Pyspider学习
简介
国人编写的强大的网络爬虫系统并自带强大的WebUI,采用Python语言编写吗,分布式架构。支持多种数据库后端
pyspider中文网站:http://www.pyspider.cn/
源码网址:https://github.com/binux/pyspider
官方文档: http://docs.pyspider.org/
安装:
Phantomjs安装 :
phantomjs下载地址:http://phantomjs.org/download.html
下载编译好的压缩包解压缩即可
Pyspider安装:
pip install Pyspider
安装显示界面:

启动 Pysider
pyspider all
同时可以通过制定 -c jsonfile 来指定启动配置参数:
{
"taskdb": "mysql+taskdb://username:password@host:port/taskdb",
"projectdb": "mysql+projectdb://username:password@host:port/projectdb",
"resultdb": "mysql+resultdb://username:password@host:port/resultdb",
"message_queue": "amqp://username:password@host:port/%2F",
"webui": {
"username": "some_name",
"password": "some_passwd",
"need-auth": true
}
}可能会出现的错误:25555端口被占用

原因:
lsof -i:port查询占用端口的pid
原来phantomjs 在后台已经启动
kill 相应进程再启动 pyspider 错误消失
[@bjzw_19_109 pyspider_pro]# lsof -i:25555
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
phantomjs 120202 root 17u IPv4 810232449 0t0 TCP *:25555 (LISTEN)
[@bjzw_19_109 pyspider_pro]# kill -9 120202
[@bjzw_19_109 pyspider_pro]# lsof -i:25555
[@bjzw_19_109 pyspider_pro]# pyspider
phantomjs fetcher running on port 25555在浏览器访问 http://localhost:5000/
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-03-15 16:22:50
# Project: 120_ask
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://tag.120ask.com/jibing/pinyin/a', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('div.s_m1.m980 a').items():
self.crawl(each.attr.href, callback=self.list_page)
def list_page(self, response):
for each in response.doc('div.s_m2.m980 a').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {
"url": response.url,
"disease_name" : response.doc("div.LogoNav.m980.clears p a:nth-child(2)").text(),
"guake" : [x.text() for x in response.doc("div.p_rbox3 div.p_sibox3b span").items()]
}

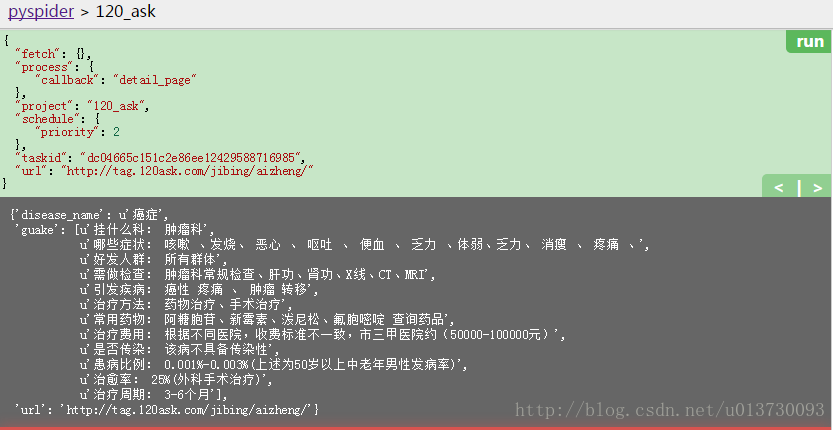
def on_start(self):是方法的入口代码,当在控制台点击run按钮时会调用这个方法
@every(minutes=24*60) 这个设置是告诉scheduler(调度器)on_start方法每天执行一次。
@config(age=10 * 24 * 60 * 60) 这个设置告诉scheduler(调度器)这个request(请求)过期时间是10天,10天内再遇到这个请求直接忽略。这个参数也可以在self.crawl(url, age=10*24*60*60) 和 crawl_config中设置。
上面的例子访问的是静态的地址:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-03-15 19:10:51
# Project: test_AJAX
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0', callback=self.json_parser, validate_cert=False)
@config(priority=2)
def json_parser(self, response):
return [{
"title":x['title'],
"rate": x['rate'],
"url" : x['url']
}for x in response.json['subjects']]
访问ajax类型的:这是需要使用到phantomJS
PhantomJS是一个基于webkit的JavaScript API。它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行JavaScript代码。任何你可以在基于webkit浏览器做的事情,它都能做到。它不仅是个隐形的浏览器,提供了诸如CSS选择器、支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,同时也提供了处理文件I/O的操作,从而使你可以向操作系统读写文件等。PhantomJS的用处可谓非常广泛,诸如前端无界面自动化测试(需要结合Jasmin)、网络监测、网页截屏等。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-03-24 19:31:36
# Project: PhantomJS
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/explore',fetch_type='js', callback=self.phantomjs_parser, validate_cert=False)
def phantomjs_parser(self, response):
return [{
"title": "".join(
s for s in x('p').contents() if isinstance(s, basestring)
).strip(),
"rate": x('p strong').text(),
"url": x.attr.href,
} for x in response.doc('a.item').items()]架构:

组件和组件之间通过消息队列链接,每一个组件都包含了一个消息队列,运行在组件各自的线程或者进程中
组件:
Scheduler
任务优先级
周期定时任务
流量控制
机遇时间周期的重抓取调度
fetcher
method, header, cookie, proxy, etag, last_modified, timeout 等等抓取调度控制
可以通过适配类似 phantomjs 的webkit引擎支持渲染
Phantomjs Fetcher:
phantomjs 的工作过程类似于一个代理,通过javascript抓取和处理抓取过来的页面,并返回正常的HTML
processor
内置的pyquery,以jQuery解析页面【也可用使用自己喜欢的解析工具】
在脚本中完全控制调度抓取的各项参数
可以向后链传递信息
异常捕获
Pyspider的工作流
1:每一个python脚本都会有一个on_start函数,当你在WebUI中点击Run按钮时,一个新的任务就会被递交给调度器,等待执行
2:Scheduler会分发这个task到相应的Fetcher中
3:fetcher会抓取初始化的url并生成一个request和response对象,并传递给Processor
4:Processor调用on_start函数并且传递一下新的url去爬取,但完成一个url的抓取工作时,processor会发送一个消息给Scheduler,告诉调度器这个任务完成。并且会发送一个新的task到scheduler中,同时会把爬取的结果发送到一个result_queue中
5:Scheduler接收到新的task,会判断这个任务是一个新的任务还是需要重新抓取的任务,新的任务会把他们加入到任务队列中,如果是重新需要抓取的任务,则需要看一下时间周期,满足要求的才会放到任务队列中去,并且按顺序分发
6:上面的过程会一直持续,直到程序死掉或者我们手动停止。
关于任务:
每一个task是通过taskid来区别与其他的任务的(默认taskid【md5(url)】),可以通过重写
def get_taskid(self, task) 方法
task有四种状态: active、failed、success、bad-not used
当且仅当task的状态处于active时才能被scheduled调用
失效任务重试:
当任务失败是,任务会默认重试3次
第一次重试是在任务失败的之后的30分钟,1小时,6小时,更多的重试将会被推迟到12小时或者24小时之后
class MyHandler(BaseHandler):
retry_delay = {
0: 30,
1: 1*60*60,
2: 6*60*60,
3: 12*60*60,
'': 24*60*60
}注意:当我们设置了age时,retry的时间不能长于age值
关于工程:
在webUI上会看到5种状态 如下图:
TODO:一个脚本刚刚被创建时的状态
STOP:可以设置stop让项目停止运行
CHECKING:当一个项目在运行是被编辑是会自动的设置成此状态并停止运行
DEBUG/RUNNING :debug和running
爬虫的抓取速度:
rate:每秒执行多少个请求
burst:设置并发数,如 rate/burst = 0.1/3 这个意思是爬虫每10秒执行一个请求,但是前三个任务会同时执行,不会等10秒,第四个任务会等10秒再执行
当我们把group设置为delete并把项目设置为stop状态 24小时 项目会自动删除
self.crawl 接口的几个常用参数:
age:任务的重抓周期: 默认是-1(不在重抓)
@config(age=10 * 24 * 60 * 60)#在10天之内遇到这个任务直接跳过
def index_page(self, response):
…
priority:优先级 默认是0
def index_page(self):
self.crawl('http://www.example.org/page2.html', callback=self.index_page)
self.crawl('http://www.example.org/233.html', callback=self.detail_page, priority=1)auto_recrawl:重抓 默认是False
def on_start(self):
self.crawl('http://www.example.org/', callback=self.callback, age=5*60*60, auto_recrawl=True)params:参数
def on_start(self):
self.crawl('http://httpbin.org/get', callback=self.callback,params={'a': 123, 'b': 'c'})
self.crawl('http://httpbin.org/get?a=123&b=c', callback=self.callback)data
def on_start(self):
self.crawl('http://httpbin.org/post', callback=self.callback, method='POST', data={'a': 123, 'b': 'c'})files:上传文件
{field: {filename: 'content'}}proxy:
目前仅支持http代理
class Handler(BaseHandler):
crawl_config = {
'proxy': 'localhost:8080'
}fetch_type
设置为js开通支持JavaScriptfetcher。默认是None
user_agent、headers、cookies、connect_timeout
Response对象
response.url final url
response.text response 内动,unicode编码
response.content 字节表示
response.doc Pyquery对象
response.json类型
response.status_code
response.orig_url:提交给self.crawl
response.headers
response.cookies
response.time 抓取所需的时间
response.encoding :response.content的编码方式Pyquery
http://www.w3school.com.cn/cssref/css_selectors.asp
1.在pyquery中使用response.doc就可以直接实例化一个pyquery对象,就可以直接在里面使用pyquery方法了,
2.html()和text() ——获取相应的HTML块或文本块,
例:html:"<head><title>hellotitle>head>"
response.doc('head').html()#返回<title>hellotitle>
response.doc('head').text()#返回hello3.根据HTML标签来获取元素,
例:html:'test 1test 2'
response.doc('p')#返回[,]
print response.doc('p')#返回test 1test 2
print response.doc('p').html()#返回test 1注意:当获取到的元素不只一个时,html()、text()方法只返回首个元素的相应内容块
4.eq(index) ——根据给定的索引号得到指定元素
接上例,若想得到第二个p标签内的内容,则可以:
print response.doc('p').eq(1).html() #返回test 2
5.filter() ——根据类名、id名得到指定元素,
例:html:"test 1
test 2
"
response.doc('p').filter('#1') #返回[]
response.doc('p').filter('.2') #返回[] 6.find() ——查找嵌套元素,
例:html:"test 1
test 2
"
response.doc('div').find('p')#返回[, ]
response.doc('div').find('p').eq(0)#返回[] 7.直接根据类名、id名获取元素,
例:html:"<div><p id='1'>test 1p><p class='2'>test 2p>div>"
response.doc('#1').html()#返回test 1
response.doc('.2').html()#返回test 28.获取属性值,
例:html:""
response.doc('a').attr('href')#返回http://hello.com
response.doc('p').attr('id')#返回my_id9.获取内容的一部分可以用分割字符串法:
例:html:"姓名 电话
"
response.doc('#my_tel').text().split(' ')[0]用来取“姓名” response.doc('#my_tel').text().split(' ')[0]用来取“电话”最后再说一个模拟浏览器登陆的例子:
爬取豆瓣读书购物车,必须登录
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-03-28 16:27:57
# Project: crawl_DouBan
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://read.douban.com/account/wishlist', fetch_type='js',callback=self.detail_page,validate_cert=False,method="POST",headers={'User-Agent':'Mozilla/5.0 (iPad; CPU OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1','Host':'read.douban.com',"Accept":"application/json, text/javascript, */*; q=0.01","Connection": "keep-alive","Origin":"https://read.douban.com","Referer":"https://read.douban.com/account/wishlist","X-CSRF-Token":"uY6-","X-Requested-With":"XMLHttpRequest"},cookies={"ll":"108288", "bid":"4wabuJcYPyo","gr_user_id":"8df64966-e4c4-4150-9180-088f5041759b","ct":"y","ps":"y", "_ga":"GA1.2.2060938267.1489561978","gr_cs1_dec6e52e-b09e-4a55-81b6-b70e66983b20":"user_id%3A1","ap":"1","viewed":"26925834_1046265","gr_cs1_29a6eb10-c9ee-42dc-82f9-c6bb8970bcec":"user_id%3A0","ue":"[email protected]","dbcl2":"159629853:vBrocExx16U","ck":"uY6-","_vwo_uuid_v2":"5B069C1533F3E2DAF37D8FFF1F80BB3A|e5878a8eaffcd79cc9e8ea57048e3bf1", "__utma":"30149280.2060938267.1489561978.1490612245.1490687748.8","__utmb":"30149280.31.10.1490687748", "__utmc":"30149280","__utmz":"30149280.1490687748.8.5.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided)","__utmv":"30149280.15962","push_noty_num":"0", "push_doumail_num":"0","_pk_ref.100001.a7dd":"%5B%22%22%2C%22%22%2C1490689343%2C%22https%3A%2F%2Fbook.douban.com%2Fsubject%2F26959159%2F%3Ficn%3Dindex-editionrecommend%22%5D", "gr_session_id_22c937bbd8ebd703f2d8e9445f7dfd03":"7eff0ba3-0e18-490a-97eb-f4ad7f8d01ec","gr_cs1_7eff0ba3-0e18-490a-97ebf4ad7f8d01ec":"user_id%3A1","_ga":"GA1.3.2060938267.1489561978", "_pk_id.100001.a7dd":"ddb145f17d799a99.1490601416.2.1490690002.1490601424.", "_pk_ses.100001.a7dd":"*; _gat=1"})
#"guake" : [x.text() for x in response.doc("div.p_rbox3 div.p_sibox3b span").items()]
@config(priority=2)
def detail_page(self, response):
doc_body = response.doc('body')
account = doc_body('li.more-active a.name.bn-more').text()
book_info_dict = {}
for item in doc_body('section.wishlist tbody tr').items():
book_url = item('td.td-name a').attr.href
book_name = item('td.td-name a').text()
book_price = item('td.td-price span').text()
book_author = item('td span.author').text()
book_info_dict[book_name] = ' '.join([book_url,book_name,book_price,book_author])
return {
"url": response.url,
"account":account,
"book_list": book_info_dict
}