原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/)
上篇博客讨论了Spark Streaming 程序动态生成Job的过程,并留下一个疑问: JobScheduler将动态生成的Job提交,然后调用了Job对象的run方法,最后run方法的调用是如何触发RDD的Action操作,从而真正触发Job的执行的呢?本文就具体讲解这个问题。
一、DStream和RDD的关系
DSream 代表了一系列连续的RDD,DStream中每个RDD包含特定时间间隔的数据,如下图所示:
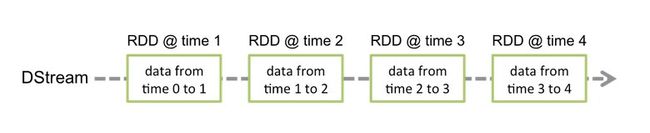
从上图可以看出,
一个DStream 对应了时间维度上的多个RDD。
DStream 作为Spark Stream的一个基本抽象,提供了高层的API来进行Spark Streaming 程序开发,先看一个简单的Spark Streaming的WordCount程序实例:
object WordCount{def main(args:Array[String]):Unit={val sparkConf =newSparkConf().setMaster("local[4]").setAppName("WordCount")val ssc =newStreamingContext(sparkConf,Seconds(1))val lines = ssc.socketTextStream("localhost",9999)val words = lines.flatMap(_.split(" "))val wordCounts = words.map(x =>(x,1)).reduceByKey(_+_)wordCounts.print()ssc.start()ssc.awaitTermination()}}
我们会发现对DStream的操作和RDD的操作惊人的相似, 通过对DStream的不断转换,形成依赖关系。所以的DStream操作最终会转换成底层的RDD的操作,上面的例子中
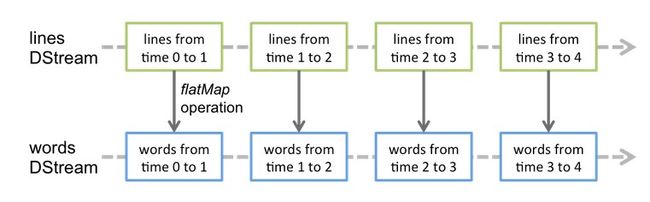
lines DStream转换成wods DSteam。
lines DStream的
flatMap操作会作用于其中每一个RDD去生成words DStream 中的RDD, 过程如下图所示:
下面从源码角度看一下
DStream和RDD的关系:
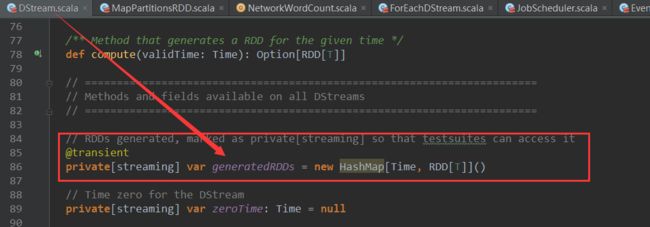
DStream 中 有一个HashMap[Time,RDD[T]]类型的对象 generatedRDDs,其中Key为作业开始时间,RDD为该DStream对应的RDD,源码如下:
二、Dstream 的分类
Dstream 主要分为三大类:
1. Input DStream
2.
Transformed DStream
3. Output DStream
2.1 InputDStream 是DStream 最初诞生的地方,也是RDD最初诞生的地方,它是依据数据源创建的最初的DStream,如上面例子中的代码:
val lines
=
ssc
.
socketTextStream
(
"localhost"
,
9999
)
基于Socket数据源创建了
SocketInputDStream对象lines,下面从源码角度分析一下他是怎么生成RDD的,
SocketInputDStream生成RDD的方法在
它的父类ReceiverInputDSteam中:
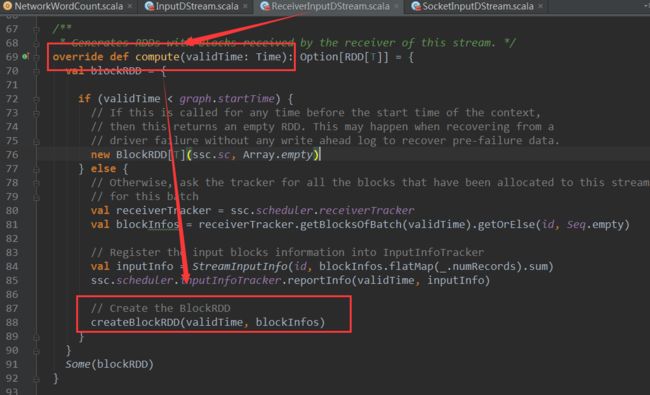
ReceiverInputDSteam
的compute方法中调用了createBloackRDD方法基于Block信息创建了RDD :
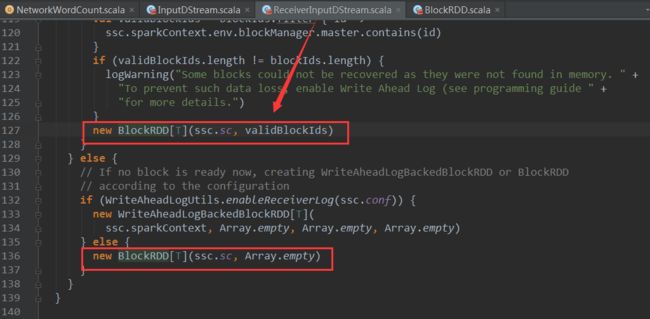
可以看到
ReceiverInputDSteam 的
createBloackRDD 方法new了BlockRDD对象,BlockRDD 是继承自RDD。至此,最初的RDD创建完成。
2.2、
Transformed DStream 是由其他DStream 通过非Output算子装换而来的DStream
例如例子中的lines通过flatMap算子转换生成了FlatMappedDStream:
val words
= lines.flatMap(_.split(" "))
下面看一下flatMap的源码:
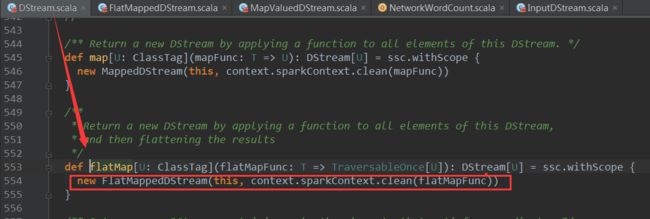
可以看到flatMap是DStream的方法,它创建了FlatMappeedDStream并返回,上面例子中words 就是
FlatMappeedDStream 对象,创建
FlatMappeedDStream对象时传入了
参数flatMapFunc,这里的flatMapFunc就是用户编写的业务逻辑,我们再进入FlatMappedDStream,查看其compute方法:
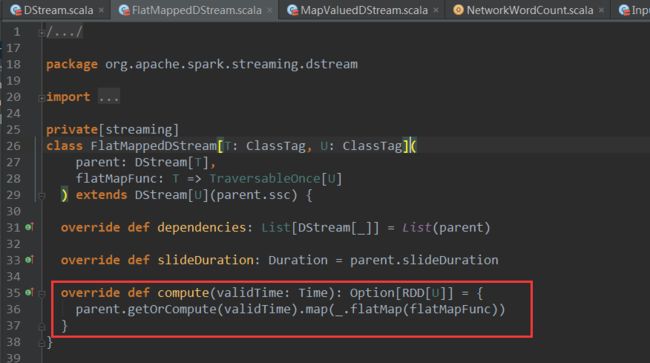
可以惊喜的看到
FlatMappedDStream的compute方法调用了parent的getOrCompute方法获取父DStream的RDD.通过对
父DStream的RDD的flatMap算子生成新的RDD,转换的业务逻辑通过flatMapFunc参数传递给flatMap算子。这样对DStream的操作都转换成了对RDD的操作,同时DSream的依赖关系也与RDD之间依赖关系同时建立了起来。
说明:这些RDD的创建是在Job动态生成时候发生的,Job生成最终会调用ForeachDStream的generateJob方法,源码如下
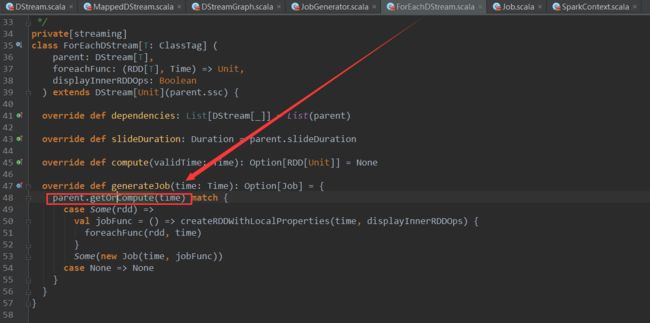
其中的parent.getOrCompute方法会依据DStream之间的依赖关系,导致一系列的链式调用,从而创建所有的RDD,并形成RDD之间的依赖关系。
3.3
Output DStream 是有其他DStream通过Output算子生成,它只存在于Output算子内部,并不会像Transformed Stream一样由算子返回,
他是触发Job执行的关键。
那么什么是Output 算子呢?
Output 算子是让DStream中的数据被推送的外部系统,像数据库,文件系统(HDFS,GFS等)的算子。因为Output 算子是将转换后的数据推送到外部系统被使用的操作,所以他触发了前面转换操作的真正执行(类似于RDD的action操作)。
下面,我们看看有哪些Output算子:
| Output Operation | Meaning |
|---|---|
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream's contents as text files. The file name at each batch interval is generated based onprefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream's contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream's contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". Python API This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
下面,回到我们开头的例子:
wordCounts
.
print
()
其中pirnt算子就是Output算子,我们进入print的源码:
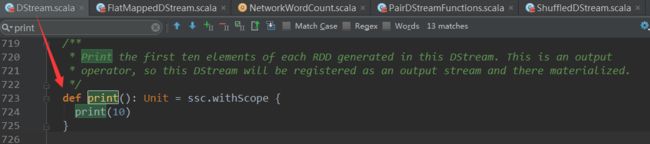
print()方法调用了print(10),其实是调用了另一个print方法:
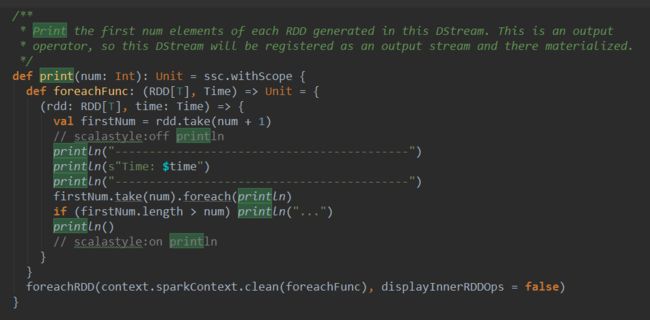
print 方法中首先定义了一个函数foreachFunc,foreachFunc从rdd中出去num个元素打印出来。接下来print函数调用了foreachRDD,并将foreachFunc的处理逻辑作为参数传入。这里的foreachRDD也是一个Output算子(上面已经有说明),接下来看看
foreachRDD的源码。

可以看到foreachRDD中创建了一个ForeachDStream对象,这就是我们期待已久的Output DStream。这里需要注意一个关键点:
创建完ForeachRDD对象后,调用了该对象的register方法。register方法将当前对象注册给DStreamGraph。源码如下:

注册的过程就是将当前对象加入graph的输出流outputStream中:
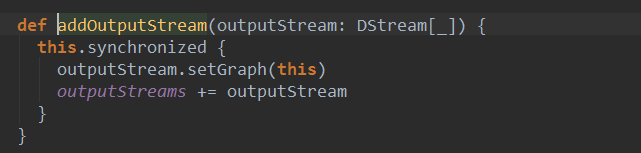
这个过程很重要,在Job触发时候会用到outputStream。我们先在这里记住这个过程,下面的分析会用到这个内容。
至此,DStream到RDD过程已经解析完毕。
三 、由Dstream触发RDD的执行
Spark Stream的Job执行过程我在另一篇博客有详细介绍,具体细节请参考 http://www.cnblogs.com/zhouyf/p/5503682.html
在生成Job的过程中会调用DStreamGraph的generate方法:
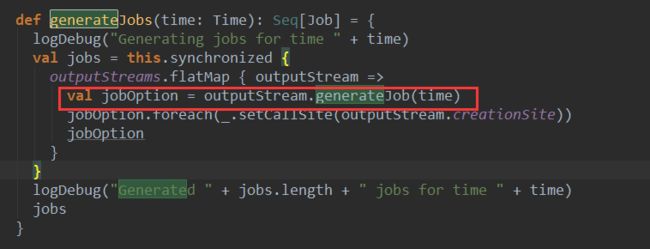
其中,就调用了outputStream的generateJob方法,这里的outputStream就上面有output算子注册给DStreamGraph的输出流。就是我们实例中ForeachDStream 。
ForeachDStream
的generateJob方法源码:
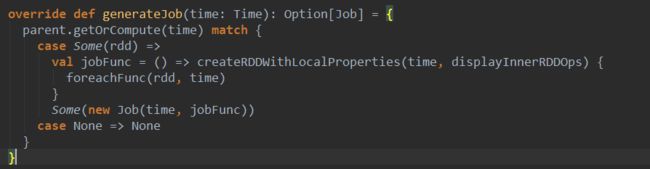
可以看到它将我们的业务逻辑封装成jobFunc传递给了最终生成的Job对象。
由上篇博客《
Spark streaming技术内幕 : Job动态生成原理与源码解析
》
我们知道在StreamContext启动会动态创建job,并且最终调用Job的run方法
Job的run方法由JobScheduler的submitJobSet触发 :
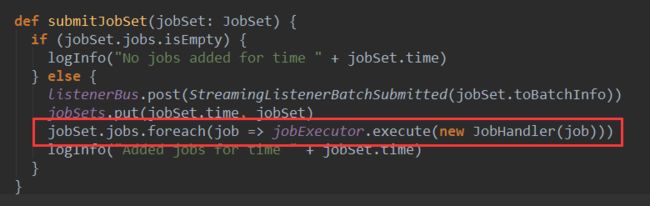
其中jobExecutor对象是一个线程池,JobHandler实现了
Runnable接口,在JobHandler 的run方法中会调用传入的job对象的run方法。在这里Job的run方法开始在线程中执行,JobHandler的run方法源码如下:
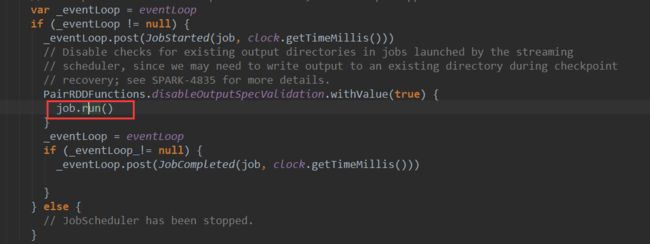
其中的job就是封装了我们业务逻辑的Job对象,它的run方法会触发我们在foreachRDD方法中对RDD的操作(一般是action操作),到这里RDD的Action操作被触发,spark作业开始执行。
总结:
1、在一个固定时间维度上,DStream和RDD是一一对应关系,可以将DStream看成是RDD在时间维度上封装。
2、Dstream 主要分为三大类: Input DStream,Transformed DStream,Output DStream,其中Output Dstream 对开发者是透明的,存在于Output 算子内部。
3、Spark Streaming应用程序最终会转化成对RDD操作的spark 程序,spark 程序由于执行了foreachRDD算子中的RDD操作被触发。
原创文章,转载请注明:
转载自 听风居士博客(
http://www.cnblogs.com/zhouyf/)
备注:
技术顾问 : Spark专家王家林
QQ:1740415547
新浪微博:http://weibo.com/ilovepains/
From WizNote