《Kotlin从小白到大牛》第17章:Kotlin中函数式编程API
第17章 Kotlin中函数式编程API
为了提供对函数式编程的支持,Kotlin在集合和数组中提供了一些高阶函数,它们的参数和返回类型都是函数类型。因为集合和数组它们都是数据的容器,即按照某种算法实现的数据结构,这些数据在这些函数中“流动”最后输出结果。集合和数组中的这些高阶函数构成了Kotlin函数式编程API,本章介绍这些API。
17.1 函数式编程API与链式调用
函数操控的是数据,数据是放在集合或数组中的,而集合和数组在数学中计算可以分为:遍历、排序、过滤、映射、聚合等等。因此凡是支持函数式编程的语言,它们的函数式编程API都是类似的,如forEach、sort、map、filter、max和count等函数,这些函数在所有函数式编程语言中都是一样的,而且大部函数的命名也是完全一样,只要你熟悉了一个函数的使用,无论换成什么语言用法也是一样的,很容易学习。
函数式编程将用户需求和业务逻辑被抽象成为函数,通过函数的不同组合调用完成复杂的业务逻辑。下面的代码片段是采用函数式编程的链式调用风格实现。
fun getUsers(db: ManagedSQLiteOpenHelper):
List = db.use {
db.select(“Users”)
.whereSimple(“family_name = ?”, “John”)
.doExec()
.parseList(UserParser)
}
getUsers函数中db.select(“Users”).whereSimple(“family_name
= ?”, “John”).doExec().parseList(UserParser)是一条语句,实现了从Users表中查询family_name = John的数据。它就是通过多个函数的组合而实现的,这种多个函数组合就是链式调用,这种链式调用风格如图17-1所示,关注输入和输出,输入数据(通常是集合或数组)通过多个函数的连续计算输出数据(通常也是集合或数组),不修改函数之外的变量,是无状态的。
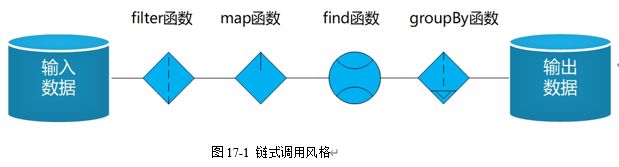
17.2 遍历操作
对数据的操作主要是遍历、过滤、映射和聚合,其中遍历在前面第16章介绍已经介绍过了,但采用方式还是传统的for循环。而函数式编程遍历数据应该使用forEach和forEachIndexed函数。
17.2.1 forEach
forEach函数适用于Collection和Map集合,以及数组,函数只有一个函数类型的参数,实参往往使用尾随形式的Lambda表达式。在执行时forEach会把集合或数组中的每一个元素传递给Lambda表达式(或其他的函数引用)以便去执行。
示例代码如下:
//代码文件:chapter17/src/com/a51work6/section2/ch17.2.1.kt
package com.a51work6.section2
fun main(args: Array) {
val strArray =arrayOf("张三","李四", "王五","董六") //创建字符串数组
val set =setOf(1, 3, 34, 54, 75) //创建Set集合
val map =mapOf(102 to "张三", 105 to "李四", 109 to "王五") //创建Map集合
println("-----遍历数组-----")
strArray.forEach {
println(it)
}
println("-----遍历Set集合-----")
set.forEach {
println(it)
}
println("-----遍历Map集合k,v-----")
map.forEach {k, v -> ①
println("$k - KaTeX parse error: Expected 'EOF', got '}' at position 9: v") }̲ println…{it.key} - ${it.value}")
}
}
输出结果:
-----遍历Set集合-----
1
3
34
54
75
-----遍历Map集合k,v-----
102 - 张三
105 - 李四
109 - 王五
-----遍历Map集合Entry-----
102 - 张三
105 - 李四
109 - 王五
上述代码数组和Set集合的forEach函数的Lambda表达式都只有一个参数,而遍历Map集合时分为两个版本,其中代码第①行的forEach函数的Lambda表达式中有两个参数,第一个参数是集合的键,第二个参数是集合的值。代码第②行的forEach函数的Lambda表达式中有一个参数,这个参数类型是Entry,Entry表示一个键值对的对象,它有两个属性,即key和value。
17.2.2 forEachIndexed
使用forEach函数无法返回元素的索引,如果既想返回集合元素,又想返回集合元素索引,则可以使用forEachIndexed函数,forEachIndexed适用于Collection集合和数组。
示例代码如下:
//代码文件:chapter17/src/com/a51work6/section2/ch17.2.2.kt
package com.a51work6.section2
fun main(args: Array) {
val strArray =arrayOf("张三","李四", "王五","董六")//创建字符串数组
val set =setOf(1, 3, 34, 54, 75) //创建Set集合
println("-----遍历数组-----")
strArray.forEachIndexed { index, value ->
println("$index - $value")
}
println("-----遍历Set集合-----")
set.forEachIndexed {index, value ->
println("$index - $value")
}
}
输出结果:
-----遍历数组-----
0 - 张三
1 - 李四
2 - 王五
3 - 董六
-----遍历Set集合-----
0 - 1
1 - 3
2 - 34
3 - 54
4 – 75
17.3 三大基础函数
过滤、映射和聚合是数据的三大基本操作,围绕这三大基本操作会有很多函数,但其中有三个函数是作为基础的函数:filter、map和reduce。
17.3.1 filter
过滤操作使用filter函数,它可以对Collection集合、Map集合或数组元素进行过滤,Collection集合和数组返回的是一个List集合,Map集合返回的还是一个Map集合。
下面通过一个示例介绍一下filter函数使用,示例代码如下:
//代码文件:chapter17/src/com/a51work6/section3/User.kt
package com.a51work6.section3
data class User(val name: String, var password: String) ①
//测试使用
val users = listOf( ②
User(“Tony”, “12%^3”),
User(“Tom”, “23##4”),
User(“Ben”, “1332%#4”),
User(“Alex”, “ac133”)
)
//代码文件:chapter17/src/com/a51work6/section3/ch17.3.1.kt
package com.a51work6.section3
import com.a51work6.users
//filter函数示例1
fun main(args: Array) {
users.filter {it.name.startsWith(“t”, ignoreCase = true) }
.forEach {println(it.password) } ③
}
输出结果:
12%^3
23##4
filter函数可以过滤任何类型的集合或数组。代码第①行创建数据类User,把它作为集合中的元素。代码第②行是声明users属性,它是保存User对象的List集合。
代码第③行使用链式API处理users集合,这里使用了两个函数filter和forEach。filter函数中的Lambda表达式返回布尔值,true的元素进入下一个函数,false的元素被过滤掉,表达式it.name.startsWith(“t”,
ignoreCase = true)是判断集合元素的name属性是否是t字母开头的,ignoreCase = true忽略大小写比较。filter函数处理完成之后的数据,如图17-2所示,由原来的四条数据编程了现在的两条数据。forEach函数用来遍历集合元素,它的参数也是一个Lambda表达式,所以forEach { println(it.password)}是将集合元素的password属性打印输出。
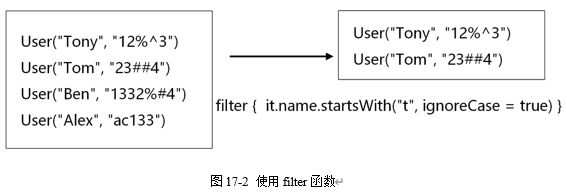
17.3.2 map
映射操作使用map函数,它可以对Collection集合、Map集合或数组元素进行变换返回一个List集合。
下面通过一个示例介绍一下map函数使用,示例代码如下:
//代码文件:chapter17/src/com/a51work6/section3/ch17.3.2.kt
package com.a51work6.section3
fun main(args: Array) {
users.filter {it.name.startsWith(“t”, ignoreCase = true) } ①
.map { it.name } ②
.forEach{ println(it)} ③
}
输出结果:
Tony
Tom
上述代码使用filter函数和map函数对集合进行操作,过程如图17-3所示,代码第①行使用filter函数过滤,只有两元素,元素类型是User对象。代码第②行使用map函数对集合进行变换,it.name是变换表达式,将计算的结果放到一个新的List集合中,从图17-3所示可见,新的集合元素变成了字符串,这就是map函数变换的结果。
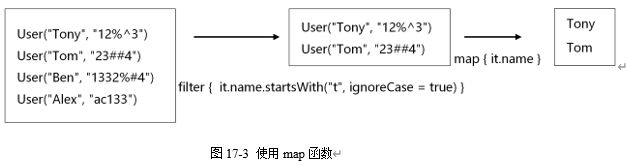
17.3.3 reduce
聚合操作会将Collection集合或数组中数据聚合起来输出单个数据,聚合操作中最基础的是归纳函数reduce,reduce函数会将集合或数组的元素按照指定的算法积累叠加起来,最后输出一个数据。
下面通过一个示例介绍一下reduce函数使用,示例代码如下:
//代码文件:chapter17/src/com/a51work6/section3/Song.kt
package com.a51work6
data class Song(val title: String, val durationInSeconds:Int) ①
//测试使用
val songs= listOf(Song(“Speak to Me”, 90), ②
Song(“Breathe”, 163),
Song(“On he Run”, 216),
Song(“Time”, 421),
Song(“The Great Gig in the Sky”, 276),
Song(“Money”, 382),
Song(“Us and Them”, 462),
Song(“Any Color You Like”, 205),
Song(“Brain Damage”, 228),
Song(“Eclipse”, 123)
)
//代码文件:chapter17/src/com/a51work6/section3/ch17.3.3.kt
package com.a51work6.section3
import com.a51work6.songs
fun main(args: Array) {
//计算所有歌曲播放时长之和
val durations =songs.map { it.durationInSeconds } ③
.reduce{ acc, i -> ④
acc+ i
}
println(durations) //输出:2566
}
为了测试首先声明了一个数据类Song,见代码第①行。代码第②行声明songs属性,它是保存Song对象的List集合。
代码第③行是调用map函数变换songs集合数据,返回歌曲时长(durationInSeconds)的List集合。代码第④行调用reduce函数计算时长,其中acc参数是上次累积计算结果,i当前元素,acc + i表达式是进行累加,这个表达式是关键,根据自己需要这个表达式是不同的。
17.4 聚合函数
虽然17.3节已经介绍了一些基础函数,但对集合和数组的操作还有很多函数,下面再分别介绍一下常用的函数。
首先介绍聚合函数,常用的聚合函数除了reduce还有11个,如表17-1所示。

示例代码如下:
//代码文件:chapter17/src/com/a51work6/section4/ch17.4.kt
package com.a51work6.section4
import com.a51work6.songs
fun main(args: Array) {
val list =listOf(1, 3, 34, 54, 75) //创建list集合
val map =mapOf(102 to "张三", 105 to "李四", 109 to "王五") //创建Map集合
println(list.any { it > 10 }) //true
println(list.all { it > 0 }) //true
println(list.count { it > 10 }) //3
println(list.max()) //75
println(map.maxBy { it.key }) //109=王五
println(list.min()) //1
println(map.minBy { it.key }) //102=张三
println(list.sum()) //167
println(songs.sumBy { it.durationInSeconds }) //2566
println(list.average()) //33.4
println(list.none { it < -1 }) //true
}
17.5 过滤函数
常用的过滤函数数除了filter还有14个,如表17-2所示。
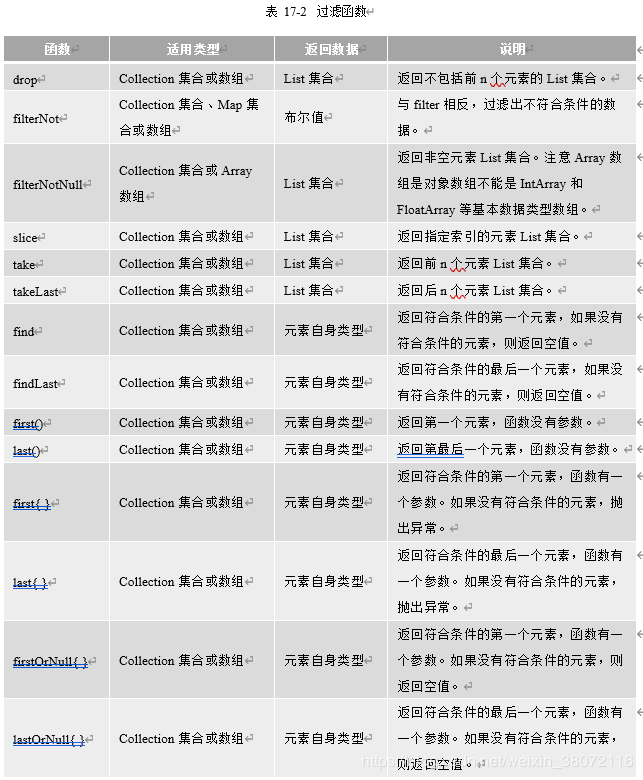
示例代码如下:
//代码文件:chapter17/src/com/a51work6/section5/ch17.5.kt
package com.a51work6.section5
fun main(args: Array) {
val map =mapOf(102 to "张三", 105 to "李四", 109 to "王五")
val array =intArrayOf(1, 3, 34, 54, 75)
val charList =listOf("A", null, "B", "C")
println(array.drop(2)) //[34, 54, 75]
println(map.filter { it.key > 102 }) //{105=李四, 109=王五}
println(map.filterNot { it.key > 102 }) //{102=张三}
println(charList.filterNotNull())//[A, B, C]
println(array.slice(listOf(0,2))) //[1, 34] ①
println(array.take(3)) //[1, 3, 34]
println(array.takeLast(3)) //[34, 54, 75]
println(array.find{ it > 10 }) //34
println(array.findLast{ it < -1 }) //null
println(array.first()) //1 ②
println(array.last()) //75
println(array.first{ it > 10 }) //34 ③
println(array.firstOrNull{ it > 100 }) //null ④
println(array.last{ it > 10 }) //75
println(array.lastOrNull{ it > 100 }) //null
}
上述代码第①行中使用了slice函数,它的参数是要取出的元素索引集合,listOf(0, 2)说明要去的元素是的第一个和第二个元素。代码第②行的first()函数是取出第一个元素。代码第③行的first函数参数是Lambda表达式,在中设置过滤条件。代码第④行的firstOrNull函数与first函数类似,只是遇到没有符合条件时,返回空值。
17.6 映射函数
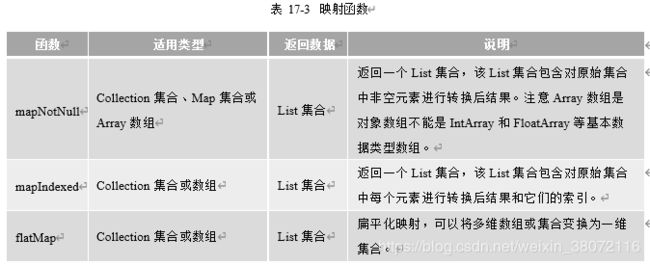
常用的映射函数除了map还有3个,如表17-3所示。
示例代码如下:
//代码文件:chapter17/src/com/a51work6/section6/ch17.6.kt
package com.a51work6.section6
fun main(args: Array) {
val set =setOf(1, 3, 34, 54, 75)
val charList =listOf("A", null, "b", "C")
println(charList.mapNotNull { it }
//[A, b, C] ①
.map {it.toLowerCase() }) //[a, b, c] ②
println(set.mapIndexed { index, s -> index + s }) // [1, 4, 36, 57, 79] ③
val datas =listOf(listOf(10, 20), listOf(20, 40)) ④
val flatMapList= datas.flatMap { e -> e.map { it * 10 } } ⑤
println(flatMapList)//[100, 200, 200, 400]
}
上述代码第①行中使用mapNotNull函数对charList字符串集合进行变换,去除空值元素,然后再通过代码第②行的map函数进行变换,将字母变换为小写字母。
代码第③行中使用了mapIndexed函数,其中index参数是索引,s是集合元素,本例中的变换规则是index + s。
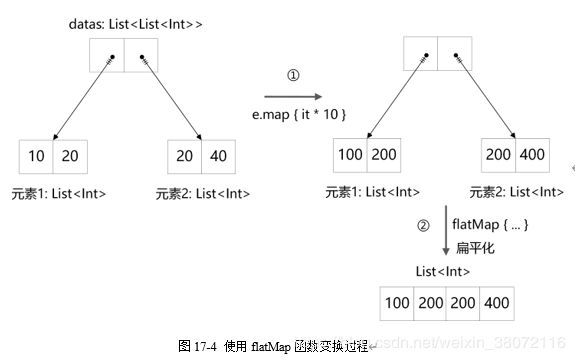
代码第④行定义了嵌套二维List集合(类型为List,它的结构如图17-4所示,datas集合的每一个元素是List类型。代码第⑤行使用flatMap函数首先是扁平化,就是将多维变换为一维,flatMap { e
-> e.map { it * 10 }}变换过程如图17-4所示,先映射变换后进行扁平化,第一步是将两个嵌套集合中的元素进行乘10变换,然后再两两个集合扁平化,即合并为一个集合。
17.7 排序函数
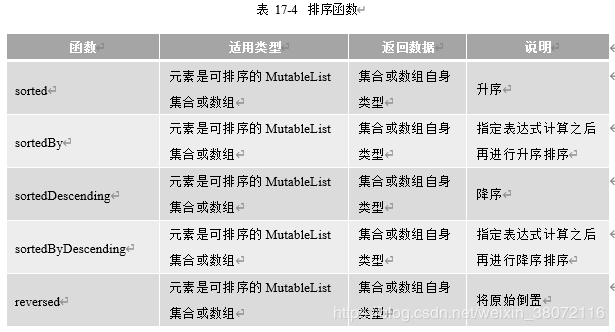
常用的排序函数有5个,如表17-4所示。
示例代码如下:
//代码文件:chapter17/src/com/a51work6/section7/ch17.7.kt
package com.a51work6.section7
import com.a51work6.users
fun main(args: Array) {
val set =setOf(1, -3, 34, -54, 75)
//升序
println(set.sorted())//[-54, -3, 1, 34, 75]
println(“Users升序输出:”)
users.sortedBy{ it.name }.forEach { println(it) } ①
//降序
println(set.sortedDescending())//[75, 34, 1, -3, -54]
println(“Users降序输出:”)
users.sortedByDescending { it.name }.forEach { println(it) } ②
//倒置
println(set.reversed())//[75, -54, 34, -3, 1]
}
输出结果如下:
[-54, -3, 1, 34, 75]
Users升序输出:
User(name=Alex, password=ac133)
User(name=Ben, password=1332%#4)
User(name=Tom, password=23##4)
User(name=Tony, password=12%^3)
[75, 34, 1, -3, -54]
Users降序输出:
User(name=Tony, password=12%^3)
User(name=Tom, password=23##4)
User(name=Ben, password=1332%#4)
User(name=Alex, password=ac133)
[75, -54, 34, -3, 1]
排序函数sorted和sortedDescending要求集合或数组中的元素应该是可比较的,应该实现Comparable接口。而代码第①行和第②行中users集合中的元素user是没有实现Comparable接口,users集合能使用排序函数sorted和sortedDescending进行排序,但是可以使用sortedBy和sortedByDescending函数,自己指定排序规则,进行排序。
注意上述代码中倒置函数reversed,输出的结果并不是排序,而是原始集合或数组元素顺序到倒置,倒置是与降序不同的。
17.8 案例:求阶乘
前面介绍了很多函数,介绍一个实际案例。求阶乘通常会使用递归函数调用,这比较影响性能,学习了函数式编程API,可以使用reduce函数实现。
代码如下:
//代码文件:chapter17/src/com/a51work6/section8/ch17.8.kt
package com.a51work6.section8
//求n的阶乘
fun factorial(n: Int) = IntArray(n) { it + 1 } ①
.reduce {acc, i -> acc * i } ②
fun main(args: Array) {
println(“1! = ${factorial(1)}”) //输出:1! = 1
println(“2! = ${factorial(2)}”) //输出:2! = 1
println(“5! = ${factorial(5)}”) //输出:5! = 120
println(“10! = ${factorial(10)}”) //输出:10! = 3628800
}
上述代码第①行~第②行是声明阶乘函数factorial,采用的是表达式函数体,其中IntArray(n) { it + 1 }是创建元素是1~n的Int类型集合,如果n=5那么,创建的集合为[1,2, 3, 4, 5]。reduce { acc,i -> acc * i }表达式对集合进行累积。
17.9 案例:计算水仙花数
本节再介绍一个案例。计算水仙花数可能一些读者听说过,水仙花数是一个三位数,这个数的三位数各位的立方之和等于三位数本身。
代码如下:
//代码文件:chapter17/src/com/a51work6/section9/ch17.9.kt
package com.a51work6.section9
//计算水仙花
fun main(args: Array) {
val numbers =IntArray(1000) { it }//初始化0~999共计1000个元素Int数组 ①
numbers.filter{ it > 99 } //过滤第一次 ②
.filter{ //过滤第二次 ③
val r = it / 100 //百位数 ④
val s = (it - r * 100) / 10//十位数 ⑤
val t = it - r * 100 - s * 10//个位数 ⑥
it== r * r * r + s * s * s + t * t * t ⑦
}.forEach { println(it) }//遍历打印输出 ⑧
}
输出结果:
153
370
371
407
上述代码第①行是创建Int数组,通过Lambda表达式初始化集合,初始化结果是0999共计1000个元素Int数组。代码第②行第⑧行其实只是一条语句,采用的是函数式编程链式调用风格,其中使用了两次filter函数和一次forEach函数。
代码第②行filter { it > 99 }函数是过滤掉小于100的元素,因为水仙花数是一个三位数,小于100不可能有水仙花数,它们参与计算会影响性能。代码第③行~第⑦行是第二filter函数,代码第④行是元素的百位数,代码第⑤行是元素的十位数,代码第⑥行是元素的个位数,代码第⑦行是否为水仙花数,这个表达式是布尔值,它是Lambda表达式的最后一行,它会作为Lambda表达式的返回值。
本章小结
本章介绍了函数式编程API特点,然后介绍了函数式编程API,其中重点是:forEach、filter、map和reduce函数。此外,还介绍了其他一些API函数。