知识图谱_关系抽取_文献笔记(二)
本文介绍一篇18年EMNLP的文章Neural Relation Extraction via Inner-Sentence Noise Reduction and Transfer Learning。对知识图谱关系抽取前世了解一下,再来看今天的文章哦。还需了解一下用神经网络做依存句法分析。
一、问题描述
这篇文章是做知识图谱中的关系抽取的,创新点有三个:
1. 通过Sub-Tree Parse (STP)来移除句子内的噪音的,还可以降低句子长度。
2. 通过entity-wise attention来帮助句子捕捉句子内的重点的。
3. 通过迁移学习,在entity type分类上预训练后,再迁移到关系分类的任务上帮助模型提高鲁棒性。
看不懂没关系,下面会一一介绍。
二、什么是句子内的噪音
先来看一个句子:
[It is no accident that the main event will feature the junior welterweight champion miguel cotto, a puerto rican, against Paul Malignaggi, an Italian American from Brooklyn.]
其实光看橘色的部分就知道Paul Malignaggi出生在Brooklyn,也就是/people/person/place of birth关系,那么除了橘色部分的其他单词都是句子内噪音啦,多余的哎!
三、为什么从实体种类识别迁移学习有用呢
先来看一个句子:
[Alfead Kahn, the Cornell-University economist who led the fight to deregulate airplanes.]
如果不知道Alfead Kahn是个人,不知道Cornell-University是公司,还不好预测关系呢。
四、模型架构

可以看到先将句子用 STP处理以后,将其转化为词向量后,输入到双向GRU内转化为hidden state,然后利用entity-wise attention+Hierarchical-level Attention(Word-level Attention和Sentence-level Attention的综合)后将包含一个实体对的所有句子转化为一个向量,然后将这个向量经过全连接和softmax就可以做entity type分类或者关系分类了。
1.Sub-Tree Parse (STP)
先画出句子的依存句法关系树,找到两个实体最近的共同祖先(非自身),以该祖先为根将子句法树提取出来即可,则该子树的单词啦,单词位置啦都可以作为输入了,我觉得这招很高!
举个例子,看上图,有个句子:
[In 1990, he lives in Shanghai, China.]
实体为Shanghai和China,看图中他们的共同祖先为in,则橘色部分in Shanghai, China就被提取出来,这三个单词的word和position就要被换成词向量输入到双向GRU中了。
这个方法比Shortest Dependency Path (SDP)好,在SDP中,上述句子因为Shanghai和China在句法树中直接相连,则最短嘛,就是提取出Shanghai, China。没有“in”了,但in这个单词才是预测这个关系最重要的单词,但是被SDP忽略了,但是在STP中就被保留了。
2.word an position embedding
包含一个实体对的所有句子叫包,一个包内的第 条句子的第
条句子的第 个单词的词向量为
个单词的词向量为 维,记为
维,记为![]() ,分别和两个实体的距离对应的向量为
,分别和两个实体的距离对应的向量为 维,记为
维,记为![]() 和
和![]() ,将三者连起来就是该单词对应的下一步的输入啦
,将三者连起来就是该单词对应的下一步的输入啦![x _ { i j } = \left[ x _ { i j } ^ { w } ; x _ { i j } ^ { p 1 } ; x _ { i j } ^ { p 2 } \right]](http://img.e-com-net.com/image/info8/27e9dc6f97c14fe79424dfd5d36b537b.gif)
3.entity-wise attention
经GRU处理过的第条句子的第 个单词对应位置的hidden state为
个单词对应位置的hidden state为![]() 。entity-wise attention给每个单词赋予一个权重,如果该单词是两个实体之一,则该权重为1,否则为0.
。entity-wise attention给每个单词赋予一个权重,如果该单词是两个实体之一,则该权重为1,否则为0.
![]()
4.Word-level Attention
Word-level Attention也是给每个单词赋予一个权重。
其中![]() 和
和![]() 是要学习的参数。
是要学习的参数。
将每个单词的entity-wise attention权重和Word-level Attention权重相加,就是这个单词的权重。将各个单词对应的hidden state按权重相加就是第条句子的context啦。如果只用Word-level Attention则把实体的重要性削弱了,其实entity-wise attention就是把实体的权重增加了1而已啦,如果只用entity-wise attention也不好,因为其他单词也包含了信息。
5.Sentence-level Attention
Sentence-level Attention是给每个句子赋予一个权重。

其中 和
和![]() 是要学习的参数。
是要学习的参数。
将各个句子对应的context按权重相加就是这个包的context啦。
![]()
6. 全连接+softmax
![]()
7.迁移学习
我们先从实体1类型分类和实体2类型分类学习通用参数,然后这些通用参数来初始化关系分类任务的通用参数。那么哪些是通用参数,哪些是和任务相关的参数呢。
![]()
其中所有任务的所有参数为 ,通用参数为
,通用参数为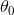 ,实体1类型分类的相关参数为
,实体1类型分类的相关参数为![]() ,实体2类型分类的相关参数为
,实体2类型分类的相关参数为![]() ,关系分类任务的相关参数为
,关系分类任务的相关参数为![]() 。
。
可以看出任务相关参数为attention、全连接层的参数。也就是说基本上只有GRU及以前的参数才是通用参数。
预训练(实体1类型分类和实体2类型分类)的目标函数为
关系分类任务的目标函数为
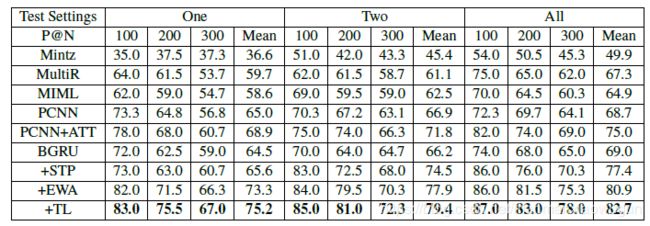
五、实验结果
因为freebase的实体对会提供实体type(种类),所以我们光用NYT数据集就能完成迁移学习。
1.STP有效
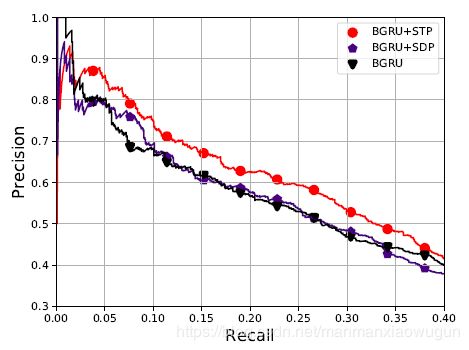
2. entity-wise attention有效,但不能只有entity-wise attention,还要有Word-level Attention,因为实体之外的其他单词也包含了信息。
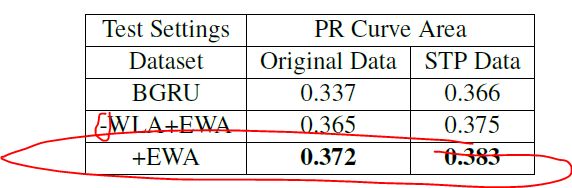
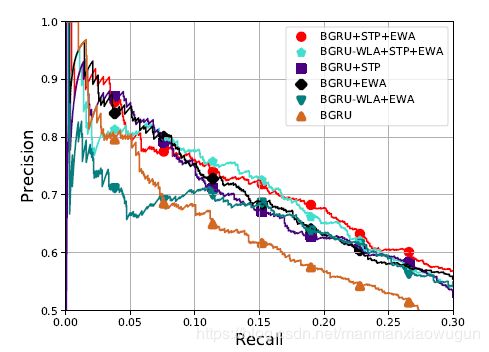
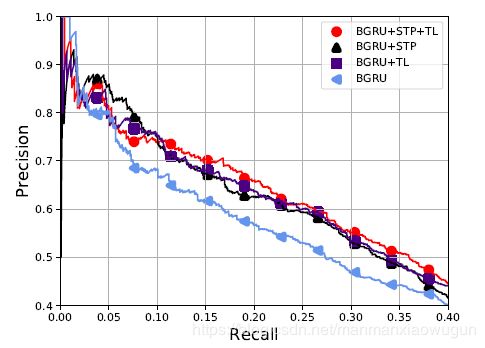
3. 迁移学习有效
4.和关系抽取的其他方法对比

不管训练的时候用包内的一个句子、两个句子还是所有句子,都是本文所提方法效果最好。