python爬虫实例之小说爬取器
今天和大家分享一个爬取盗版小说的实例。
如今的网络小说可谓是百家齐放各领风骚,玄幻科幻穿越修仙都市… 各种套路看得大家是心潮澎湃,笔者曾经也蛮喜欢看小说的,以前经常是拿着一台诺基亚看到深夜,第二天带着黑眼圈去上学。
以前看小说都是txt格式的文件,每次都需要拿着在电脑上搜索‘***txt小说免费下载’,往事不堪回首
学以致用,为了以后下载小说能够超微显得高端一点,今天就给大家分享一个爬取盗版小说的爬虫实例。
当然还是希望大家支持正版哈
这次我选择的网站是笔趣阁,一个可以免费在线看小说的网站,而且貌似可以免费直接下载(手动狗头)
在本实例中我们选择的是孑与2大大的经典之作《唐砖》
点开唐砖我们可以看到是这个样子的
(图片暂无)
查看原码后发现它的目录里面所有章节都存放在一个名为list的div里面,并且所有链接都可以直接访问
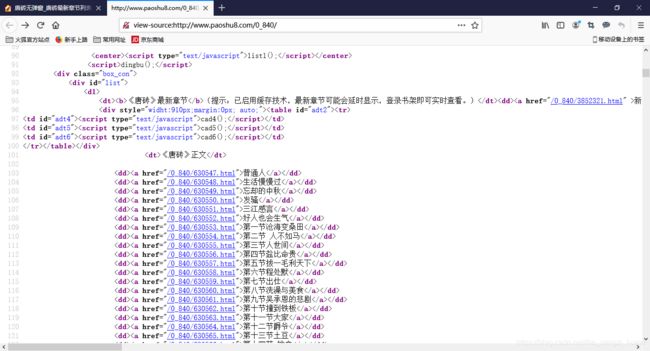
我们先用代码获取它的所有目录信息并存放在两个列表chaptername 和chapteraddress 中
def getchapter(html):
soup = BeautifulSoup(html,'lxml')
try:
alist = soup.find('div',id='list').find_all('a')
for list in alist:
chaptername.append(list.string)
href = 'http://www.paoshu8.com'+list['href']
chapteraddress.append(href)
return True
except:
print('未找到章节')
return False
这样我们就得到了所有的章节信息,接下来只要遍历链接地址就可以得到每一节的详细内容
在每一节详细内容中我们发现,小说的文字都存放在了一个名为content的div里面,我们只需利用BeaufulSoup里面的find函数就可以找到这个div,并且我们可以看到,他的文字都是存放在了p标签里面,所以接下来我们再利用find_all函数找到div里面的所有p标签便可。
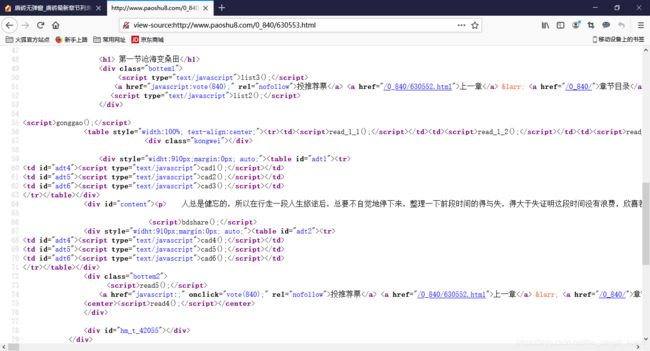
在这次爬虫中,我遇到的一个问题就是在小说中遇见了两个特殊符号,比如说’\u30fb’,’\u2660’,对于这样的错误,我直接用replace替代了这些特殊符号,最终不算很完整的爬完了整部小说。

下面上代码:
import requests
from bs4 import BeautifulSoup
import time
start = time.clock()
#获取页面html源码
def getpage(url):
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
page = requests.get(url).content.decode('utf-8')
return page
chaptername = [] #存放小说章节名字
chapteraddress = [] #存放小说章节地址
#获取小说所有章节以及地址
def getchapter(html):
soup = BeautifulSoup(html,'lxml')
try:
alist = soup.find('div',id='list').find_all('a')
for list in alist:
chaptername.append(list.string)
href = 'http://www.paoshu8.com'+list['href']
chapteraddress.append(href)
return True
except:
print('未找到章节')
return False
#获取章节内容
def getdetail(html):
soup = BeautifulSoup(html,'lxml')
try:
content = ' '
pstring = soup.find('div',id='content').find_all('p')
for p in pstring:
content += p.string.replace('\u30fb','').replace('\u2660','') #这是整个代码最简陋的地方,有可能出现各种的特殊符号中断程序,如果每次都需要replace的话太麻烦了
content += '\n '
return content
except:
print('出错')
return '出错'
url = 'http://www.paoshu8.com/0_840/'
html = getpage(url)
getchapter(html)
file = open('C:/Users/Lenovo/Desktop/fiction.txt','w') #小说存放在本地的地址
count = len(chapteraddress)
for i in range(len(chapteraddress)):
curl = str(chapteraddress[i])
chtml = getpage(curl)
content = '\n' + getdetail(chtml) + '\n' #为了保持小说有格式
title = '\n 第'+str(i+1)+'章 '+str(chaptername[i])+' \n'
file.write(title+content)
print('{:.3%}'.format(i/count)+' '+chaptername[i])
file.close()
end = time.clock()
print('下载完毕,总耗时',end-start,'秒')
以上代码还有很多地方需要完善。比如说每次下载小说的话都得先去小说网站查看网址才能进行下载,比较麻烦,所以我稍微进行了些修改,让程序仅需输入名字便可爬取网站里面任何小说。
import requests
from bs4 import BeautifulSoup
import time
import codecs
start = time.clock()
#在小说大全界面获取所有小说名单
novellist = {}
def getnovels(html):
soup = BeautifulSoup(html,'lxml')
list = soup.find('div',class_='novellist').find_all('a')
baseurl = 'http://www.paoshu8.com'
for l in list:
novellist[l.string] = baseurl+str(l['href']).replace('http:','')
#获取页面html源码
def getpage(url):
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
page = requests.get(url).content.decode('utf-8')
return page
chaptername = [] #存放小说章节名字
chapteraddress = [] #存放小说章节地址
#获取小说所有章节以及地址
def getchapter(html):
soup = BeautifulSoup(html,'lxml')
try:
alist = soup.find('div',id='list').find_all('a')
for list in alist:
chaptername.append(list.string)
href = 'http://www.paoshu8.com'+list['href']
chapteraddress.append(href)
return True
except:
print('未找到章节')
return False
#获取章节内容
def getdetail(html):
soup = BeautifulSoup(html,'lxml')
try:
content = ' '
pstring = soup.find('div',id='content').find_all('p')
for p in pstring:
content += p.string
content += '\n '
return content
except:
print('出错')
return '出错'
url = 'http://www.paoshu8.com/xiaoshuodaquan/' #小说大全网址
html = getpage(url)
getnovels(html) #获取小说名单
name = input('请输入想要下载小说的名字:\n')
if name in novellist:
print('开始下载')
url = str(novellist[name])
html = getpage(url)
getchapter(html)
file = codecs.open('C:/Users/Lenovo/Desktop/novellist/'+name+'.txt','w','utf-8') #小说存放在本地的地址
count = len(chapteraddress)
for i in range(len(chapteraddress)):
curl = str(chapteraddress[i])
chtml = getpage(curl)
content = '\n' + getdetail(chtml) + '\n' #为了保持小说有格式
title = '\n 第'+str(i+1)+'章 '+str(chaptername[i])+' \n'
file.write(title+content)
print('{:.3%}'.format(i/count)+' '+chaptername[i])
file.close()
end = time.clock()
print('下载完毕,总耗时',end-start,'秒')
else:
print('未找见该小说')
运行截图:
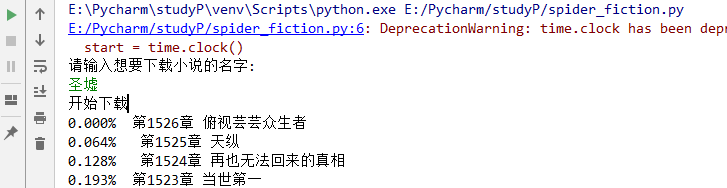
这是单线程版本的爬取器,如果想要加快下载速度,可以用多线程:python爬虫实例之——多线程爬取小说
以上便是本篇小说下载器的所有内容,祝愿我们共同进步,也希望我们早日打赢这场战疫!