MapReduce简介,功能,运行原理,job的提交过程,简单的MapReduce程序求最高气温
一.MapRedeuce简介
1.2004年12月,google发布关于MapReduce的文章。
2.hadoop分布式计算框架。
官方定义:MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
二 .MapReduce流程
1.MapReduce的简单执行流程
hdfs数据的读取-->splite 分片--> map阶段(key,value)-->shuffle-->reduce阶段(数据归约)-->存储到hdfs

2.map端处理过程:
hdfs数据的读取-->splite分片--> inputsplite --> key,value --> 调用map方法 --> 按照key分区 --> 分区内排序 --> reduce
3.splite 分片:
mr读取hdfs数据按照片的逻辑划分读取,默认128M,后面根据splitSize大小将file分片。在分片的时候,如果剩余的大小不大于splitSize*1.1,且大于0B的时候,会将该区域整个作为一个分片。这样做是为了防止一个mapper处理的数据太小
设置split
mapreduce.input.fileinputformat.split.maxsize 设置分片最大值 64*1024*1024
mapreduce.input.fileinputformat.split.minsize 设置分片最小值 32*1024*1024
默认设置:分片的最小值1b minSplitSize
分片的最大值Long.MAX_VALUE
那么分片到底是多大呢?
minSize=max{minSplitSize,mapreduce.input.fileinputformat.split.minsize}
maxSize=mapreduce.input.fileinputformat.split.maxsize
splitSize=max{minSize,min{maxSize,blockSize}}
4.shuffle 洗牌(混洗)
1.环形缓冲区:
阈值percent:80%
缓冲区size:100M
2.如果超过80% spill to disk:溢写到磁盘
partition、 sort
combiner:在map端进行的reduce
3.merge:合并
4.reduce端获取map端的输出: 5个线程复制数据
5.reduce端进行merge 和sort
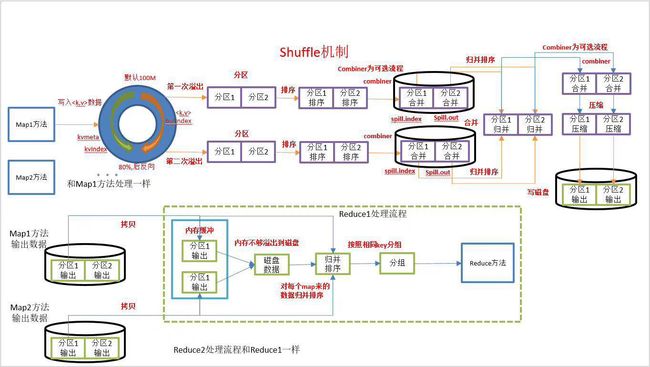
5.Reduce阶段的处理过程
获取map阶段的输出结果 -->合并和排序 --> reduce方法归约处理 --> 保存到hdfs
6.FileInputFormat
1.指定数据源.
2.分片作业记录。
TextInputFormat:默认系统使用TextInputFormat进行的文件按照一行读取。
KeyValueInputFormat:按照行数据key value的方式进行数据的读取
SequenceInputFormat:sequenceFile
二.job作业提交过程
1.从客户端提交一个job作业。
2.job作业从RM申请applicationid。
3.将job作业相关资源长传至共享目录(hdfs tmp) jar包,config配置文件,split文件数据(描述)
4.向RM提交作业。
5.RM指定一个NM 启动Container,启动MRAM。
6.AM进行job的初始化,主要包括TASK任务数及运行占用资源。
7.AM从共享文件中提取分片信息。
8.向RM申请资源。
9.找到指定NM 开启Container。
10.开启YARNCHILD进程,负责Task的执行。
11.MAP或REDUCE任务的执行。

三.简单的mr程序求三年的最高气温
现有如下数据记录了三年的所有气温:

打开格式如下:

1.map端:
package com.ncdc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper {
private static final int MISSING = 999;//清除无效的数据
@Override//重写map方法
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();//读取数据
String year = line.substring(0, 4);// 按照0~4个字符切分
int airTemperature;
airTemperature = Integer.parseInt(line.substring(34, 37).trim());//按照34~37字符切分 去掉前后空格
if (airTemperature != MISSING) {
context.write(new Text(year), new IntWritable(airTemperature));//传给reduce
}
}
} 2.reduce端:
package com.ncdc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer {
@Override//重写reduce方法
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());//获取最高温度
}
context.write(key, new IntWritable(maxValue));//输出
}
} package com.ncdc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxTemperature {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapred.jar","C:/Users/zhangjiaxin/Desktop/Bd1706/Hadoop/max.jar");//程序打成jar包
Job job = Job.getInstance(conf);
job.setJarByClass(MaxTemperature.class);
FileInputFormat.addInputPath(job, new Path("hdfs://master:8020/user/hadoop/ncdc/data"));//输入路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:8020/user/hadoop/res4/"));//输出路径
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}