布式领域的重要概念。下一篇将结合本文的一致性模型介绍分布式事务的实践。
资料
Distributed systems for fun and profit
Consensus/ FLP Impossibility/ Paxos/ Byzantine General Problem/ Authenticated Broadcast
A Brief Tour of FLP Impossibility
Consul Gossip
Dynamo: Amazon’s Highly Available Key-value Store
Consensus Protocols: Paxos
Neo4j ACID vs BASE