Spark-集群安装、部署、启动、测试(1.6.3)稳定版
Spark-集群安装、部署、启动、测试(1.6.3版)
一、下载地址:
http://spark.apache.org/releases/spark-release-1-6-3.html
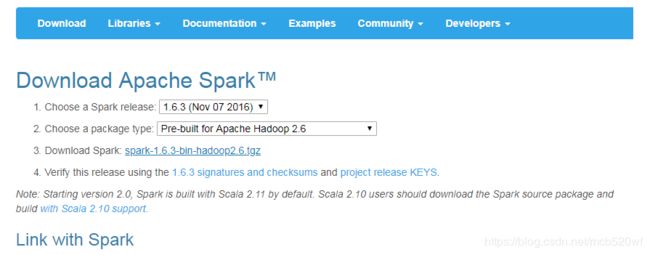
二、安装
将其放在Linux的目录中,解压
我解压的目录是:
/usr/local/spark-1.6.3-bin-hadoop2.6
三、配置spark
3.1 进入到spark的安装目录下
cd /usr/local/spark-1.6.3-bin-hadoop2.63.2 进入conf目录重命名并修改spark-env.sh.template
mv spark-env.sh.template spark-env.sh3.3 进入spark-env.sh文件,在配置文件中添加如下配置。
vi spark-env.sh export JAVA_HOME=/usr/java/jdk1.8.0_151/
export SPARK_MASTER_IP=centos01
export SPARK_MASTER_PORT=7077保存退出
3.4 重命名并修改slaves.template
mv slaves.template slaves3.5 进入slaves修改配置,添加子节点所在的位置。
centos01
centos02
MyLinux这几个乃是主机名(备注:已经做了提前的映射,主机名和IP地址要有映射)
3.6 分发到 其他两台服务器
scp -r spark-1.6.3-bin-hadoop2.6/ MyLinux:/usr/local/
scp -r spark-1.6.3-bin-hadoop2.6/ centos02:/usr/local/部署完成。
四、Spark shell启动及提交任务(提前关闭防火墙,service iptables stop)
4.1 进入sbin/进行启动
./usr/local/spark-1.6.3-bin-hadoop2.6/sbin/start-all.sh4.2 进入bin目录,运行脚本 sprak-shell
/usr/local/spark-1.6.3-bin-hadoop2.6/bin(1)单机版:
./spark-shell --master spark:centos01:7077 (2)集群版 (指定内存和cpu核数 ):
./spark-shell --master spark://centos01:7077 --executor-memory 512m --total-executor-cores 2--total-executor-core CPU核数
--executor-memory 内存大小(每个节点)
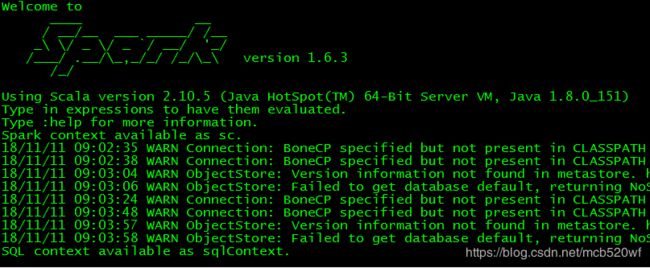
(3)启动结果
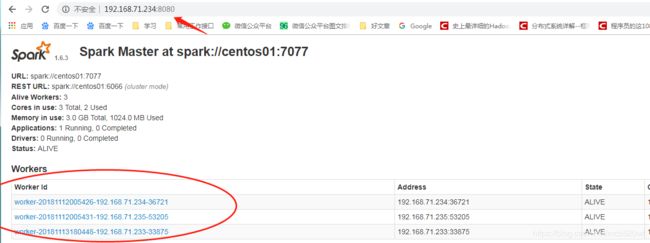
(4)Web UI
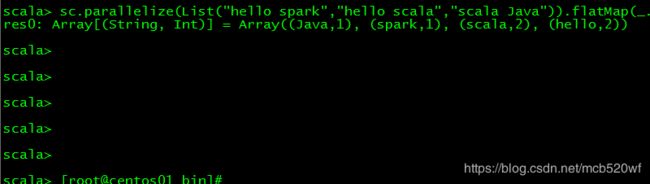
4.3 scala命令做一个简单计数统计
sc.parallelize(List("hello spark","hello scala","scala Java")).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2).collect结果:
没有什么问题~~
欢迎订阅关注公众号(JAVA和人工智能)
获取更多免费书籍、资源、视频资料

文章超级链接:
1,分布式系统详解--基础知识(概论)
2,分布式系统详解--基础知识(线程)
3,IDEA和Eclipse的比较
4,IntelliJ IDEA(最新)安装-破解详解--亲测可用
5,scala-构造器-辅助构造器-伴生对象-单例对象
6,【由浅入深】爬虫技术,值得收藏,来了解一下~
7,Scala-Actor简介并实现WordCount实例
8,Akka 简介及简单原理