解决sparkstreaming读取kafka中的json数据,消费后保存到MySQL中,报_corrupt_record和name错误的!!
所用软件版本:
spark2.3.0
IDEA2019.1
kafka_2.11-01.0.2.2
spark-streaming-kafka-0-10_2.11-2.3.0
先贴出代码:
package com.bd.spark
import java.util.Properties
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.dstream.InputDStream
object kafkaSparkStreaming_10version {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("kafka-spark-demo").setMaster("local[4]")
val ssc = new StreamingContext(conf, Seconds(5))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "master:9092,salve1:9092,slave2:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "streamingkafka1",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false:java.lang.Boolean)
)
val topics = Array("streaming_kafka")
val stream: InputDStream[ConsumerRecord[String, String]]= KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
val readyData = stream.map(record => record.value()).map(str => str.replace("\"{","{")).map(str => str.replace("}\"", "}")).map(str => str.replace("\\\"", "\""))
readyData.print()
readyData.foreachRDD(rdd => if(!rdd.isEmpty()){
val session = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
val url = "jdbc:mysql://192.168.0.107:3306/kuaishou?useSSL=false&autoReconnect=true&failOverReadOnly=false&rewriteBatchedStatements=true"
val driver = "com.mysql.jdbc.Driver"
val user = "root"
val password = "password"
var table = "highViewVideo"
val prop = new Properties()
prop.setProperty("user", user)
prop.setProperty("password", password)
prop.setProperty("driver", driver)
prop.setProperty("url",url)
import session.implicits._
val DF = session.read.json(session.createDataset(rdd))
DF.filter("view_count > 500000").show(5)
DF.filter("view_count > 500000").write.mode(SaveMode.Append).jdbc(url,"highViewVideo",prop)
}else{ println("=============================Wait A Moment!!!=========================================")})
ssc.start()
ssc.awaitTermination()
}
}爬虫所得到的原始数据如下图所示:

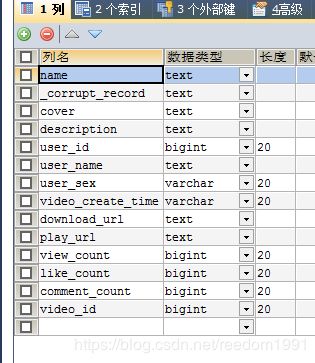
原始数据是一条一条JSON格式数据,两个JSON数据之间是用换行符“\n”隔开,是多行的JSON,用kafka自带的connect-file-source监听该文件,利用上述SparkStreamin程序进行消费,得到的数据导入到MySQL的“kuaishou”’数据库“highViewVideo”表中, 表的格式如下所示
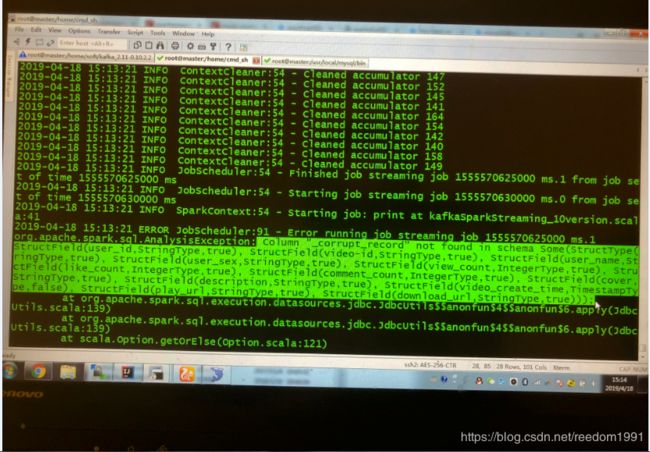
但是DF.filter("view_count > 500000").write.mode(SaveMode.Append).jdbc(url,"highViewVideo",prop)用Append模式导入数据,一直提示如下错误:Column “_corrupt_record” not found in schema Some(Structype...)错误,去网上查询,报_corrupt_record错误,一般都是读取spark读取json文件,由于json文件格式不正确引起。
参考https://blog.csdn.net/a14206149/article/details/51113647和https://blog.csdn.net/qq0719/article/details/86003435两篇文章,采取如下方法:
1:在读取json文件时,指定读取多行为真,option("multiLine", true) 。
2:应该将文件内容"压平"成为平面文件,map(str => str.replace("\n", " "))转换成如下格式:
{"staffList" : {"total" : 3,"result" : [ { "toco" : 41, "id" : 1, "name" : "张三", "typeJoin" : 22, "type" : 2}, { "toco" : 46, "id" : 2, "name" : "李四", "typeJoin" : 22, "type" : 2}, { "toco" : 42, "id" : 3, "name" : "王五", "typeJoin" : 22 ], "type" : 2} ]}}根据上述两种方法进行尝试,问题依旧,还是原来的错误!
但是Append如果改成Overwrite,数据会顺利写到MySQL中,不会出现上述的报错!用google查了全网,依旧没解决!实在没办法,在“highViewVideo”表中添加了“_corrupt_record”字段,报错没有再出现,后续还报Column “name” not found in schema Some(Structype...)错误,在“highViewVideo”表中添加了“name”字段,问题解决!
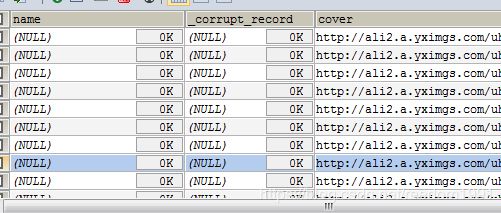
问题解决了,但是百思不得其解:为什么Append模式会报错,Overwrite却不会,而且“_corrupt_record”和“name”两列是我根本没有用到的字段,从哪里冒出来?