用Python爬取今日头条,里面的东西统统白送!
近年来今日头条做的可谓是风生水起,自上线以来,围绕内容载体和分发方式两个维度不断丰富,至今已衍生出图文、视频、微头条、专栏、搜索、直播等多种内容形式。根据最新中国联通发布的App大数据排行榜,今日头条稳居新闻资讯行业NO.1,活跃用户(MAU)达1.6亿。
面对这样一款内容丰富、具有海量数据的应用App,如果不学会爬取数据,岂不是可惜呢?今天小编以图片数据为例,教你如何爬取今日头条的数据,完整版代码,请在公众号后台回复:头条,如果你还对视频、排行榜等比较感兴趣,可以看之前文章参考。本篇文章你将收获如下技术要点:
- Ajax数据爬取技术
- 进程池
- 容错机制
- 正则表达式
话不多说,以下是具体内容和代码。
网页分析
当对网页进行分析时,我们可能会发现:很多信息都没有出现在源代码里面,比如你刷网页,那些新刷出的网页就是通过Ajax接口加载出来的,这是一种异步加载方式,只有请求这个ajax接口,然后服务器后台收到这个接口信息,才会把数据返回。现在越来越多的网页都是采用这个异步加载的方式,所以爬虫就变得没那么容易了,我们现在直接开始进行网页分析吧!
通过F12我们可以,我们可以发现如下接口中可以找到上述内容
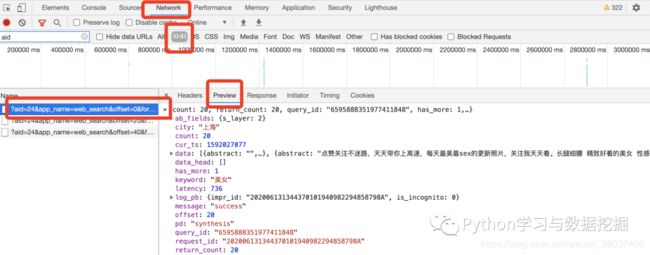
通过网页分析我们可以知道,如果需要把需要对图片保存本地,我们需要进行两次URL的请求,所以在代码中将请求的headers设置为全局变量。
获取数据
首先请求最开始的页面:
https://www.toutiao.com/search/?keyword=%E7%BE%8E%E5%A5%B3
1.获取json数据
我们不能这样直接把页面交给requests库去请求,因为这是一个ajax接口,如果不加入参数,很可能让你输入验证码、拉动验证等反爬措施,我们可以通过加入参数来规避,具体措施如下:
global headers
# headers
headers = {
'cookie': 'WEATHER_CITY=%E5%8C%97%E4%BA%C; csrftoken=6ae2b955b45e59a749e6dc65446acbff; ttcid=9b098a659aa54ff399b6ae76bb252b1e27; SLARDAR_WEB_ID=eb1c77c9-a873-4dbb-8c4c-ac124db1cd6c; UM_distinctid=1fd3813a87ed-0be1183a73772d-30607c00-13c680-171fd3813a9e50; sso_auth_status=d824cbb6753cb805f8a44b6c02e6ec7b; sso_uid_tt=5e677205437e3399c080159feb6a5898; sso_uid_tt_ss=5e677205437e3399c080159feb6a5898; toutiao_sso_user=d91c1fbc6b932a9a5c2fa9a111a50069; toutiao_sso_user_ss=d91c1fbc6b932a9a5c2fa9a111a50069; passport_auth_status=81fc37a1830449af18032d4b4796a32b%2C09dffc241bb0f3ec6c656177e0cc0bb6; sid_guard=4dabbd1e48fd80ecdc0973fdce2d1b0c%7C1590904063%7C5184000%7CThu%2C+30-Jul-2020+05%3A47%3A43+GMT; uid_tt=0115b2ab6e9821b54e26ce6c41059d92; uid_tt_ss=0115b2ab6e9821b54e26ce6c41059d92; sid_tt=4dabbd1e48fd80ecdc0973fdce2d1b0c; sessionid=4dabbd1e48fd80ecdc0973fdce2d1b0c; sessionid_ss=4dabbd1e48fd80ecdc0973fdce2d1b0c; _ga=GA1.2.904277146.1590904500; tt_webid=6833011630063027725; tt_webid=6833011630063027725; CNZZDATA1272960458=2004357243-1589089930-https%253A%252F%252Fwww.baidu.com%252F%7C1590932876; __tasessionId=m5pjsml5i1592026825367; s_v_web_id=kbd7o0e4_ERp4SO3y_dOQY_4tb4_8sbP_0AbZGAADrqJ8; tt_scid=eAuATFNHP-crXarEGEJsNDrcAI27CwfojNjh89EE6DQrHcqy2CfAC-YNcpkuMcSv1796',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
'referer': 'https://www.toutiao.com/search/?keyword=%E7%BE%8E%E5%A5%B3',
'x-requested-with': 'XMLHttpRequest'
}
#加入参数
params = {
'aid': ' 24',
'app_name': ' web_search',
'offset': offset,
'format': ' json',
'keyword': ' 美女',
'autoload': ' true',
'count': ' 20',
'en_qc': ' 1',
'cur_tab': ' 1',
'from': ' search_tab',
'pd': ' synthesis',
'timestamp': int(time.time())
}
url = 'https://www.toutiao.com/api/search/content/?' + urlencode(params) # 构造url
url = url.replace('=+', '=') # 网址根本不一样
try:
r = requests.get(url, headers=headers, params=params)
r.content.decode('utf-8')
if r.status_code == 200:
return r.json() # 返回json格式 因为全是字典类型
except requests.ConnectionError as e:
print(e)
2.获取标题和图片网址
def get_image(json): # 获取图片
if json.get('data'): # 如果这个存在
for item in json.get('data'):
if item.get('title') is None:
continue # 如果标题是空值
title = item.get('title') # 获取标题
if item.get('article_url') == None:
continue
url_page = item.get('article_url')
# print(url_page)
rr = requests.get(url_page, headers=headers)
if rr.status_code == 200:
pat = ''
match = re.search(pat, rr.text, re.S)
if match != None:
result = re.findall(r'img src=\\"(.*?)\\"', match.group(), re.S)
yield {
'title': title,
'image': result
}
3.图片保存
def save_image(content):
path = '/Users/******/' # 路径
if not os.path.exists(path):
os.mkdir(path)
os.chdir(path)
else:
os.chdir(path)
if not os.path.exists(content['title']):
if '\t' in content['title']:
title = content['title'].replace('\t', '')
os.mkdir(title + '//')
os.chdir(title + '//')
print(title)
else:
title = content['title']
os.mkdir(title + '//')
os.chdir(title + '//')
print(title)
else: # 如果存在
if '\t' in content['title']:
title = content['title'].replace('\t', '')
os.chdir(title + '//')
print(title)
else:
title = content['title']
os.chdir(title + '//')
print(title)
for q, u in enumerate(content['image']): # 遍历图片地址列表
u = u.encode('utf-8').decode('unicode_escape')
# 先编码在解码 获得需要的网址链接
# 开始下载
r = requests.get(u, headers=headers)
if r.status_code == 200:
with open(str(q) + '.jpg', 'wb') as fw:
fw.write(r.content)
print(f'该title----->下载{q}张')
加入容错机制
def main(offset):
json = get_page(offset)
get_image(json)
for content in get_image(json):
try:
# print(content)
save_image(content)
except FileExistsError and OSError:
continue
4.多进程爬取
pool = Pool()
groups = [j * 20 for j in range(8)]
pool.map(main, groups)
pool.close()
pool.join()
成果展示
通过上述几步,小编已经将今日头条的数据爬取下来了。实践出真知,实操起来慢慢体会爬虫过程中的要点和注意点,对其他网页的分析和爬取会有益处,不建议拿了代码爬一下就结束了。
更多精彩内容,关注微信公众号『Python学习与数据挖掘』
