关键字
集成学习是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。一般情况下,集成学习中的多个学习器都是同质的"弱学习器"。
1、Bagging与Adboost
Bagging算法是集成学习中两大类算法中的其中一个代表算法,还有另一类的经典算法是Adboost。他们主要的区别是前者学习器之间不存在依赖关系和可以并行生成学习器,后者学习器之间存在强依赖关系和可以串行生成学习器。
2、Bagging算法基本流程
Bagging是并行式集成学习方法最著名的代表,基于第2章介绍过的自助采样法,给定包含m个样本的数据集,先随机取出一个样本放入采样集中,再把该样本放入初始数据集,使得下次采样该样本仍可能被选中。经过m次随机采样操作,得到含m个样本的采样集,初始训练集有的样本在采样集中多次出现,有的则从未出现。(自助采样的优点是每个基学习器只使用了初始训练集约63.2%的样本,则剩下约36.8%的样本可作验证集来对泛化性能进行包外估计)
这样,我们可采样出T个含m个样本的采样集,基于每个采样集得出一个基学习器,再将这些基学习器进行结合。在对预测输出进行结合时,Bagging通常对分类任务使用简单投票法,对回归任务使用简单平均法。若分类预测时出现两个类收到同样票数,则最简单的做法就是随机选择一个,也可以进一步考察学习器投票的置信度来确定终胜者。
3、Bagging算法描述

输入为样本集D={(x1,y1),(x2,y2),...(xm,ym)} ,弱学习器算法, 弱分类器迭代次数T。
输出为最终的强分类器f(x)
对于t=1,2...,T:
a)对训练集进行第t次随机采样,每个样本被采样的概率为1/m,共采集m次,得到包含m个样本的采样集Dm
b)用采样集Dm训练第m个弱学习器Gm(x)
如果是分类算法预测,则T个弱学习器投出最多票数的类别或者类别之一为最终类别。如果是回归算法,T个弱学习器得到的回归结果进行算术平均得到的值为最终的模型输出。
由于Bagging算法每次都进行采样来训练模型,因此泛化能力很强,对于降低模型的方差很有作用。当然对于训练集的拟合程度就会差一些,也就是模型的偏倚会大一些。
简单的投票方法
(1): 一票否决
对训练出来的多个方法树计算RMSE(AUC),RMSE最小的话(AUC最大的话),使用该方法树。
(2): 少数服从多数(可以加权)

绝对多数投票法:假设有一半以上的基学习器都预测了类别c,那么此时集成后的学习器给出的预测结果就是c,否则拒绝预测。
相对投票法:这个是选择票数最多的类别,如果最多票数的类别个数大于1,则随机从中选择一个。
(3): 阈值表决
加权平均法
对于简单平均法,其是以如下方式对各个模型进行结合的:
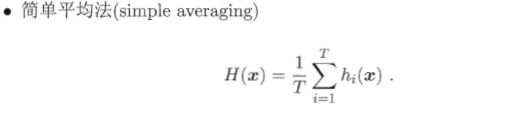
对于加权平均法对各个模型的结合方式如下所示,以该策略进行模型结合的典型算法就是AdaBoost算法

4、Bagging算法代表:随机森林
随机森林是一种多功能的机器学习算法,能够执行回归和分类的任务。同时,它也是一种数据降维手段,用于处理缺失值、异常值以及其他数据探索中的重要步骤,并取得了不错的成效。另外,它还担任了集成学习中的重要方法,在将几个低效模型整合为一个高效模型时大显身手。
在随机森林中,我们将生成很多的决策树,并不像在CART模型里一样只生成唯一的树。(1)当在基于某些属性对一个新的对象进行分类判别时,随机森林中的每一棵树都会给出自己的分类选择,并由此进行“投票”,森林整体的输出结果将会是票数最多的分类选项;(2)而在回归问题中,随机森林的输出将会是所有决策树输出的平均值。
随机森林(Random Forest,RF)是Bagging的一个扩展实体,在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中加入了随机属性选择。假定属性一共有d个,那么RF则在树结点上在随机选择一个包含k个属性的子集。再从其中选择最优。k值一般推荐k=log2d。
随机森林简单、容易实现、计算开销小。在个体学习器之间的差异度增加后泛化性能会进一步提升。但是RF在基学习器较少时,泛化性能通常较差,随着个体学习器的增加,泛化性能会有所改善。
from sklearn.ensemble import RandomForestClassifier
# 建立随机森林分类器
random_forest = RandomForestClassifier(n_estimators = 100, random_state = 50, verbose = 1, n_jobs = -1)
#n_estimators : 指森林中树的个数
#n_jobs : 拟合(fit)和预测(predict)时并行运行的job数目,当设置为-1时,job数被设置为核心(core)数。
# 训练数据集
random_forest.fit(train, train_labels)
#verbose :冗余控制 控制树增长过程中的冗余(verbosity)。
# 提取重要特征
feature_importance_values = random_forest.feature_importances_
feature_importances = pd.DataFrame({'feature': features, 'importance': feature_importance_values})
# 对测试数据进行预测
predictions = random_forest.predict_proba(test)[:, 1]
完整代码查看码云
5、Boosting算法代表:GB、GBDT、xgboost
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类、回归、排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的。本文尝试一步一步梳理GB、GBDT、xgboost,它们之间有非常紧密的联系,GBDT是以决策树(CART)为基学习器的GB算法,xgboost扩展和改进了GBDT,xgboost算法更快,准确率也相对高一些。
1.在机器学习中Xgboost算法和GBDT算法都有利于我们对数据的训练和增加预测值的准确率
2.不是任何数据都适用与Xgboost和GBDT。
3.根据Xgboost和GBDT算法竞赛和工业中使用频繁,并且kaggle竞赛中Xgboost的使用频率最高,数据预测的准确率平均最高,所以我选择学习Xgboost。
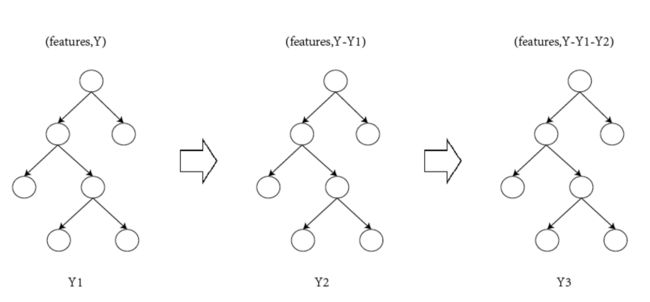
5.1、GB-gradient boosting(梯度推进):

GB的主要模式是迭代生多个(M个)弱的模型 ,然后把预测值相加起来。在我理解中GB算法步骤:γ代表的是权值,通过不断的迭代,使得权值更加贴合,第二步中生成基学习器,将L(Yi,F(xi))进行关于F(xi)的求导,用来计算伪残差(残差-在数理统计中是指实际观察值与估计值(拟合值)之间的差,在这里我暂时理解成误差值),第三步计算最优的权值,然后通过基本线性关系,更新模型。
5.2、Gradient boosting Decision Tree(GBDT):
GB算法中最典型的基学习器是决策树,尤其是CART,正如名字的含义,GBDT是GB和DT的结合。要注意的是这里的决策树是回归树,GBDT中的决策树是个弱模型,深度较小一般不会超过5,叶子节点的数量也不会超过10,对于生成的每棵决策树乘上比较小的缩减系数(学习率<0.1),有些GBDT的实现加入了随机抽样(subsample 0.5<=f <=0.8)提高模型的泛化能力。通过交叉验证的方法选择最优的参数。因此GBDT实际的核心问题变成怎么基于使用CART回归树生成? CART分类树在很多书籍和资料中介绍比较多,但是再次强调GDBT中使用的是回归树。作为对比,先说分类树,我们知道CART是二叉树,CART分类树在每次分枝时,是穷举每一个feature的每一个阈值,根据GINI系数找到使不纯性降低最大的的feature以及其阀值,然后按照feature<=阈值,和feature>阈值分成的两个分枝,每个分支包含符合分支条件的样本。用同样方法继续分枝直到该分支下的所有样本都属于统一类别,或达到预设的终止条件,若最终叶子节点中的类别不唯一,则以多数人的类别作为该叶子节点的性别。回归树总体流程也是类似,不过在每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是GINI系数,而是最小化均方差--即(每个人的年龄-预测年龄)^2 的总和 / N,或者说是每个人的预测误差平方和 除以 N。这很好理解,被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最靠谱的分枝依据。分枝直到每个叶子节点上人的年龄都唯一(这太难了)或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。(CART-Classification And Regression Tree(分类回归树算法))
5.3、Xgboost
Xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。下面公式来自原始paper.
(1). xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。

Ω(fk)正则项(正则化(regularization),是指在线性代数理论中,不适定问题通常是由一组线性代数方程定义的,而且这组方程组通常来源于有着很大的条件数的不适定反问题),而L()为损失函数,T为叶子的个数,w为叶子的权重,γ和λ在最终的模型公式中控制这部分的比重。
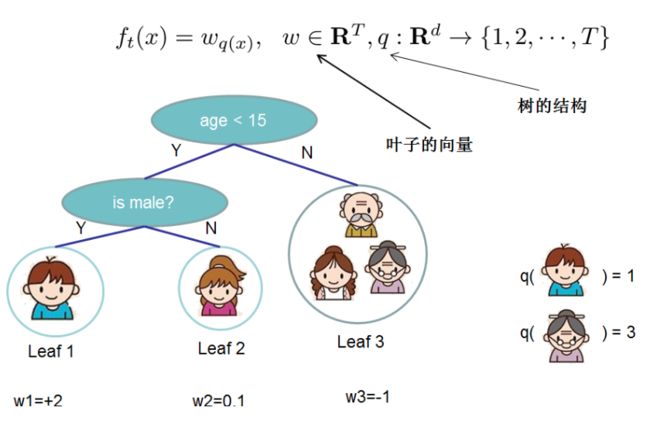
(2). GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数。
第t次迭代的loss:
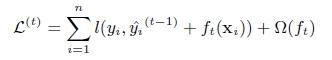
对上式做二阶泰勒展开:g为一阶导数,h为二阶导数
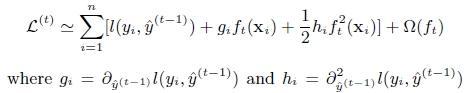
(3). 上面提到CART回归树中寻找最佳分割点的衡量标准是最小化均方差,xgboost寻找分割点的标准是最大化。
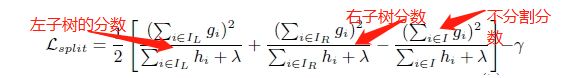
γ为加入新叶子节点引入的复杂度代价。
xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
5.4、官方Xgboost代码
#!/usr/bin/python
import numpy as np
import xgboost as xgb
###
# advanced: customized loss function
#
print ('start running example to used customized objective function')
dtrain = xgb.DMatrix('../data/agaricus.txt.train')
dtest = xgb.DMatrix('../data/agaricus.txt.test')
# note: for customized objective function, we leave objective as default
# note: what we are getting is margin value in prediction
# you must know what you are doing
param = {'max_depth': 2, 'eta': 1, 'silent': 1}
watchlist = [(dtest, 'eval'), (dtrain, 'train')]
num_round = 2
# user define objective function, given prediction, return gradient and second order gradient
# this is log likelihood loss
def logregobj(preds, dtrain):
labels = dtrain.get_label()
preds = 1.0 / (1.0 + np.exp(-preds))
grad = preds - labels
hess = preds * (1.0-preds)
return grad, hess
# user defined evaluation function, return a pair metric_name, result
# NOTE: when you do customized loss function, the default prediction value is margin
# this may make builtin evaluation metric not function properly
# for example, we are doing logistic loss, the prediction is score before logistic transformation
# the builtin evaluation error assumes input is after logistic transformation
# Take this in mind when you use the customization, and maybe you need write customized evaluation function
def evalerror(preds, dtrain):
labels = dtrain.get_label()
# return a pair metric_name, result
# since preds are margin(before logistic transformation, cutoff at 0)
return 'error', float(sum(labels != (preds > 0.0))) / len(labels)
# training with customized objective, we can also do step by step training
# simply look at xgboost.py's implementation of train
bst = xgb.train(param, dtrain, num_round, watchlist, logregobj, evalerror)
完整代码参考码云