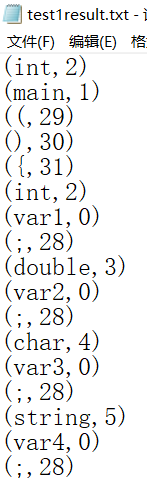词法分析编译原理实验
要求:
定义模拟的简单语言的词法构成,设计词法分析器,要求将用模拟语言书写的源程序进行词法分析,输出单词序列文件和错误信息文件,若有错误,必须输出错误在源程序中行号和列号。
主要参考了文章:词法分析器(分析C语言),对原文代码进行了一定的更改。
原文章理解:
原文通过以下代码从文本中读取代码字符。实验中发现其实不加w!=' '的判定条件也不会读取空格、换行和制表符。读入的字符全都是连在一起的,例如:inta,b;a=1;b=2;对单词的分割不太友好。
原文使用当读入一个字符时判断已有字符串是否与关键字匹配来进行类似inta;这种的分割。但是无法分割do和double这样的关键字,double会在读取2个字符时直接判断成do 。
freopen("s.txt","r",stdin);
freopen("result.txt","w",stdout);
length=0;
while(cin>>w){
if(w!=' '){
letter[length]=w;
length++;
} //去掉程序中的空格
}本文做了一些更改:
1、使用getline()获取代码,读取到的代码保留了空格和制表符,没有换行符,使用空格进行单词划分,更符合直观印象。
2、由于按行提取,可以找到单词所在的行号和列号,可以进行出错提示。
3、增添了字符型常量和字符串常量的划分。
4、将输出结果保存到文本文档中。
其他不足之处:
1、可能有些情况识别时没有考虑到,比如一开始认为标识符中只有字母或数字,后来想到还可能有下划线。其他没有意识到的情况也肯定有。
2、字符识别时不考虑多字符的情况,比如'\ddd'。只考虑了单字符和单字符转义字符。转义字符应该有转义字符表进行匹配比较合适,本文直接只判断了'\'后跟任意字符,可能此字符并没有实际意义。
3、判断'>='这样两个字符的符号时,是判断第一个字符如果是'>''<''!'这样有可能是多字符运算符时再判断下一个是不是'=',才能识别成一个运算符。个人感觉这应该不算一个好方法。
流程:

步骤:
1、对不同的符号划分种别码,其中预留部分数字可作以后添加;
2、从txt文档中读取程序,使用getline()按行获取,存在vector
3、遍历每个字符,使用typeword()函数识别字符种类,共6种情况;
4、针对不同返回值进行不同操作:
1-字母:判断可能是关键字或标识符,读取后面所有是字母或数字的字符,作为一个单词进行判断是关键字或标识符:
2-数字:判断只可能是数字常量,读取后面所有是数字或小数点的字符,作为一个单词判断成数字常量:
3-界符或运算符:判断可能是“>=”这样占两个字符或只占一个字符的运算符,不考虑用户写错的情况,与界符运算符表进行对 照,存储其种别码:
4-字符常量:判断是转义字符或是单字符,不考虑多字符的情况,按字符常量存储:
5-字符串常量:将双引号间的字符全部加入,按字符串常量存储:
6-空格或制表符:略去
5、词法分析结果保存到txt中,关闭文件。
代码:
#include
#include
#include
#include
#include
using namespace std;
#define keynum 9
#define symbolnum 17
//关键字
string key[keynum]={"main","int","double","char","string","if","else","while","return"};
//关键字的种别码
int keyNum[keynum]={1,2,3,4,5,6,7,8,9};
//运算符和界符
string symbol[symbolnum]={"<",">","!=",">=","<=","==",",",";","(",")","{","}","+","-","*","/","="};
//运算符和界符的种别码
int symbolNum[symbolnum]={21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37};
//标识符种别码为0,数字常量为16,字符常量(包括转义字符)为17,字符串常量为18
ifstream myfile ("test1.txt");
ofstream savefile("test1result.txt");
//判断是否为数字
bool isNum(string s){
if(s>="0" && s<="9"||s==".")
return true;
return false;
}
//判断是否为字母
bool isLetter(string s)
{
if((s>="a" && s<="z")||(s>="A"&&s<="Z")||s=="_")
return true;
return false;
}
int isSymbol(string s){ //判断运算符和界符
int i;
for(i=0;i letter;
if (myfile.is_open()){
while (!myfile.eof()){
getline (myfile,line);
letter.push_back(line);//获取一行内容存在vector里
}
int i,j,k;
string word;
for(i=0;i1)//小数点数量大于1报错
//cout<<"(error at:"<'||letter[i][j]=='<'||letter[i][j]=='='||letter[i][j]=='!'){//判断可能是两个字符运算符
if(letter[i][j+1]=='='){//是的进两个
word+=letter[i][j]+'=';
j+=2;
}
else word+=letter[i][j++];//不是进一个
}
else word+=letter[i][j++]; //不是进一个
//cout<<"("<
运行示例:
源代码示例:
int main(){
int var1;
double var2;
char var3;
string var4;
var1=3.5;
var2=2.5.6;//写错可进行报错提示
var3='\n';
var4="hello";
if(var1>=var2){
var1=var1-var2;
}
else{
var1=var2-var1;
}
return 0;
}
结果: